【论文推荐】最新十二篇情感分析相关论文—自然语言推理框架、网络事件、多任务学习、实时情感变化检测、多因素分析、深度语境词表示
【导读】专知内容组整理了最近十二篇情感分析(Sentiment Analysis)相关文章,为大家进行介绍,欢迎查看!
1. ρ-hot Lexicon Embedding-based Two-level LSTM for Sentiment Analysis(基于ρ-hot词典嵌入的二级LSTM情感分析)
作者:Ou Wu,Tao Yang,Mengyang Li,Ming Li
摘要:Sentiment analysis is a key component in various text mining applications. Numerous sentiment classification techniques, including conventional and deep learning-based methods, have been proposed in the literature. In most existing methods, a high-quality training set is assumed to be given. Nevertheless, constructing a high-quality training set that consists of highly accurate labels is challenging in real applications. This difficulty stems from the fact that text samples usually contain complex sentiment representations, and their annotation is subjective. We address this challenge in this study by leveraging a new labeling strategy and utilizing a two-level long short-term memory network to construct a sentiment classifier. Lexical cues are useful for sentiment analysis, and they have been utilized in conventional studies. For example, polar and privative words play important roles in sentiment analysis. A new encoding strategy, that is, $\rho$-hot encoding, is proposed to alleviate the drawbacks of one-hot encoding and thus effectively incorporate useful lexical cues. We compile three Chinese data sets on the basis of our label strategy and proposed methodology. Experiments on the three data sets demonstrate that the proposed method outperforms state-of-the-art algorithms.
期刊:arXiv, 2018年3月21日
网址:
http://www.zhuanzhi.ai/document/9f0a5b91d95f818aee5c76a4b0597018
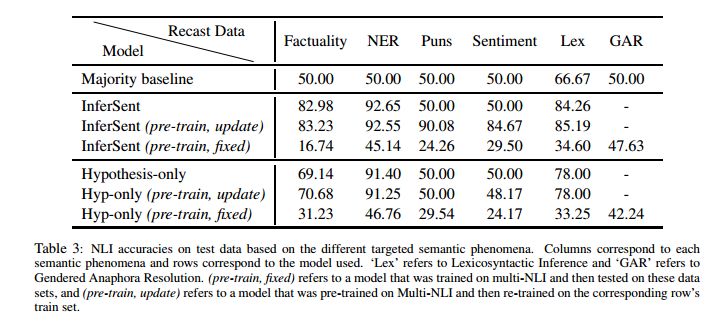
2. Towards a Unified Natural Language Inference Framework to Evaluate Sentence Representations(利用统一的自然语言推理框架评价句子表示)
作者:Adam Poliak,Aparajita Haldar,Rachel Rudinger,J. Edward Hu,Ellie Pavlick,Aaron Steven White,Benjamin Van Durme
机构:Johns Hopkins University,Brown University,University of Rochester
摘要:We present a large scale unified natural language inference (NLI) dataset for providing insight into how well sentence representations capture distinct types of reasoning. We generate a large-scale NLI dataset by recasting 11 existing datasets from 7 different semantic tasks. We use our dataset of approximately half a million context-hypothesis pairs to test how well sentence encoders capture distinct semantic phenomena that are necessary for general language understanding. Some phenomena that we consider are event factuality, named entity recognition, figurative language, gendered anaphora resolution, and sentiment analysis, extending prior work that included semantic roles and frame semantic parsing. Our dataset will be available at https://www.decomp.net, to grow over time as additional resources are recast.
期刊:arXiv, 2018年4月23日
网址:
http://www.zhuanzhi.ai/document/8c266baec62646503c32f42c61086fb7
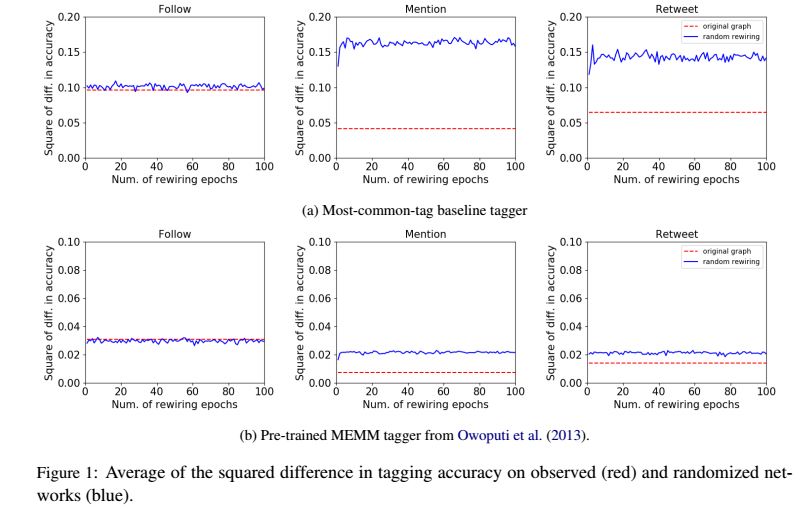
3. Stylistic Variation in Social Media Part-of-Speech Tagging(社交媒体词性标注中的语体变异)
作者:Murali Raghu Babu Balusu,Taha Merghani,Jacob Eisenstein
摘要:Social media features substantial stylistic variation, raising new challenges for syntactic analysis of online writing. However, this variation is often aligned with author attributes such as age, gender, and geography, as well as more readily-available social network metadata. In this paper, we report new evidence on the link between language and social networks in the task of part-of-speech tagging. We find that tagger error rates are correlated with network structure, with high accuracy in some parts of the network, and lower accuracy elsewhere. As a result, tagger accuracy depends on training from a balanced sample of the network, rather than training on texts from a narrow subcommunity. We also describe our attempts to add robustness to stylistic variation, by building a mixture-of-experts model in which each expert is associated with a region of the social network. While prior work found that similar approaches yield performance improvements in sentiment analysis and entity linking, we were unable to obtain performance improvements in part-of-speech tagging, despite strong evidence for the link between part-of-speech error rates and social network structure.
期刊:arXiv, 2018年4月20日
网址:
http://www.zhuanzhi.ai/document/17b94f2296f93213f9446473545891d2
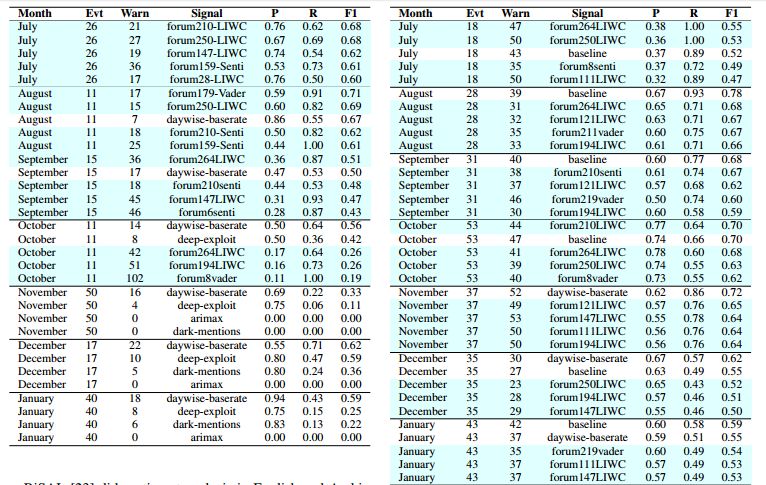
4. Predicting Cyber Events by Leveraging Hacker Sentiment(利用黑客情绪预测网络事件)
作者:Ashok Deb,Kristina Lerman,Emilio Ferrara
摘要:Recent high-profile cyber attacks exemplify why organizations need better cyber defenses. Cyber threats are hard to accurately predict because attackers usually try to mask their traces. However, they often discuss exploits and techniques on hacking forums. The community behavior of the hackers may provide insights into groups' collective malicious activity. We propose a novel approach to predict cyber events using sentiment analysis. We test our approach using cyber attack data from 2 major business organizations. We consider 3 types of events: malicious software installation, malicious destination visits, and malicious emails that surpassed the target organizations' defenses. We construct predictive signals by applying sentiment analysis on hacker forum posts to better understand hacker behavior. We analyze over 400K posts generated between January 2016 and January 2018 on over 100 hacking forums both on surface and Dark Web. We find that some forums have significantly more predictive power than others. Sentiment-based models that leverage specific forums can outperform state-of-the-art deep learning and time-series models on forecasting cyber attacks weeks ahead of the events.
期刊:arXiv, 2018年4月15日
网址:
http://www.zhuanzhi.ai/document/1d8121498a862ab1ffe25b576aa22465
5. Deep Learning for Digital Text Analytics: Sentiment Analysis(基于深度学习的数字文本分析:情感分析)
作者:Reshma U,Barathi Ganesh H B,Mandar Kale,Prachi Mankame,Gouri Kulkarni
摘要:In today's scenario, imagining a world without negativity is something very unrealistic, as bad NEWS spreads more virally than good ones. Though it seems impractical in real life, this could be implemented by building a system using Machine Learning and Natural Language Processing techniques in identifying the news datum with negative shade and filter them by taking only the news with positive shade (good news) to the end user. In this work, around two lakhs datum have been trained and tested using a combination of rule-based and data driven approaches. VADER along with a filtration method has been used as an annotating tool followed by statistical Machine Learning approach that have used Document Term Matrix (representation) and Support Vector Machine (classification). Deep Learning algorithms then came into picture to make this system reliable (Doc2Vec) which finally ended up with Convolutional Neural Network(CNN) that yielded better results than the other experimented modules. It showed up a training accuracy of 96%, while a test accuracy of (internal and external news datum) above 85% was obtained.

期刊:arXiv, 2018年4月11日
网址:
http://www.zhuanzhi.ai/document/10e21f40c520031c42b5f0ad19abf903
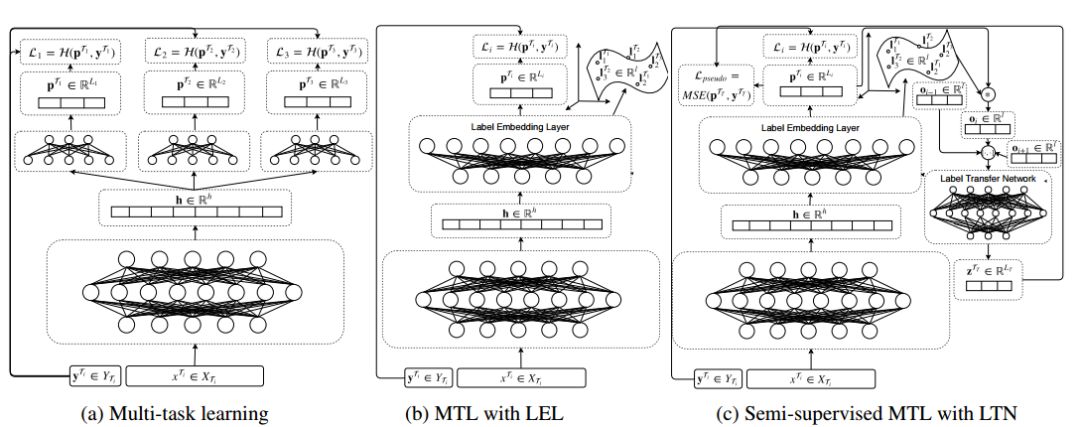
6. Multi-task Learning of Pairwise Sequence Classification Tasks Over Disparate Label Spaces(不同标签空间中成对序列分类任务的多任务学习)
作者:Isabelle Augenstein,Sebastian Ruder,Anders Søgaard
机构:University of Copenhagen,National University of Ireland
摘要:We combine multi-task learning and semi-supervised learning by inducing a joint embedding space between disparate label spaces and learning transfer functions between label embeddings, enabling us to jointly leverage unlabelled data and auxiliary, annotated datasets. We evaluate our approach on a variety of sequence classification tasks with disparate label spaces. We outperform strong single and multi-task baselines and achieve a new state-of-the-art for topic-based sentiment analysis.
期刊:arXiv, 2018年4月9日
网址:
http://www.zhuanzhi.ai/document/b53640c45a6caaff681cf7b99bb5704b
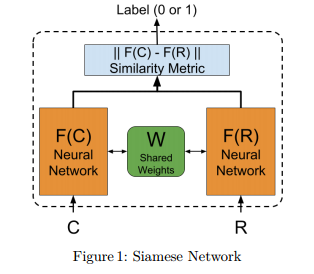
7. Sentiment Analysis of Code-Mixed Languages leveraging Resource Rich Languages
作者:Nurendra Choudhary,Rajat Singh,Ishita Bindlish,Manish Shrivastava
摘要:Code-mixed data is an important challenge of natural language processing because its characteristics completely vary from the traditional structures of standard languages. In this paper, we propose a novel approach called Sentiment Analysis of Code-Mixed Text (SACMT) to classify sentences into their corresponding sentiment - positive, negative or neutral, using contrastive learning. We utilize the shared parameters of siamese networks to map the sentences of code-mixed and standard languages to a common sentiment space. Also, we introduce a basic clustering based preprocessing method to capture variations of code-mixed transliterated words. Our experiments reveal that SACMT outperforms the state-of-the-art approaches in sentiment analysis for code-mixed text by 7.6% in accuracy and 10.1% in F-score.
期刊:arXiv, 2018年4月3日
网址:
http://www.zhuanzhi.ai/document/f80901df2c55ec41b781075dbcbff41e
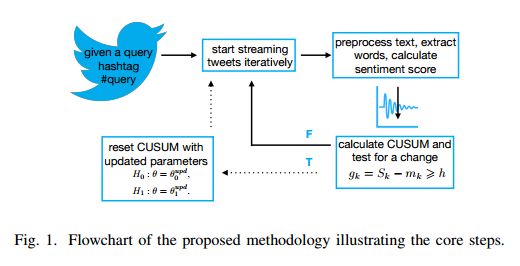
8. Real Time Sentiment Change Detection of Twitter Data Streams(Twitter数据流实时情感变化检测)
作者:Sotiris K. Tasoulis,Aristidis G. Vrahatis,Spiros V. Georgakopoulos,Vassilis P. Plagianakos
机构:University of Thessally
摘要:In the past few years, there has been a huge growth in Twitter sentiment analysis having already provided a fair amount of research on sentiment detection of public opinion among Twitter users. Given the fact that Twitter messages are generated constantly with dizzying rates, a huge volume of streaming data is created, thus there is an imperative need for accurate methods for knowledge discovery and mining of this information. Although there exists a plethora of twitter sentiment analysis methods in the recent literature, the researchers have shifted to real-time sentiment identification on twitter streaming data, as expected. A major challenge is to deal with the Big Data challenges arising in Twitter streaming applications concerning both Volume and Velocity. Under this perspective, in this paper, a methodological approach based on open source tools is provided for real-time detection of changes in sentiment that is ultra efficient with respect to both memory consumption and computational cost. This is achieved by iteratively collecting tweets in real time and discarding them immediately after their process. For this purpose, we employ the Lexicon approach for sentiment characterizations, while change detection is achieved through appropriate control charts that do not require historical information. We believe that the proposed methodology provides the trigger for a potential large-scale monitoring of threads in an attempt to discover fake news spread or propaganda efforts in their early stages. Our experimental real-time analysis based on a recent hashtag provides evidence that the proposed approach can detect meaningful sentiment changes across a hashtags lifetime.
期刊:arXiv, 2018年4月2日
网址:
http://www.zhuanzhi.ai/document/ee1b27074510cbaacf58341098208075
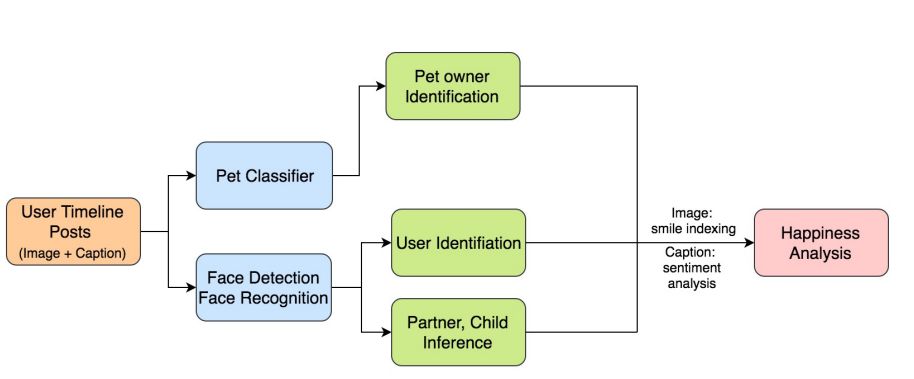
9. The Effect of Pets on Happiness: A Large-scale Multi-Factor Analysis using Social Multimedia(宠物对幸福感的影响: 一种基于社会多媒体的大规模多因素分析)
作者:Xuefeng Peng,Li-Kai Chi,Jiebo Luo
机构:University of Rochester
摘要:From reducing stress and loneliness, to boosting productivity and overall well-being, pets are believed to play a significant role in people's daily lives. Many traditional studies have identified that frequent interactions with pets could make individuals become healthier and more optimistic, and ultimately enjoy a happier life. However, most of those studies are not only restricted in scale, but also may carry biases by using subjective self-reports, interviews, and questionnaires as the major approaches. In this paper, we leverage large-scale data collected from social media and the state-of-the-art deep learning technologies to study this phenomenon in depth and breadth. Our study includes four major steps: 1) collecting timeline posts from around 20,000 Instagram users, 2) using face detection and recognition on 2-million photos to infer users' demographics, relationship status, and whether having children, 3) analyzing a user's degree of happiness based on images and captions via smiling classification and textual sentiment analysis, 3) applying transfer learning techniques to retrain the final layer of the Inception v3 model for pet classification, and 4) analyzing the effects of pets on happiness in terms of multiple factors of user demographics. Our main results have demonstrated the efficacy of our proposed method with many new insights. We believe this method is also applicable to other domains as a scalable, efficient, and effective methodology for modeling and analyzing social behaviors and psychological well-being. In addition, to facilitate the research involving human faces, we also release our dataset of 700K analyzed faces.
期刊:arXiv, 2018年3月24日
网址:
http://www.zhuanzhi.ai/document/b799cc1a758c25db8517184ed73038f9
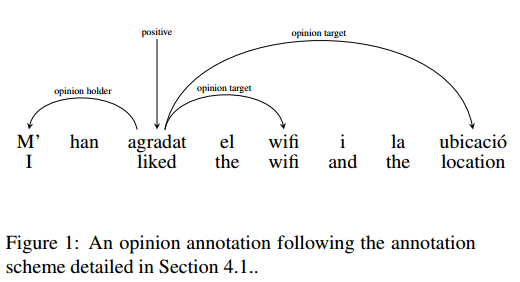
10. MultiBooked: A Corpus of Basque and Catalan Hotel Reviews Annotated for Aspect-level Sentiment Classification
作者:Jeremy Barnes,Patrik Lambert,Toni Badia
机构:Pompeu Fabra University
摘要:While sentiment analysis has become an established field in the NLP community, research into languages other than English has been hindered by the lack of resources. Although much research in multi-lingual and cross-lingual sentiment analysis has focused on unsupervised or semi-supervised approaches, these still require a large number of resources and do not reach the performance of supervised approaches. With this in mind, we introduce two datasets for supervised aspect-level sentiment analysis in Basque and Catalan, both of which are under-resourced languages. We provide high-quality annotations and benchmarks with the hope that they will be useful to the growing community of researchers working on these languages.
期刊:arXiv, 2018年3月23日
网址:
http://www.zhuanzhi.ai/document/8b1d05ec85b4cff82628f72e3d02dc00
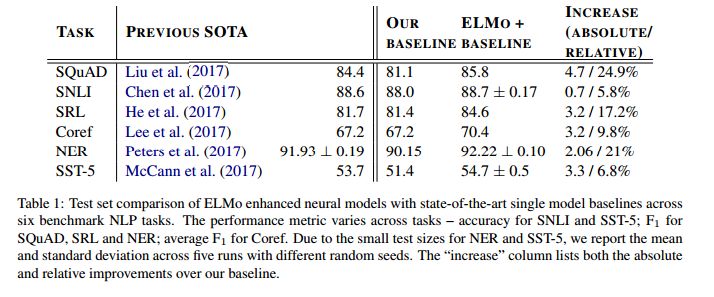
11. Deep contextualized word representations(深度语境词表示)
作者:Matthew E. Peters,Mark Neumann,Mohit Iyyer,Matt Gardner,Christopher Clark,Kenton Lee,Luke Zettlemoyer
机构:University of Washington
摘要:We introduce a new type of deep contextualized word representation that models both (1) complex characteristics of word use (e.g., syntax and semantics), and (2) how these uses vary across linguistic contexts (i.e., to model polysemy). Our word vectors are learned functions of the internal states of a deep bidirectional language model (biLM), which is pre-trained on a large text corpus. We show that these representations can be easily added to existing models and significantly improve the state of the art across six challenging NLP problems, including question answering, textual entailment and sentiment analysis. We also present an analysis showing that exposing the deep internals of the pre-trained network is crucial, allowing downstream models to mix different types of semi-supervision signals.
期刊:arXiv, 2018年3月23日
网址:
http://www.zhuanzhi.ai/document/e99adfc85a049b9b08d32861faee38fd
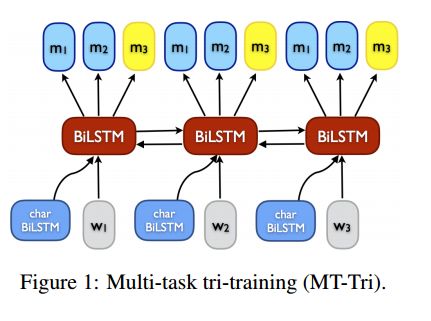
12. Strong Baselines for Neural Semi-supervised Learning under Domain Shift
作者:Sebastian Ruder,Barbara Plank
机构:National University of Ireland,University of Groningen,IT University of Copenhagen
摘要:Novel neural models have been proposed in recent years for learning under domain shift. Most models, however, only evaluate on a single task, on proprietary datasets, or compare to weak baselines, which makes comparison of models difficult. In this paper, we re-evaluate classic general-purpose bootstrapping approaches in the context of neural networks under domain shifts vs. recent neural approaches and propose a novel multi-task tri-training method that reduces the time and space complexity of classic tri-training. Extensive experiments on two benchmarks are negative: while our novel method establishes a new state-of-the-art for sentiment analysis, it does not fare consistently the best. More importantly, we arrive at the somewhat surprising conclusion that classic tri-training, with some additions, outperforms the state of the art. We conclude that classic approaches constitute an important and strong baseline.
期刊:arXiv, 2018年4月25日
网址:
http://www.zhuanzhi.ai/document/37dc8b1099c97ee67371cfda8559be93
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

点击上面图片加入会员
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

点击“阅读原文”,使用专知
展开全文



