【论文推荐】最新九篇自动问答相关论文—可解释推理网络、上下文知识图谱嵌入、注意力RNN、Multi-Cast注意力网络
【导读】专知内容组推出九篇自动问答(Question Answering)相关论文,欢迎查看!
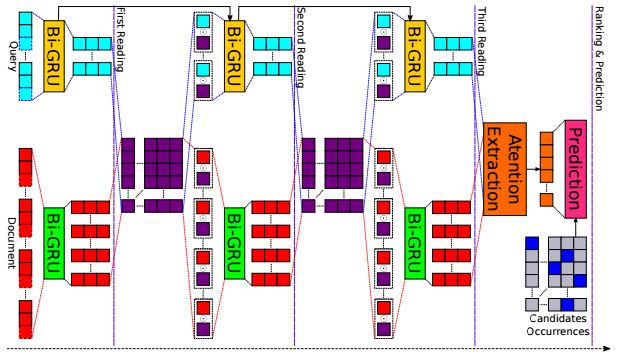
1.Dependent Gated Reading for Cloze-Style Question Answering
作者:Reza Ghaeini,Xiaoli Z. Fern,Hamed Shahbazi,Prasad Tadepalli
Accepted as a long paper at COLING 2018
机构:Oregon State University
摘要:We present a novel deep learning architecture to address the cloze-style question answering task. Existing approaches employ reading mechanisms that do not fully exploit the interdependency between the document and the query. In this paper, we propose a novel \emph{dependent gated reading} bidirectional GRU network (DGR) to efficiently model the relationship between the document and the query during encoding and decision making. Our evaluation shows that DGR obtains highly competitive performance on well-known machine comprehension benchmarks such as the Children's Book Test (CBT-NE and CBT-CN) and Who DiD What (WDW, Strict and Relaxed). Finally, we extensively analyze and validate our model by ablation and attention studies.
期刊:arXiv, 2018年6月2日
网址:
http://www.zhuanzhi.ai/document/dc6aa13de185f5e43fbafe0ac09c7b0c
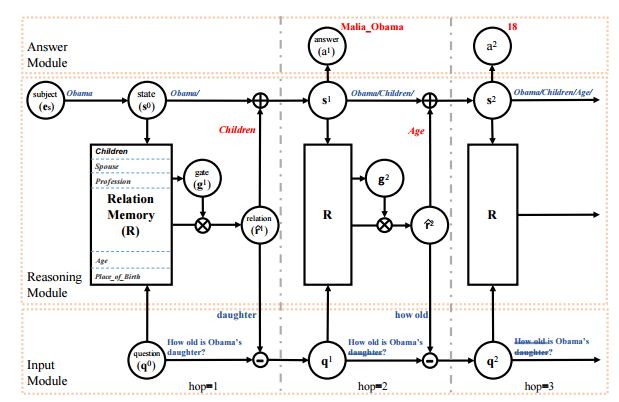
2.An Interpretable Reasoning Network for Multi-Relation Question Answering(可解释推理网络的多关系问答)
作者:Mantong Zhou,Minlie Huang,Xiaoyan Zhu
机构:Tsinghua University
摘要:Multi-relation Question Answering is a challenging task, due to the requirement of elaborated analysis on questions and reasoning over multiple fact triples in knowledge base. In this paper, we present a novel model called Interpretable Reasoning Network that employs an interpretable, hop-by-hop reasoning process for question answering. The model dynamically decides which part of an input question should be analyzed at each hop; predicts a relation that corresponds to the current parsed results; utilizes the predicted relation to update the question representation and the state of the reasoning process; and then drives the next-hop reasoning. Experiments show that our model yields state-of-the-art results on two datasets. More interestingly, the model can offer traceable and observable intermediate predictions for reasoning analysis and failure diagnosis, thereby allowing manual manipulation in predicting the final answer.
期刊:arXiv, 2018年6月1日
网址:
http://www.zhuanzhi.ai/document/807ee8d54682d9356a8eb8b408a1a7d6
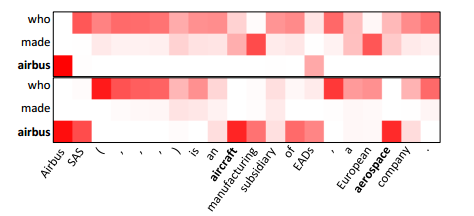
3.Question Answering through Transfer Learning from Large Fine-grained Supervision Data(通过从大规模细粒度监督数据中学习来进行问答学习)
作者:Sewon Min,Minjoon Seo,Hannaneh Hajishirzi
ACL 2017 (short paper).
机构:Seoul National University,University of Washington
摘要:We show that the task of question answering (QA) can significantly benefit from the transfer learning of models trained on a different large, fine-grained QA dataset. We achieve the state of the art in two well-studied QA datasets, WikiQA and SemEval-2016 (Task 3A), through a basic transfer learning technique from SQuAD. For WikiQA, our model outperforms the previous best model by more than 8%. We demonstrate that finer supervision provides better guidance for learning lexical and syntactic information than coarser supervision, through quantitative results and visual analysis. We also show that a similar transfer learning procedure achieves the state of the art on an entailment task.
期刊:arXiv, 2018年6月1日
网址:
http://www.zhuanzhi.ai/document/4df53fa0fe776a1879fb5fd340bb64a9
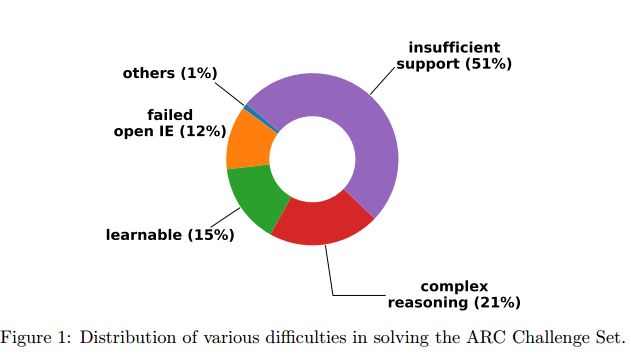
4.KG^2: Learning to Reason Science Exam Questions with Contextual Knowledge Graph Embeddings(KG^2: 学习用上下文知识图谱嵌入来推理科学试题)
作者:Yuyu Zhang,Hanjun Dai,Kamil Toraman,Le Song
摘要:The AI2 Reasoning Challenge (ARC), a new benchmark dataset for question answering (QA) has been recently released. ARC only contains natural science questions authored for human exams, which are hard to answer and require advanced logic reasoning. On the ARC Challenge Set, existing state-of-the-art QA systems fail to significantly outperform random baseline, reflecting the difficult nature of this task. In this paper, we propose a novel framework for answering science exam questions, which mimics human solving process in an open-book exam. To address the reasoning challenge, we construct contextual knowledge graphs respectively for the question itself and supporting sentences. Our model learns to reason with neural embeddings of both knowledge graphs. Experiments on the ARC Challenge Set show that our model outperforms the previous state-of-the-art QA systems.
期刊:arXiv, 2018年5月31日
网址:
http://www.zhuanzhi.ai/document/d262356f874b05f67652725423e943a8
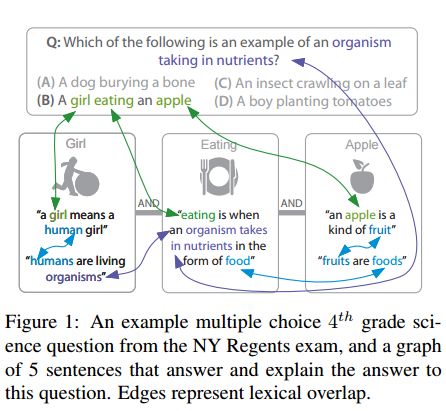
5.Multi-hop Inference for Sentence-level TextGraphs: How Challenging is Meaningfully Combining Information for Science Question Answering?(句子级文本图谱的Multi-hop推理)
作者:Peter Jansen
Accepted to TextGraphs 2018
机构:University of Arizona
摘要:Question Answering for complex questions is often modeled as a graph construction or traversal task, where a solver must build or traverse a graph of facts that answer and explain a given question. This "multi-hop" inference has been shown to be extremely challenging, with few models able to aggregate more than two facts before being overwhelmed by "semantic drift", or the tendency for long chains of facts to quickly drift off topic. This is a major barrier to current inference models, as even elementary science questions require an average of 4 to 6 facts to answer and explain. In this work we empirically characterize the difficulty of building or traversing a graph of sentences connected by lexical overlap, by evaluating chance sentence aggregation quality through 9,784 manually-annotated judgments across knowledge graphs built from three free-text corpora (including study guides and Simple Wikipedia). We demonstrate semantic drift tends to be high and aggregation quality low, at between 0.04% and 3%, and highlight scenarios that maximize the likelihood of meaningfully combining information.
期刊:arXiv, 2018年5月29日
网址:
http://www.zhuanzhi.ai/document/640ce925d6f6f0e0aa4beae326c5e56d
6.Question Answering over Freebase via Attentive RNN with Similarity Matrix based CNN
作者:Yingqi Qu,Jie Liu,Liangyi Kang,Qinfeng Shi,Dan Ye
摘要:With the rapid growth of knowledge bases (KBs), question answering over knowledge base, a.k.a. KBQA has drawn huge attention in recent years. Most of the existing KBQA methods follow so called encoder-compare framework. They map the question and the KB facts to a common embedding space, in which the similarity between the question vector and the fact vectors can be conveniently computed. This, however, inevitably loses original words interaction information. To preserve more original information, we propose an attentive recurrent neural network with similarity matrix based convolutional neural network (AR-SMCNN) model, which is able to capture comprehensive hierarchical information utilizing the advantages of both RNN and CNN. We use RNN to capture semantic-level correlation by its sequential modeling nature, and use an attention mechanism to keep track of the entities and relations simultaneously. Meanwhile, we use a similarity matrix based CNN with two-directions pooling to extract literal-level words interaction matching utilizing CNNs strength of modeling spatial correlation among data. Moreover, we have developed a new heuristic extension method for entity detection, which significantly decreases the effect of noise. Our method has outperformed the state-of-the-arts on SimpleQuestion benchmark in both accuracy and efficiency.
期刊:arXiv, 2018年5月27日
网址:
http://www.zhuanzhi.ai/document/5f6b1dc07f1683f8aa67485fd51229ce
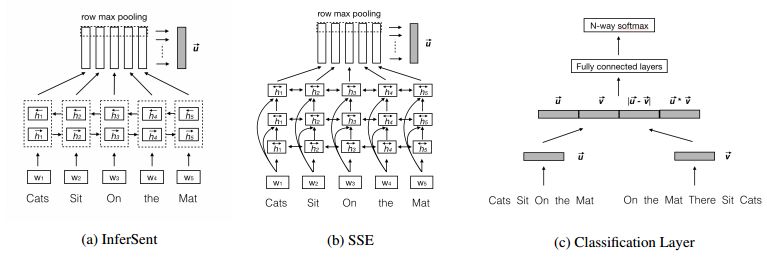
7.Neural Network Models for Paraphrase Identification, Semantic Textual Similarity, Natural Language Inference, and Question Answering(用于释义识别、语义语篇相似性、自然语言推理和问答的神经网络模型)
作者:Wuwei Lan,Wei Xu
accepted to COLING 2018
机构:Ohio State University
摘要:In this paper, we analyze several neural network designs (and their variations) for sentence pair modeling and compare their performance extensively across eight datasets, including paraphrase identification, semantic textual similarity, natural language inference, and question answering tasks. Although most of these models have claimed state-of-the-art performance, the original papers often reported on only one or two selected datasets. We provide a systematic study and show that (i) encoding contextual information by LSTM and inter-sentence interactions are critical, (ii) Tree-LSTM does not help as much as previously claimed but surprisingly improves performance on Twitter datasets, (iii) the Enhanced Sequential Inference Model is the best so far for larger datasets, while the Pairwise Word Interaction Model achieves the best performance when less data is available. We release our implementations as an open-source toolkit.
期刊:arXiv, 2018年6月12日
网址:
http://www.zhuanzhi.ai/document/4a3ff7c8308a005f616622b015c43418
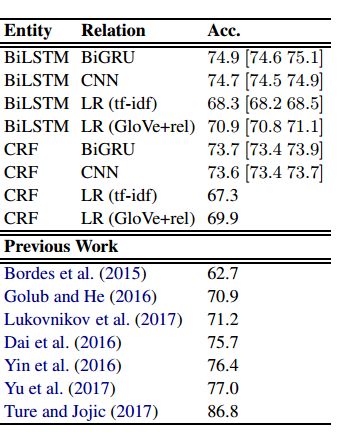
8.Strong Baselines for Simple Question Answering over Knowledge Graphs with and without Neural Networks
作者:Salman Mohammed,Peng Shi,Jimmy Lin
Published in NAACL HLT 2018
机构:University of Waterloo
摘要:We examine the problem of question answering over knowledge graphs, focusing on simple questions that can be answered by the lookup of a single fact. Adopting a straightforward decomposition of the problem into entity detection, entity linking, relation prediction, and evidence combination, we explore simple yet strong baselines. On the popular SimpleQuestions dataset, we find that basic LSTMs and GRUs plus a few heuristics yield accuracies that approach the state of the art, and techniques that do not use neural networks also perform reasonably well. These results show that gains from sophisticated deep learning techniques proposed in the literature are quite modest and that some previous models exhibit unnecessary complexity.
期刊:arXiv, 2018年6月6日
网址:
http://www.zhuanzhi.ai/document/f53b87b183392331888d792b1fd64fb7
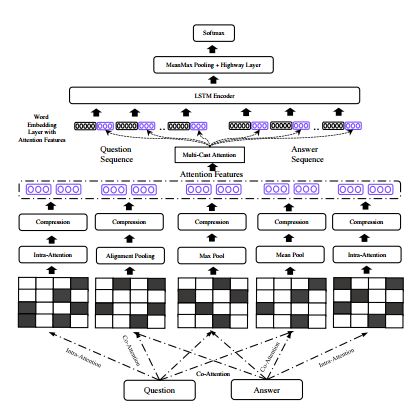
9.Multi-Cast Attention Networks for Retrieval-based Question Answering and Response Prediction(基于Multi-Cast注意力网络的检索问答和响应预测)
作者:Yi Tay,Luu Anh Tuan,Siu Cheung Hui
Accepted to KDD 2018
机构:Nanyang Technological University
摘要:Attention is typically used to select informative sub-phrases that are used for prediction. This paper investigates the novel use of attention as a form of feature augmentation, i.e, casted attention. We propose Multi-Cast Attention Networks (MCAN), a new attention mechanism and general model architecture for a potpourri of ranking tasks in the conversational modeling and question answering domains. Our approach performs a series of soft attention operations, each time casting a scalar feature upon the inner word embeddings. The key idea is to provide a real-valued hint (feature) to a subsequent encoder layer and is targeted at improving the representation learning process. There are several advantages to this design, e.g., it allows an arbitrary number of attention mechanisms to be casted, allowing for multiple attention types (e.g., co-attention, intra-attention) and attention variants (e.g., alignment-pooling, max-pooling, mean-pooling) to be executed simultaneously. This not only eliminates the costly need to tune the nature of the co-attention layer, but also provides greater extents of explainability to practitioners. Via extensive experiments on four well-known benchmark datasets, we show that MCAN achieves state-of-the-art performance. On the Ubuntu Dialogue Corpus, MCAN outperforms existing state-of-the-art models by $9\%$. MCAN also achieves the best performing score to date on the well-studied TrecQA dataset.
期刊:arXiv, 2018年6月3日
网址:
http://www.zhuanzhi.ai/document/5def5c404372dce53766c9ce4e4e6ea2
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



