【论文推荐】最新六篇自动问答相关论文—无监督迁移学习、综述、生成式问答、QDEE、可扩展文档理解
【导读】既前昨天推出七篇自动问答(Question Answering)相关文章,专知内容组今天又推出最近六篇自动问答相关文章,为大家进行介绍,欢迎查看!
8. Supervised and Unsupervised Transfer Learning for Question Answering(监督和无监督迁移学习的问答)
作者:Yu-An Chung,Hung-Yi Lee,James Glass
机构:National Taiwan Universit
摘要:Although transfer learning has been shown to be successful for tasks like object and speech recognition, its applicability to question answering (QA) has yet to be well-studied. In this paper, we conduct extensive experiments to investigate the transferability of knowledge learned from a source QA dataset to a target dataset using two QA models. The performance of both models on a TOEFL listening comprehension test (Tseng et al., 2016) and MCTest (Richardson et al., 2013) is significantly improved via a simple transfer learning technique from MovieQA (Tapaswi et al., 2016). In particular, one of the models achieves the state-of-the-art on all target datasets; for the TOEFL listening comprehension test, it outperforms the previous best model by 7%. Finally, we show that transfer learning is helpful even in unsupervised scenarios when correct answers for target QA dataset examples are not available.
期刊:arXiv, 2018年4月22日
网址:
http://www.zhuanzhi.ai/document/9d5cef129e82121f0a448b7bea2fc09b
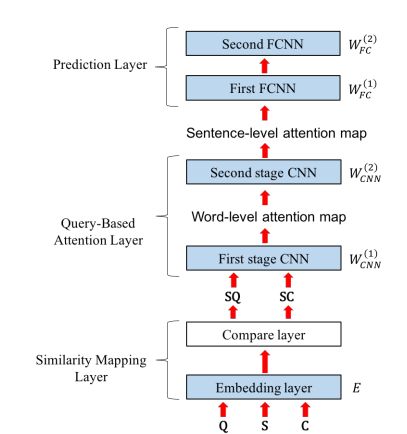
9. Expert Finding in Community Question Answering: A Review(社区问答的专家发现-综述)
作者:Sha Yuan,Yu Zhang,Jie Tang,Juan Bautista Cabotà
机构:Tsinghua University,University of Valencia
摘要:The rapid development recently of Community Question Answering (CQA) satisfies users quest for professional and personal knowledge about anything. In CQA, one central issue is to find users with expertise and willingness to answer the given questions. Expert finding in CQA often exhibits very different challenges compared to traditional methods. Sparse data and new features violate fundamental assumptions of traditional recommendation systems. This paper focuses on reviewing and categorizing the current progress on expert finding in CQA. We classify all the existing solutions into four different categories: matrix factorization based models (MF-based models), gradient boosting tree based models (GBT-based models), deep learning based models (DL-based models) and ranking based models (R-based models). We find that MF-based models outperform other categories of models in the field of expert finding in CQA. Moreover, we use innovative diagrams to clarify several important concepts of ensemble learning, and find that ensemble models with several specific single models can further boosting the performance. Further, we compare the performance of different models on different types of matching tasks, including text vs. text, graph vs. text, audio vs. text and video vs. text. The results can help the model selection of expert finding in practice. Finally, we explore some potential future issues in expert finding research in CQA.
期刊:arXiv, 2018年4月21日
网址:
http://www.zhuanzhi.ai/document/1b67d985b6d60507e9baf0cbbbd16285
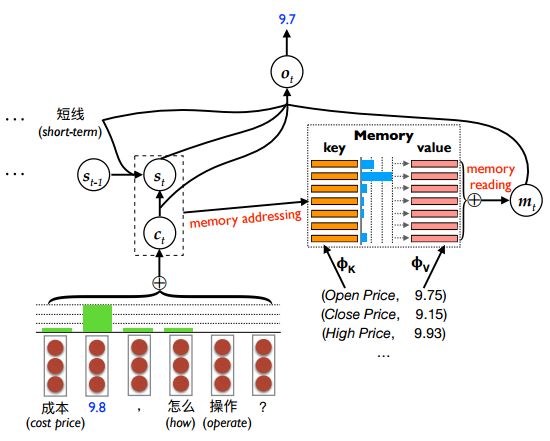
10. Generative Stock Question Answering(生成式证券问答)
作者:Zhaopeng Tu,Xiaojiang Liu,Lei Shu,Shuming Shi
机构:University of Illinois at Chicago
摘要:We study the problem of stock related question answering (StockQA): automatically generating answers to stock related questions, just like professional stock analysts providing action recommendations to stocks upon user's requests. StockQA is quite different from previous QA tasks since (1) the answers in StockQA are natural language sentences (rather than entities or values) and due to the dynamic nature of StockQA, it is scarcely possible to get reasonable answers in an extractive way from the training data; and (2) StockQA requires properly analyzing the relationship between keywords in QA pair and the numerical features of a stock. We propose to address the problem with a memory-augmented encoder-decoder architecture, and integrate different mechanisms of number understanding and generation, which is a critical component of StockQA. We build a large-scale Chinese dataset containing over 180K StockQA instances, based on which various technique combinations are extensively studied and compared. Experimental results show that a hybrid word-character model with separate character components for number processing, achieves the best performance.\footnote{The data is publicly available at \url{http://ai.tencent.com/ailab/nlp/dataset/}.}
期刊:arXiv, 2018年4月21日
网址:
http://www.zhuanzhi.ai/document/4f2a8ffc28b7657200a15854a89a8f8d
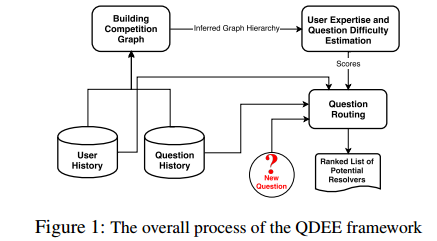
11. QDEE: Question Difficulty and Expertise Estimation in Community Question Answering Sites(QDEE:社区问答网站的问题难度和专业知识评估)
作者:Jiankai Sun,Sobhan Moosavi,Rajiv Ramnath,Srinivasan Parthasarathy
机构:The Ohio State University
摘要:In this paper, we present a framework for Question Difficulty and Expertise Estimation (QDEE) in Community Question Answering sites (CQAs) such as Yahoo! Answers and Stack Overflow, which tackles a fundamental challenge in crowdsourcing: how to appropriately route and assign questions to users with the suitable expertise. This problem domain has been the subject of much research and includes both language-agnostic as well as language conscious solutions. We bring to bear a key language-agnostic insight: that users gain expertise and therefore tend to ask as well as answer more difficult questions over time. We use this insight within the popular competition (directed) graph model to estimate question difficulty and user expertise by identifying key hierarchical structure within said model. An important and novel contribution here is the application of "social agony" to this problem domain. Difficulty levels of newly posted questions (the cold-start problem) are estimated by using our QDEE framework and additional textual features. We also propose a model to route newly posted questions to appropriate users based on the difficulty level of the question and the expertise of the user. Extensive experiments on real world CQAs such as Yahoo! Answers and Stack Overflow data demonstrate the improved efficacy of our approach over contemporary state-of-the-art models. The QDEE framework also allows us to characterize user expertise in novel ways by identifying interesting patterns and roles played by different users in such CQAs.
期刊:arXiv, 2018年4月21日
网址:
http://www.zhuanzhi.ai/document/f44349cfa856e0931ac5372d5c9af33e
12. Phrase-Indexed Question Answering: A New Challenge for Scalable Document Comprehension(短语索引问题回答:可扩展文档理解的新挑战)
作者:Minjoon Seo,Tom Kwiatkowski,Ankur P. Parikh,Ali Farhadi,Hannaneh Hajishirzi
机构:University of Washington
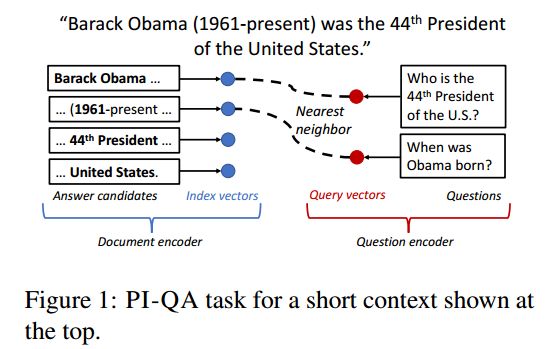
摘要:The current trend of extractive question answering (QA) heavily relies on the joint encoding of the document and the question. In this paper, we formalize a new modular variant of extractive QA, Phrase-Indexed Question Answering (PI-QA), that enforces complete independence of the document encoder from the question by building the standalone representation of the document discourse, a key research goal in machine reading comprehension. That is, the document encoder generates an index vector for each answer candidate phrase in the document; at inference time, each question is mapped to the same vector space and the answer with the nearest index vector is obtained. The formulation also implies a significant scalability advantage since the index vectors can be pre-computed and hashed offline for efficient retrieval. We experiment with baseline models for the new task, which achieve a reasonable accuracy but significantly underperform unconstrained QA models. We invite the QA research community to engage in PI-QA for closing the gap.
期刊:arXiv, 2018年4月21日
网址:
http://www.zhuanzhi.ai/document/23fde66849043866a51d58e667191d90
13. Putting Question-Answering Systems into Practice: Transfer Learning for Efficient Domain Customization(将问答系统应用到实践中)
作者:Bernhard Kratzwald,Stefan Feuerriegel
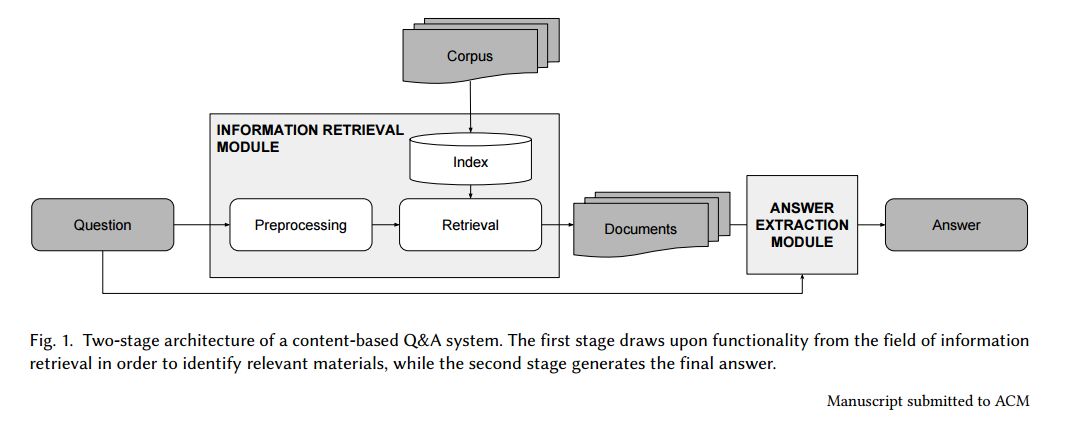
摘要:Traditional information retrieval (such as that offered by web search engines) impedes users with information overload from extensive result pages and the need to manually locate the desired information therein. Conversely, question-answering systems change how humans interact with information systems: users can now ask specific questions and obtain a tailored answer - both conveniently in natural language. Despite obvious benefits, their use is often limited to an academic context, largely because of expensive domain customizations, which means that the performance in domain-specific applications often fails to meet expectations. This paper presents cost-efficient remedies: a selection mechanism increases the precision of document retrieval and a fused approach to transfer learning is proposed in order to improve the performance of answer extraction. Here knowledge is inductively transferred from a related, yet different, tasks to the domain-specific application, while accounting for potential differences in the sample sizes across both tasks. The resulting performance is demonstrated with an actual use case from a finance company, where fewer than 400 question-answer pairs had to be annotated in order to yield significant performance gains. As a direct implication to management, this presents a promising path to better leveraging of knowledge stored in information systems.
期刊:arXiv, 2018年4月19日
网址:
http://www.zhuanzhi.ai/document/4bdd2336b711177b2502af5b50ea0fb3
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

点击上面图片加入会员
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

点击“阅读原文”,使用专知
展开全文



