华为诺亚方舟预训练语言模型NEZHA、TinyBERT开源代码
【导读】预训练语言模型对自然语言处理领域产生了非常大的影响,华为诺亚方舟实验首席科学家刘群,前不久在AICon全球人工智能与机器学习技术大会上,分享了华为诺亚方舟实验室在预训练语言模型研究与应用。最近就在github上开源了中文预训练模型NEZHA与高效的BERT压缩模型TinyBERT。
github链接:
https://github.com/huawei-noah/Pretrained-Language-Model
NEZHA:诺亚方舟实验室的中文预训练语言模型
首先,在华为内部服务器上重现了Google BERT-base和BERT-large的实验
在华为云上训练和运行成功
中文预训练模型包括:Wikipedia+Baike+News
训练与优化
基于华为云
多卡多机的数据并行
混合精读训练
LAMB优化器
模型改进
函数式相对位置编码
全词覆盖
高效的BERT压缩模型:TinyBERT
BERT性能强大,但不便于部署到算力、内存有限的设备上
提出一种专为Transformer模型设计的知识蒸馏方法,以BERT 作为老师蒸馏出一个小模型—TinyBERT
TinyBERT参数量为 BERT 的 1/7,预测速度是 BERT 的 9 倍, 在GLUE评测上相比BERT下降3个百分点
TinyBERT蒸馏:预训练蒸馏+下游任务蒸馏+数据增强
相关工作
Google新推出ALBERT模型
主要改进:
- Factorized embedding parameterization
- Cross-layer parameter sharing
优点:
- 大幅度减少模型参数,并加快训练速度
- 通过加深模型,可以在参数减少的情况下获得更好的性能
缺点:
- 模型如果不加深性能会有较多的下降
- 模型加深后推理时间增加了
- Inter-sentence coherence loss
开源代码
NEZHA
NEZHA是当前基于华为诺亚方舟实验室开发的BERT的中文预训练语言模型。
请注意,此代码用于在普通GPU集群上训练NEZHA,与我们训练华为云提供的NEZHA ModelArts所使用的代码不同。
为了方便重现我们的结果,此代码是在NVIDIA代码和Google代码的早期版本的基础上进行了修订,并整合了我们采用的所有技术。
预训练过程
准备数据的方法与BERT的过程类似:
python utils/create_pretraining_data.py \--input_file=./sample_text.txt \--output_file=/tmp/tf_examples.tfrecord \--vocab_file=./your/path/vocab.txt \--do_lower_case=True \--max_seq_length=128 \--max_predictions_per_seq=20 \--masked_lm_prob=0.15 \--random_seed=12345 \--dupe_factor=5
微调过程
目前,NEZHA支持三种微调任务:文本分类,序列标记和类似SQuAD的机器阅读理解。微调的代码主要基于Google BERT,BERT NER,CMRC2018-DRCD-BERT,在NEZHA/中下载预训练模型并解压模型文件、词汇文件和配置文件。
微调过程如下:
scripts / run_clf.sh用于文本分类任务,例如LCQMC,ChnSenti,XNLI。
scripts / runseqlabelling.sh用于序列标记任务,例如Peoples-daily-NER
scripts / run_reading.sh用于类似SQuAD的机器阅读理解任务,例如CMRC2018
https://github.com/ymcui/cmrc2018
需要注意的是,CMRC任务评估有些不同, 因此需要单独运行此脚本:
python cmrc2018_evaluate.py data/cmrc/cmrc2018_dev.json output/cmrc/dev_predictions.json output/cmrc/metric.txt.已有4种中文与训练模型可以下载:bert-base,bert-large,WWM,Whole Word Masking
TinyBERT
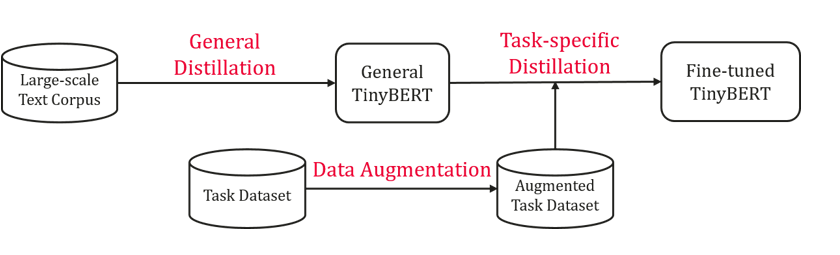
TinyBERT比BERT的小7.5倍,速度快9.4倍,并且在自然语言处理任务中具有竞争优势。它在预训练和任务特定的学习阶段都进行了变压器蒸馏。TinyBERT学习的概述如下所示:
安装方法
依赖于Python3中的部分库:
pip install -r requirements.txt使用方法
TinyBERT的使用过程分为以下三个步骤:蒸馏、数据增强以及特定任务蒸馏。接下来将会对每个步骤进行详细的介绍:
1、蒸馏
在泛化蒸馏中,使用原始而不进行微调的BERT库作为老师模型,并使用大型文本语料库作为学习数据。通过对通用域中的文本执行Transformer蒸馏,就可以获得了泛化的TinyBERT,它为特定任务的蒸馏提供了良好的初始化。
泛化蒸馏有两个步骤:(1)生成json格式的语料库;(2)进行蒸馏。
step1:使用pregeneratetrainingdata.py生成语料
# ${BERT_BASE_DIR}$ includes the BERT-base teacher model.
python pregenerate_training_data.py --train_corpus ${CORPUS_RAW} \--bert_model ${BERT_BASE_DIR}$ \--reduce_memory --do_lower_case \--epochs_to_generate 3 \--output_dir ${CORPUS_JSON_DIR}$
step2:使用general_distill.py进行蒸馏
# ${STUDENT_CONFIG_DIR}$ includes the config file of student_model.
python general_distill.py --pregenerated_data ${CORPUS_JSON}$ \--teacher_model ${BERT_BASE}$ \--student_model ${STUDENT_CONFIG_DIR}$ \--reduce_memory --do_lower_case \--train_batch_size 256 \--output_dir ${GENERAL_TINYBERT_DIR}$
【模型下载】
开源项目中提供了已经蒸馏的TinyBERT模型:
General_TinyBERT(4layer-312dim):
https://drive.google.com/uc?export=download&id=1dDigD7QBv1BmE6pWU71pFYPgovvEqOOj
General_TinyBERT(6layer-768dim):
https://drive.google.com/uc?export=download&id=1wXWR00EHK-Eb7pbyw0VP234i2JTnjJ-x
GeneralTinyBERTv2(4layer-312dim):
https://drive.google.com/open?id=1PhI73thKoLU2iliasJmlQXBav3v33-8z
GeneralTinyBERTv2(6layer-768dim):
https://drive.google.com/open?id=1r2bmEsQe4jUBrzJknnNaBJQDgiRKmQjF
2、数据增强
数据增强是为了扩展特定任务的训练集。,学习更多与任务相关的示例,可以进一步提高模型的泛化能力。项目中结合了预训练的语言模型BERT和GloVe嵌入来进行词级别替换,以此进行增强数据。
具体使用dataaugmentation.py进行数据增强,增强后的数据集trainaug.tsv自动保存在对应的${GLUE_DIR/TASK_NAME}$中。
python data_augmentation.py --pretrained_bert_model ${BERT_BASE_DIR}$ \--glove_embs ${GLOVE_EMB}$ \--glue_dir ${GLUE_DIR}$ \--task_name ${TASK_NAME}$
需要注意的是:在运行GLUE任务的数据增强之前,需要通过运行此脚本下载GLUE数据并将其解压缩到GLUEDIR目录。命令中的TASKNAME可以是CoLA,SST-2,MRPC,STS-B,QQP,MNLI,QNLI,RTE中的任意一个。
3、特定任务蒸馏
在特定任务的蒸馏中,主要对transformer进行蒸馏,以进一步改善TinyBERT。特定任务的蒸馏包括两个步骤:(1)中间层蒸馏;(2)预测层蒸馏。
step1:运行task_distill.py进行中间层蒸馏
# ${FT_BERT_BASE_DIR}$ contains the fine-tuned BERT-base model.python task_distill.py --teacher_model ${FT_BERT_BASE_DIR}$ \--student_model ${GENERAL_TINYBERT_DIR}$ \--data_dir ${TASK_DIR}$ \--task_name ${TASK_NAME}$ \--output_dir ${TMP_TINYBERT_DIR}$ \--max_seq_length 128 \--train_batch_size 32 \--num_train_epochs 10 \--aug_train \--do_lower_case
step2:运行task_distill.py进行预测层蒸馏
python task_distill.py --pred_distill \--teacher_model ${FT_BERT_BASE_DIR}$ \--student_model ${TMP_TINYBERT_DIR}$ \--data_dir ${TASK_DIR}$ \--task_name ${TASK_NAME}$ \--output_dir ${TINYBERT_DIR}$ \--aug_train \--do_lower_case \--learning_rate 3e-5 \--num_train_epochs 3 \--eval_step 100 \--max_seq_length 128 \--train_batch_size 32
【模型下载】
项目中提供了所有GLUE任务中的蒸馏TinyBERT:
TinyBERT(4layer-312dim):
https://drive.google.com/uc?export=download&id=1_sCARNCgOZZFiWTSgNbE7viW_G5vIXYg
TinyBERT(6layer-768dim):
https://drive.google.com/uc?export=download&id=1Vf0ZnMhtZFUE0XoD3hTXc6QtHwKr_PwS
模型性能评估
运行task_distill.py进行性能评估
${TINYBERT_DIR}$ includes the config file, student model and vocab file.python task_distill.py --do_eval \--student_model ${TINYBERT_DIR}$ \--data_dir ${TASK_DIR}$ \--task_name ${TASK_NAME}$ \--output_dir ${OUTPUT_DIR}$ \--do_lower_case \--eval_batch_size 32 \--max_seq_length 128
-END-



展开全文



