【导读】推理能力是智力的标志,也是建立问答系统的要求。在人工智能研究中,推理一直与逻辑和符号操作密切相关。但对于人类来说,推理不仅涉及符号和逻辑,还涉及图像和形状。科学史充满了由于视觉思维的发现,从苯环到DNA结构,都体现了视觉想象带来的创造力。还有大量的人类视觉思维的例子。考虑一个方形的房间,其中南墙的中间有一扇门。假设你站在房间里,房间的东墙就在你的后面。门相对于你在哪?答案是“左”。请注意,在这种情况下,问题和答案都只是文本。但为了回答这个问题,自然而然地建立一个房间的虚拟图像并在推理过程中使用它。
【ACL 2018 论文】
Think Visually: Question Answering through Virtual Imagery.
Ankit Goyal, Jian Wang and Jia Deng.
这篇ACL2018的文章研究了在文本问题回答中视觉推理的问题。 作者引入了一种新的深层网络结构:动态空间记忆网络(Dynamic Spatial Memory Networks, DSMN),用于回答具有潜在视觉表示的问题,并学习如何生成和推理这些表示。 此外,作者还提出两个综合基准HouseQA和ShapeInstitute,以评估文本QA系统的视觉推理能力。 实验结果验证了模型的有效性。
简介
在本文中,作者研究如何使用深度网络对视觉推理过程进行建模。特别是,作者通过视觉推理来回答文本问题 - 问题和答案都在文本(或一般符号)中,但是回答问题需要想象一定的空间并进行推理。 作者提出了动态空间记忆网络(DSMN),这是一种新型深层架构。 DSMN与现有的记忆网络类似,它用向量表示问题和记忆模块,然后来执行推理。 DSMN的主要新颖之处在于它为输入问题创建虚拟图像并使用空间记忆来帮助推理处理。DSMN是第一个“视觉推理”来回答文本问题的深层架构。在为文本问答开发的深度神经网络中,视觉表示和空间记忆的使用对DSMN来说是独一无二的。
数据集
为了评估模型的视觉推理的能力,我们介绍了两个数据集,HouseQA和ShapeIntersection。
HouseQA数据集
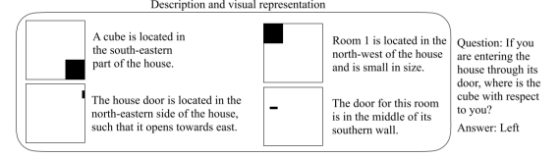
House QA 数据集假设了这样一个场景,你进入一个带三间房间的屋子,并且有门,长方体,球体等物件,数据集给定关于这些物件的描述,和一个问题,问题的格式为:当你进入{房子,房间1,房间2,房间3},{大门,房门1,房门2,房门3,长方体,球体在你的什么位置},回答的格式为前后左右四个选项。如下图所示。
ShapeIntersection数据集
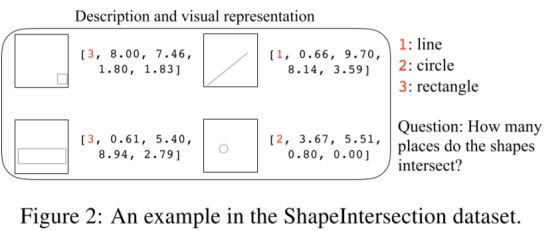
ShapeIntersection 数据集给定三种形状: 线段,圆,长方形,和它们的大小和位置,求一个问题:在图中的形状有多少个相交的点。因此,由于位置和大小可以用数字表示,形状也可以用数字表示,因此,数据的描述本身就是一组向量。
模型
模型主要分为5个部分
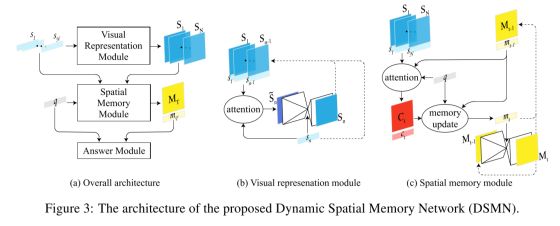
输入模块
输入模块是将每个描述的句子生成一个向量表示。
针对HouseQA,输入的描述是一句自然语言,所以用输入的word embedding来生成初始的句子的embedding。
针对ShapeIntersection,输入本身就是一组向量,因此用 一个全连接层对输入的描述进行处理。
问题模块
问题模块处理了需要系统回答的问题,也是将用自然语言提出的问题变成用向量表示。
针对HouseQA,将问题中的每个词输入循环神经网络GRU,然后最终的输出作为问题的Embedding。
针对ShapeIntersection,所有的问题都是一样的,因此,用用一个零向量表示该问题。
视觉表示模块
视觉模块的作用是将每一句描述,依次变成一个视觉的表示。主要用注意力网络和编码-解码两部分组成。注意力网络计算了之前的视觉表示与当前句子之间的关联程度,作为Attention。然后利用前几步的视觉表示、Attention和当前句子,作为编码器的输入,得到一个隐表示,再从隐表示中解码出当前句子的视觉表示。
空间记忆模块
空间记忆模块从描述中获得信息,并且根据获得的信息更新记忆。记忆由两部分构成:二维空间记忆和一个标记向量。二维空间记忆是指网络如何描述空间,比如房间1的位置,而标记向量则说明描述了哪个物体,比如房间1。
在生成空间记忆时,同样先计算第i个句子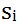
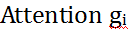
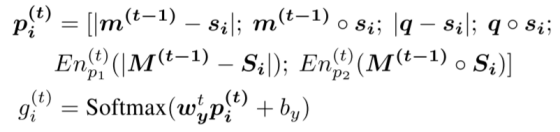
然后计算第t时刻的二维空间记忆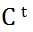
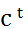
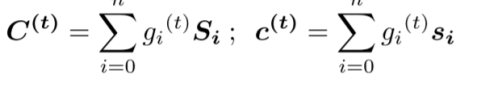
回答模块
使用最终的记忆(二维空间记忆和标记)和问题的向量的向量表示,作为回答的特征生成回答。由于回答只有四个选项,所以最终结果的生成并不复杂。
实验结果
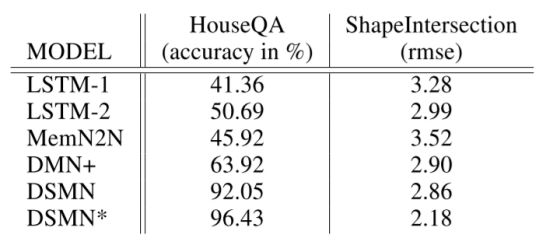
其中DSMN代表没有监督信息的,DSMN*代表有监督信息的,可以看出,DSMN模型整体上都好于LSTM模型和之前的LSTM和DMN+模型,而DSMN*的效果更好。
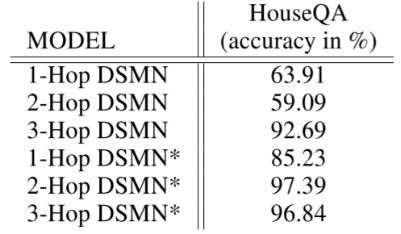
DSMN在3-hop时表现得最好,但DSMN*在2-hop是就有了较好的表现。
下面是一个展示Attention在实际的例子的表现。当问到关于“cylinder”时,有监督信息的DSMN* 直接将注意力放在了第六句话,然后在第二轮就完成了推理。而DSMN(没有额外的视觉监督信息)在第一轮中表现地并不是很好,它首先试着找出cylinder所在房间的位置(句5),然后在寻找cylinder在房间中的位置(句6),最后才定位房门的位置(句2)。

参考链接:
https://openreview.net/forum?id=B1vOZ8ylG
更多教程资料请访问:专知AI会员计划
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



