【论文推荐】最新七篇推荐系统相关论文—正则化奇异值、用户视角、CTR预测、Top-k、人机交互、隐反馈
【导读】既昨天推出六篇推荐系统(Recommended System)相关,专知内容组今天又推出最近七篇推荐系统相关文章,为大家进行介绍,欢迎查看!
1. Regularized Singular Value Decomposition and Application to Recommender System(正则化奇异值分解和其在推荐系统的应用)
作者:Shuai Zheng,Chris Ding,Feiping Nie
机构:University of Texas at Arlington
摘要:Singular value decomposition (SVD) is the mathematical basis of principal component analysis (PCA). Together, SVD and PCA are one of the most widely used mathematical formalism/decomposition in machine learning, data mining, pattern recognition, artificial intelligence, computer vision, signal processing, etc. In recent applications, regularization becomes an increasing trend. In this paper, we present a regularized SVD (RSVD), present an efficient computational algorithm, and provide several theoretical analysis. We show that although RSVD is non-convex, it has a closed-form global optimal solution. Finally, we apply RSVD to the application of recommender system and experimental result show that RSVD outperforms SVD significantly.
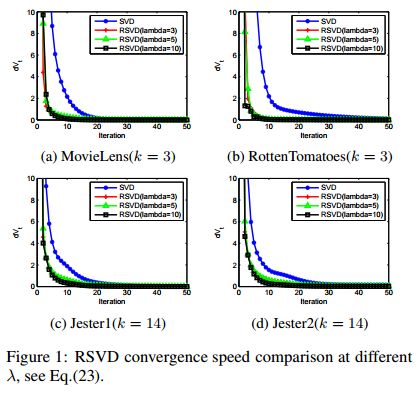
期刊:arXiv, 2018年4月14日
网址:
http://www.zhuanzhi.ai/document/a44c781b373671488e074d59d45b0334
2. The Users' Perspective on the Privacy-Utility Trade-offs in Health Recommender Systems
作者:André Calero Valdez,Martina Ziefle
机构:Aachen University
摘要:Privacy is a major good for users of personalized services such as recommender systems. When applied to the field of health informatics, privacy concerns of users may be amplified, but the possible utility of such services is also high. Despite availability of technologies such as k-anonymity, differential privacy, privacy-aware recommendation, and personalized privacy trade-offs, little research has been conducted on the users' willingness to share health data for usage in such systems. In two conjoint-decision studies (sample size n=521), we investigate importance and utility of privacy-preserving techniques related to sharing of personal health data for k-anonymity and differential privacy. Users were asked to pick a preferred sharing scenario depending on the recipient of the data, the benefit of sharing data, the type of data, and the parameterized privacy. Users disagreed with sharing data for commercial purposes regarding mental illnesses and with high de-anonymization risks but showed little concern when data is used for scientific purposes and is related to physical illnesses. Suggestions for health recommender system development are derived from the findings.
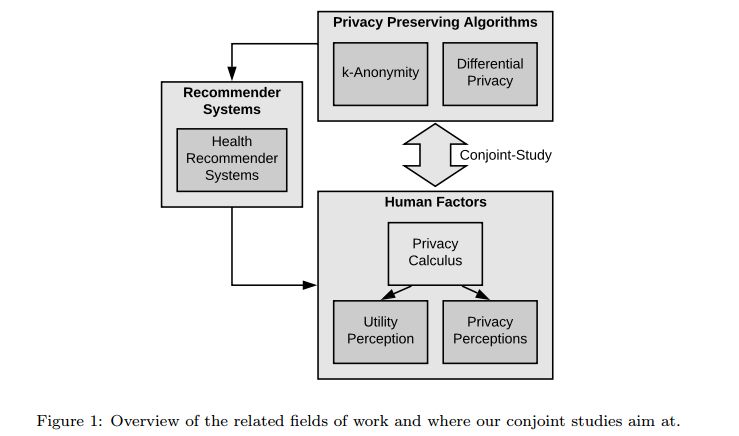
期刊:arXiv, 2018年4月13日
网址:
http://www.zhuanzhi.ai/document/92e994724b8a97df87ef31a89740624f
3. DeepFM: An End-to-End Wide & Deep Learning Framework for CTR Prediction(DeepFM:基于端到端深度学习框架的CTR预测)
作者:Huifeng Guo,Ruiming Tang,Yunming Ye,Zhenguo Li,Xiuqiang He,Zhenhua Dong
摘要:Learning sophisticated feature interactions behind user behaviors is critical in maximizing CTR for recommender systems. Despite great progress, existing methods have a strong bias towards low- or high-order interactions, or rely on expertise feature engineering. In this paper, we show that it is possible to derive an end-to-end learning model that emphasizes both low- and high-order feature interactions. The proposed framework, DeepFM, combines the power of factorization machines for recommendation and deep learning for feature learning in a new neural network architecture. Compared to the latest Wide & Deep model from Google, DeepFM has a shared raw feature input to both its "wide" and "deep" components, with no need of feature engineering besides raw features. DeepFM, as a general learning framework, can incorporate various network architectures in its deep component. In this paper, we study two instances of DeepFM where its "deep" component is DNN and PNN respectively, for which we denote as DeepFM-D and DeepFM-P. Comprehensive experiments are conducted to demonstrate the effectiveness of DeepFM-D and DeepFM-P over the existing models for CTR prediction, on both benchmark data and commercial data. We conduct online A/B test in Huawei App Market, which reveals that DeepFM-D leads to more than 10% improvement of click-through rate in the production environment, compared to a well-engineered LR model. We also covered related practice in deploying our framework in Huawei App Market.
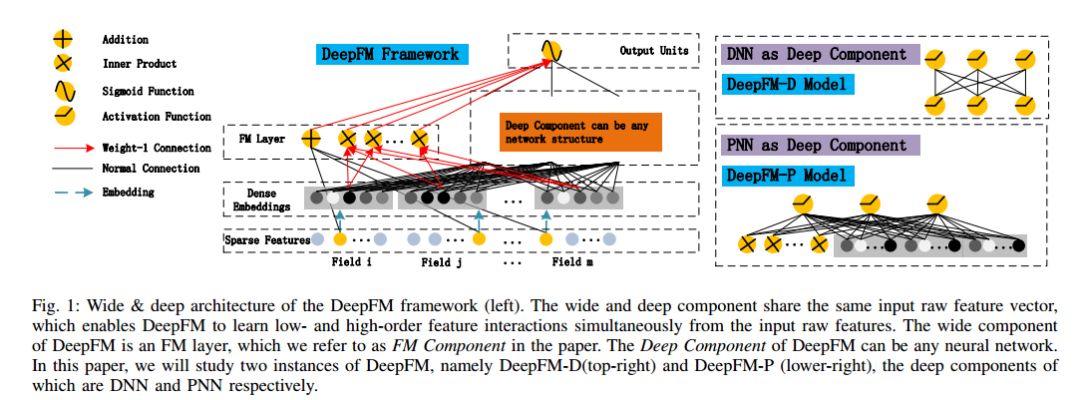
期刊:arXiv, 2018年4月12日
网址:
http://www.zhuanzhi.ai/document/9cfddb9f9e252ab4758928b5e09730bc
4. Any-k: Anytime Top-k Tree Pattern Retrieval in Labeled Graphs(Any-k)
作者:Xiaofeng Yang,Deepak Ajwani,Wolfgang Gatterbauer,Patrick K. Nicholson,Mirek Riedewald,Alessandra Sala
机构:Northeastern University
摘要:Many problems in areas as diverse as recommendation systems, social network analysis, semantic search, and distributed root cause analysis can be modeled as pattern search on labeled graphs (also called "heterogeneous information networks" or HINs). Given a large graph and a query pattern with node and edge label constraints, a fundamental challenge is to nd the top-k matches ac- cording to a ranking function over edge and node weights. For users, it is di cult to select value k . We therefore propose the novel notion of an any-k ranking algorithm: for a given time budget, re- turn as many of the top-ranked results as possible. Then, given additional time, produce the next lower-ranked results quickly as well. It can be stopped anytime, but may have to continues until all results are returned. This paper focuses on acyclic patterns over arbitrary labeled graphs. We are interested in practical algorithms that effectively exploit (1) properties of heterogeneous networks, in particular selective constraints on labels, and (2) that the users often explore only a fraction of the top-ranked results. Our solution, KARPET, carefully integrates aggressive pruning that leverages the acyclic nature of the query, and incremental guided search. It enables us to prove strong non-trivial time and space guarantees, which is generally considered very hard for this type of graph search problem. Through experimental studies we show that KARPET achieves running times in the order of milliseconds for tree patterns on large networks with millions of nodes and edges.
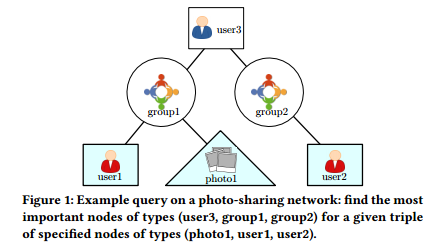
期刊:arXiv, 2018年4月11日
网址:
http://www.zhuanzhi.ai/document/c684f797d7e4a1c40c580d5d42aa0aa9
5. Optimizing Slate Recommendations via Slate-CVAE(通过Slate-CVAE优化建议)
作者:Ray Jiang,Sven Gowal,Timothy A. Mann,Danilo J. Rezende
摘要:The slate recommendation problem aims to find the "optimal" ordering of a subset of documents to be presented on a surface that we call "slate". The definition of "optimal" changes depending on the underlying applications but a typical goal is to maximize user engagement with the slate. Solving this problem at scale is hard due to the combinatorial explosion of documents to show and their display positions on the slate. In this paper, we introduce Slate Conditional Variational Auto-Encoders (Slate-CVAE) to generate optimal slates. To the best of our knowledge, this is the first conditional generative model that provides a unified framework for slate recommendation by direct generation. Slate-CVAE automatically takes into account the format of the slate and any biases that the representation causes, thus truly proposing the optimal slate. Additionally, to deal with large corpora of documents, we present a novel approach that uses pretrained document embeddings combined with a soft-nearest-neighbors layer within our CVAE model. Experiments show that on the simulated and real-world datasets, Slate-CVAE outperforms recommender systems that consists of greedily ranking documents by a significant margin while remaining scalable.
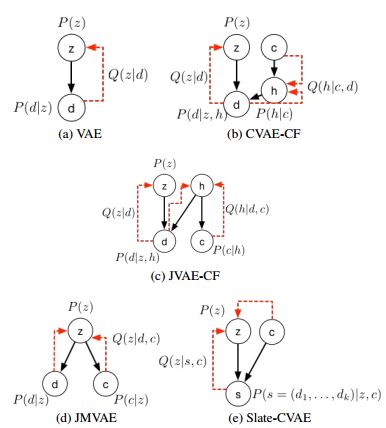
期刊:arXiv, 2018年4月9日
网址:
http://www.zhuanzhi.ai/document/9d6adeef83b962b4e636805b3034bb58
6. Human Interaction with Recommendation Systems(基于人机交互的推荐系统)
作者:Sven Schmit,Carlos Riquelme
机构:Stanford University
摘要:Many recommendation algorithms rely on user data to generate recommendations. However, these recommendations also affect the data obtained from future users. This work aims to understand the effects of this dynamic interaction. We propose a simple model where users with heterogeneous preferences arrive over time. Based on this model, we prove that naive estimators, i.e. those which ignore this feedback loop, are not consistent. We show that consistent estimators are efficient in the presence of myopic agents. Our results are validated using extensive simulations.
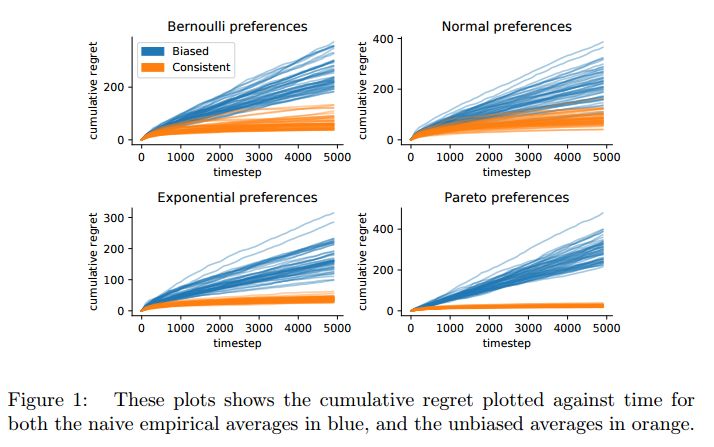
期刊:arXiv, 2018年3月29日
网址:
http://www.zhuanzhi.ai/document/9ea1eaeb473c6eff5d69e6bf25841a0c
7. Collaborative Filtering with Topic and Social Latent Factors Incorporating Implicit Feedback(包含隐含反馈的主题和社交潜在因素的协同过滤)
作者:Guang-Neng Hu,Xin-Yu Dai,Feng-Yu Qiu,Rui Xia,Tao Li,Shu-Jian Huang,Jia-Jun Chen
机构:Nanjing Univeristy
摘要:Recommender systems (RSs) provide an effective way of alleviating the information overload problem by selecting personalized items for different users. Latent factors based collaborative filtering (CF) has become the popular approaches for RSs due to its accuracy and scalability. Recently, online social networks and user-generated content provide diverse sources for recommendation beyond ratings. Although {\em social matrix factorization} (Social MF) and {\em topic matrix factorization} (Topic MF) successfully exploit social relations and item reviews, respectively, both of them ignore some useful information. In this paper, we investigate the effective data fusion by combining the aforementioned approaches. First, we propose a novel model {\em \mbox{MR3}} to jointly model three sources of information (i.e., ratings, item reviews, and social relations) effectively for rating prediction by aligning the latent factors and hidden topics. Second, we incorporate the implicit feedback from ratings into the proposed model to enhance its capability and to demonstrate its flexibility. We achieve more accurate rating prediction on real-life datasets over various state-of-the-art methods. Furthermore, we measure the contribution from each of the three data sources and the impact of implicit feedback from ratings, followed by the sensitivity analysis of hyperparameters. Empirical studies demonstrate the effectiveness and efficacy of our proposed model and its extension.
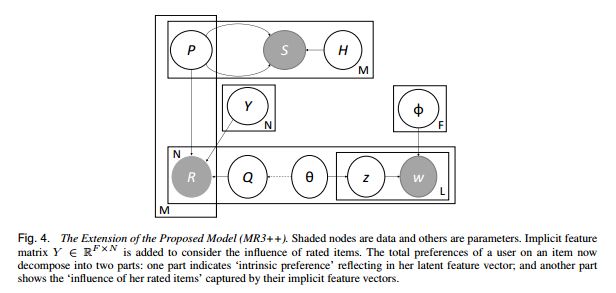
期刊:arXiv, 2018年3月26日
网址:
http://www.zhuanzhi.ai/document/680edb9a72d6226b1503cd996f112c8b
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

点击上面图片加入会员
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

点击“阅读原文”,使用专知
展开全文



