【高级强化学习综述】层次强化学习、记忆与预测模型
【导读】强化中的许多最大挑战围绕着两个问题:我们如何有效地与环境互动(例如,探索与开发),以及我们如何有效地从经验中学习。 在这篇文章中,探讨了强化学习的最近的研究方向,这些研究试图解决这些挑战,并且与人类认知的特别优雅的相似。 在这篇博客中, 重点介绍了层次强化学习以及记忆与预测模型。
作者|Joyce Xu
编译|专知
整理|Yingying
关于强化学习的一些基础知识可以查看专知以前的推送复习哦~
【专知荟萃23】深度强化学习RL知识资料全集(入门/进阶/论文/综述/代码/专家,附查看)
层次强化学习
层次强化学习从多层策略中学习,每一层都负责在不同的时间和行为抽象层面进行控制。最低级别的策略负责输出行动,使更高级别的策略可以在更抽象的目标和更长的时间尺度上自由运作。
为什么这么吸引人?首先,在认知方面,长期以来,研究人员一直认为人类和动物的行为是由等级结构支撑的。这在日常生活中是直观的:当我决定做饭时,我能够把这个任务简化为更简单子任务:洗菜,切菜,炒菜等,而不忽视我做饭的总体目标;我甚至可以换掉子任务,例如把切菜换成煮饭,完成同样的目标。这表明现实世界任务中固有的层次结构和组合性,其中简单的原子动作可以串联,重复和组合以完成复杂的工作。
层次强化学习可以有效地从经验中学习:长期信用分配和稀疏奖励信号。在层次强化学习中,由于低级策略基于高级策略分配的任务从内在奖励中学习,因此尽管奖励稀少,仍然可以学习原子任务。
实现层次强化学习有许多不同的方法。 Google Brain最近的一篇论文采用了一种特别简洁的方法,并为数据有效训练的引入了一些不错的非策略性修正。他们的模型叫做HIRO。
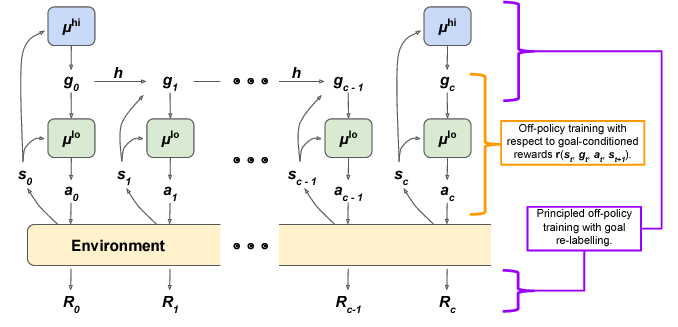
这篇论文的想法是:通过两层策略训练模型。高级策略经过训练,可以最大限度地提高环境奖励R.每隔c个时间步,高级策略会采样一个新的行动,这是低级别策略要达到的“目标状态”。对低级别策略进行训练,以采取环境行动,产生类似于给定目标状态的状态观察。
考虑一个简单的例子:假设我们正在训练机器人以某种顺序堆叠彩色立方体。如果任务成功完成,我们最终只获得+1的单一奖励,并且在所有其他时间步骤中奖励为0。直观地说,高级策略负责提出必要的子目标:也许它输出的第一个目标状态是“在你面前观察一个红色立方体;”下一个可能是“观察蓝色立方体在红色立方体旁边;“然后”观察红色立方体顶部的蓝色立方体。“低层策略在环境中徘徊,直到它产生了产生这些观察所需的一系列行动,例如:拿起蓝色立方体并将其移到红色立方体之上。
HIRO使用DDPG(深度确定性策略梯度)训练目标的变体来训练低级别策略,其内在奖励被参数化为当前观察与目标观察之间的距离:
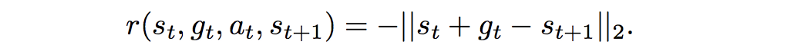
DDPG是另一种开创性的深度强化学习算法,它将想法从深度Q网络扩展到连续的动作空间。 它是另一种使用策略梯度来优化策略的行动者 - 评论家方法,但不是像A3C那样优化它,而是根据Q值对其进行优化。 因此,在HIRO中,最小化的DDPG相邻误差变为:
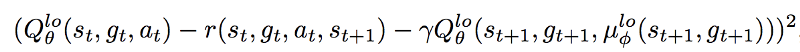
同时,为了使用非策略性经验,高级别策略接受了策略外修正的训练。 这里的想法是:为了提高样本效率,我们希望使用某种形式的重放缓冲区,如DQN。 但是,旧的经验不能直接用于训练高层策略。 这是因为低级策略不断学习和改变,所以即使条件与过去的经验相同,低级策略现在也可能表现出不同的行动/转变。 HIRO中提出的策略外纠正是追溯性地改变在策略外体验中看到的目标,以最大化观察到的行动顺序的可能性。
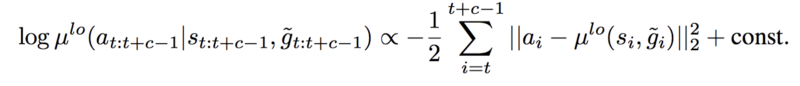
然后使用DDPG变体对高级策略进行训练,包括这些动作,新目标和环境奖励R.
HIRO当然不是层次强化学习的唯一方法。 FeUdal网络是一个较早的相关工作,使用学习的“目标”表示而不是原始状态观察。实际上,研究的很多变化源于学习有用的低级别子策略的不同方式;许多论文使用辅助或“代理”奖励。与HIRO不同,许多这些方法需要一定程度的手工特征工程或领域知识,这本身就限制了普遍性。另一个最近探索过的选择是使用基于人口的训练(PBT),这是我个人的另一种算法。本质上,内部奖励被视为额外的超参数,PBT在训练期间学习这些超参数在“不断发展”的人群中的最佳演化。
层次强化学习目前是一个非常受欢迎的研究领域,并且很容易用其他技术进行插值。然而,它的核心只是一个非常直观的想法。它具有可扩展性,具有神经解剖学上的相似性,并解决了强化学习中的一系列基本问题。和其他好的强化学习一样,训练也很棘手。
记忆和注意力
现在让我们谈谈解决长期信用分配和稀疏奖励信号问题的其他方法。具体来说,让我们谈谈最明显的方式:让代理人真正善于记忆。
深度学习中的记忆总是很有趣,很少有架构能够击败经过良好调参的LSTM。然而,人类记忆并不像LSTM那样起作用;当我们在日常生活中处理任务时,我们会回想起并关注特定的,依赖于环境的记忆,而不是其他。当我回到家里开车去当地的杂货店时,我正在使用过去数百次的记忆,而不是最近发生的一些新鲜事。从这个意义上说,我们的记忆几乎可以通过语境来查询:取决于我在哪里以及我在做什么,我的大脑知道哪些记忆对我有用。
在深度学习中,这是外部基于键值的内存存储的驱动论点。在任何给定的时间步长,代理被给予其环境观察和与其当前状态相关的记忆。这正是最近的ME强化学习IN架构所延伸的。
MERLIN 有两个组件:基于内存的预测器(MBP)和策略网络。 MBP负责将观察值压缩为有用的低维“状态变量”,以直接存储到键值存储矩阵中。它还负责将相关记忆传递给策略,该策略使用那些记忆和当前状态来输出动作。
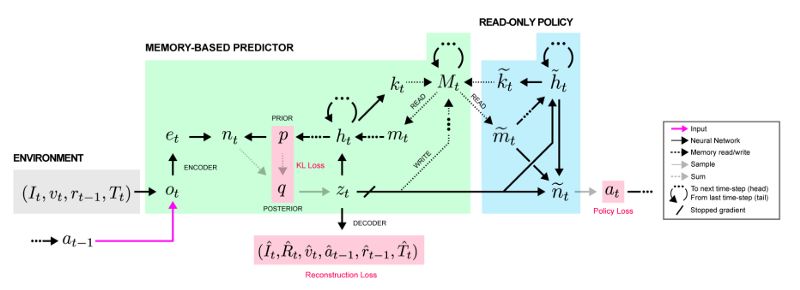
这种架构可能看起来有点复杂,但请记住,策略只是一种网络输出,而MBP只是做了三件事:
将观察压缩为有用的状态变量z_t以传递给策略,
将z_t写入存储矩阵
获取其他有用的记忆以传递给策略。
过程是这样的:输入观察首先被编码然后通过MLP传送,MLP的输出被添加到下一个状态变量的先前分布以产生后验分布。然后对该后验分布进行采样,该后验分布以所有先前的动作/观察以及该新观察为条件,以产生状态变量z_t。接下来,z_t被送入MBP的LSTM,其输出用于更新先前,并通过向量值“读取密钥”和“写入密钥”从存储器读取/写入 - 两者都作为线性函数生成LSTM的隐藏状态。最后,在下游,策略网利用内存中的z_t和读取输出来产生一个动作。
关键细节是,为了确保状态表示是有用的,MBP还被训练以预测来自当前状态z_t的奖励,因此学习的表示与手头的任务相关。
MERLIN 的训练有点复杂;由于MBP旨在作为一个有用的“世界模型”,一个难以处理的目标,它被训练以优化变分下界(VLB)损失。 (如果您不熟悉VLB,我发现这篇文章非常有用,但您真的不需要它来理解MERLIN )。这种VLB损失有两个组成部分:
在该下一个状态变量上的先验概率分布和后验概率分布之间的KL-分歧,其中后验另外以新观察为条件。最小化此KL可确保此新状态变量与先前的观察/操作一致。状态变量的重建损失,其中我们尝试再现输入观察(例如图像,先前动作等)并基于状态变量预测奖励。如果这种损失很小,我们发现了一个状态变量,它是观察的准确表示,对于产生高回报的行为很有用。这是我们最终的VLB损失,第一项是重建,第二项是KL分歧:
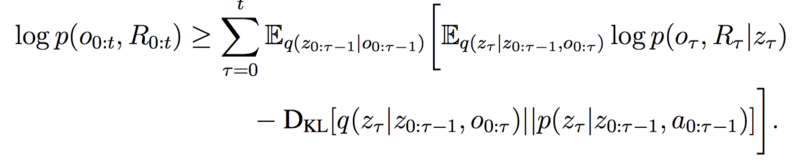
策略网络使用一种称为广义优势估计算法的算法,其详细信息超出了本文的范围(但可以在MERLIN 论文附录的第4.4节中找到),但它看起来类似于下面显示的标准策略梯度更新:
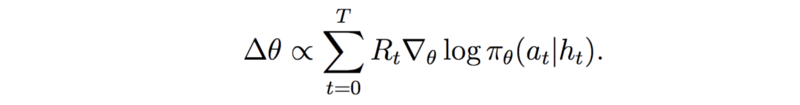
一旦经过训练,ME强化学习IN应该能够通过状态表示和记忆预测性地模拟世界,其策略应该能够利用这些预测来采取有用的行动。
MERLIN 并不是唯一使用外部存储器的强化学习工作 - 一直到2016年,研究人员已经在MQN或记忆Q网络中应用这个想法来解决Minecraft中的迷宫 - 但这种使用内存的概念世界的预测模型具有一些独特的神经科学牵引力。神经科学家Amil Seth很好地总结了Hermann von Helmholtz在19世纪的理论:
大脑被锁在一块骨头里。它所接收的只是模糊和嘈杂的感觉信号,它们只与世界上的物体间接相关。因此,感知必须是一个推理过程,其中不确定的感觉信号与先前的期望或关于世界方式的“信念”相结合,以形成大脑对这些感觉信号的原因的最佳假设。
MERLIN 基于记忆的预测器旨在实现预测推理的这一目的。它对观察结果进行编码,并将它们与内部先验结合起来,生成一个“状态变量”,捕获输入的某些表示或原因,并将这些状态存储在长期记忆中,以便代理可以在以后对其进行操作。
小结
深度强化学习模型真的很难训练。但是由于这种困难,我们不得不提出一系列令人难以置信的策略,方法和算法,以利用深度学习的力量来解决经典(和一些非经典)控制问题。
原文链接:
https://towardsdatascience.com/advanced-reinforcement-learning-6d769f529eb3
-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



