【前沿】简化标注者工作:Google等学者提出基于智能对话的边界框标注方法
【导读】近日,针对目标检测中边界框标注速度慢、花费高的问题,来自Google、EPFL、IST的学者发表论文提出基于智能对话的边界框标注方法。其方法通过结合框验证和手动画框的交互式方法,设计了两种模型:其一是基于预测接受概率的交互式标注对话方法,其二是基于强化学习的交互式标注对话方法。作者在PASCAL VOC2007数据集上验证了方法效果,证明了所提出方法可以显著提升标注效率。
论文:Learning Intelligent Dialogs for Bounding Box Annotation

▌摘要
这篇文章引入了边界框标注的智能标注对话工具。作者训练一个agent自动为人为标注器选择一系列操作,在最短的时间生成边界框。具体来说,本文考虑两种行为:框验证,即标注器验证由目标检测器生成的框,和手动标注框。作者探索两种agent,一个基于框会主动被验证的预测概率,另一个考虑强化学习。本文证明:
(1)提出的agent能够在几种情况下学习高效的标注策略,自动适应输入图像的维度,框的期望质量,检测器的强度,和其他因素;
(2)在所有的场景中,由此产生的标注对话方式与单独的手动框和框验证相比,加快了标注的速度,同时在大多数情况下也优于任何固定的验证和人为画框组合。
(3)在检测器迭代重新训练的实际情况下,提出的agent进行一系列的策略研究,这些反映了随着检测器变得越来越强大,验证和人为画框之间的折中转移。
▌详细内容
计算机视觉方面的许多最新进展依赖于有监督的机器学习技术,这些技术需要大量的训练数据。目标检测也不例外,前沿方法需要大量的对象周围带有标注边界框的图像。然而,获取高质量的边框是昂贵的:用于标注ILSVRC的官方协议每个框需要大约30秒。为了降低成本,最近的工作探索了更简单的人工监督形式,比如图像级标签,框验证序列,点标注和眼球跟踪。
在这些形式中,最近的框验证序列(box verification series)结果突出,因为它能以低成本提供高质量的检测结果。 该方案从给定的弱检测器开始,通常仅在图像标签上进行训练,并使用它来定位图像中的目标。对于每个图像,要求标注者验证由该算法产生的框是否足够紧密地覆盖目标。如果不是,则该过程进行迭代:该算法生产另一个框,标注者验证它。

图1 左:目标类别为猫的图像。弱检测器确定了两个高分检测框。 在这种情况下,最好的策略是做一系列的框验证。 右:目标类为盆栽植物的形象。 弱检测器识别出许多低分的检测框。 这种情况下,最好的策略是画一个框
框验证序列的成功取决于多种因素。例如,同构背景上的大物体很可能在早期被发现,因此需要很少的标注时间(图1,左)。然而,在拥挤场景中的小物体可能需要很多迭代,甚至可能根本找不到(图1,右)。 此外,检测器越强,正确定位新物体的可能性越大,并且其能在序列早期找到目标。最后,预期的框质量越高(框的紧凑程度),则正例验证框出现的比率就越低。这导致更长的迭代,花费更多的标注时间。 因此,在某些情况下,手动标注框是可取的。虽然比验证更昂贵,但它总能产生一个框标注。当一个标注集合由许多验证组成时,其持续时间可能比绘制一个框的时间更长,这取决于两个动作的相对成本。因此,组合不同形式的标注方法在不同情况下效率更高。
在本文中,作者将介绍用于边界框标注的智能标注对话(IAD)。给定一个图像,检测器和目标类别进行标注,IAD的目标是自动选择标注行为序列,它能在最少的时间内产生边界框。根据以前在标注图像中的经验,作者训练IADagent来选择动作的类型。提出的方法自动适应图像的维度,检测器的强度,框的期望质量以及其他因素。这是通过将事件持续时间作为问题属性的函数建模来实现的。作者考虑两种方法来做到这一点,a)通过预测提出的框是否会被正面或负面验证(4.1节),b)通过直接预测事件持续时间(4.2节)。
本文通过在PASCAL VOC 2007数据集中标注边界框来评估IAD,在以下种情况:a)具有各种期望的质量水平; b)具有不同强度的检测器; c)用两种方法绘制边界框,包括最近标注每个框只需要7s的方法 。在所有情况下,实验都表明,由于其适应性行为,与单独手动绘框或框验证序列相比,IAD加快了框标注的速度。而且,在大多数情况下,它胜过它们的任何固定组合。 最后,作者证明IAD能在一个复杂的现实场景中学习到有用的策略,其中检测器随着训练数据的增加而不断改进。
▌方法简介
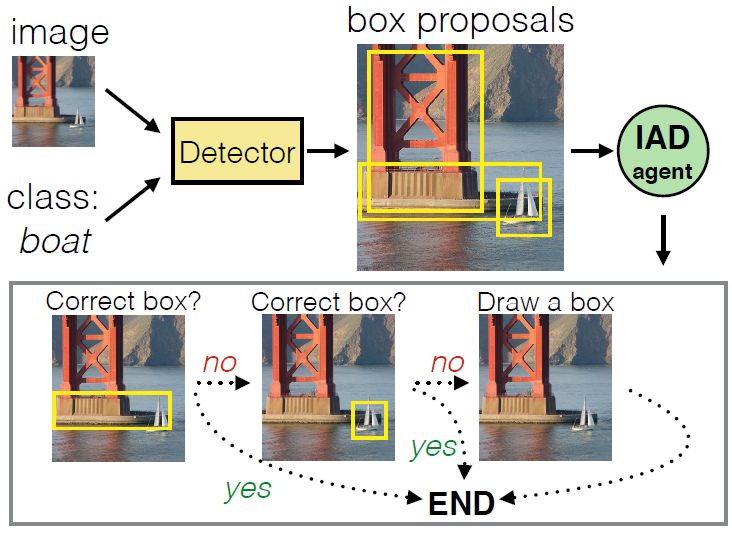
图2 智能标注对话(Intelligent Annotation Dialog)执行的示意图。
本文提出了两种方法来做交互式的标注对话(IAD):
(1) 通过预测接受概率来进行IAD
优化策略:假设我们知道每个框以置信度被接受的概率为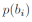
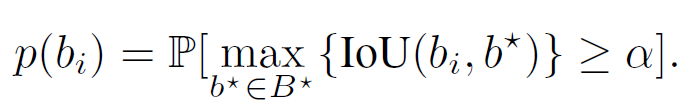
方法一的算法如下:

这里
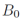

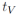
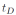
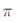
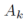
(2) 通过强化学习来进行IAD
这里强化学习的agent可以通过与环境的实验交互学习到最优的策略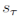
▌实验结果
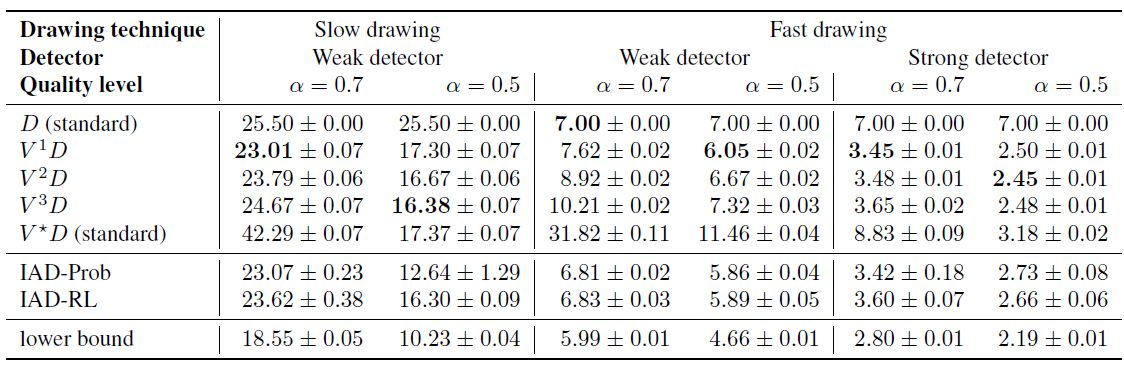
表1: standard, fixed 和IAD不同策略的结果。
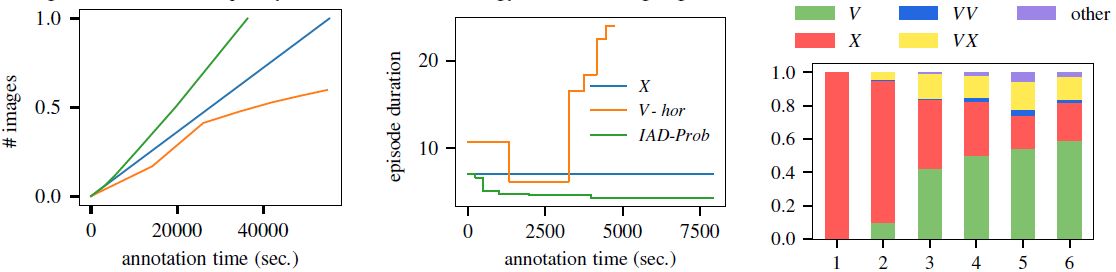
▌结论
在本文中,作者介绍了智能标注对话用于标注边界框的任务。IAD自动选择结果的一系列动作VkD,使标注在时间上效率很高。作者提出了两种方法来实现。第一种方法是通过预测每个候选框的接受概率对标注时间建模。第二种方法跳过建模步骤,通过反复试验来直接学习有效的策略。在广泛的实验评估中,IAD展示了与各种基本方法的可比较性表现以及适应多个问题泛化的能力。在在将来的工作中,作者希望在标注过程中引入标注时间和上下文切换变量。
参考链接:
https://arxiv.org/abs/1712.08087
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!

点击“阅读原文”,使用专知!
展开全文



