【Uber AI新论文】持续元学习,Learning to Continually Learn

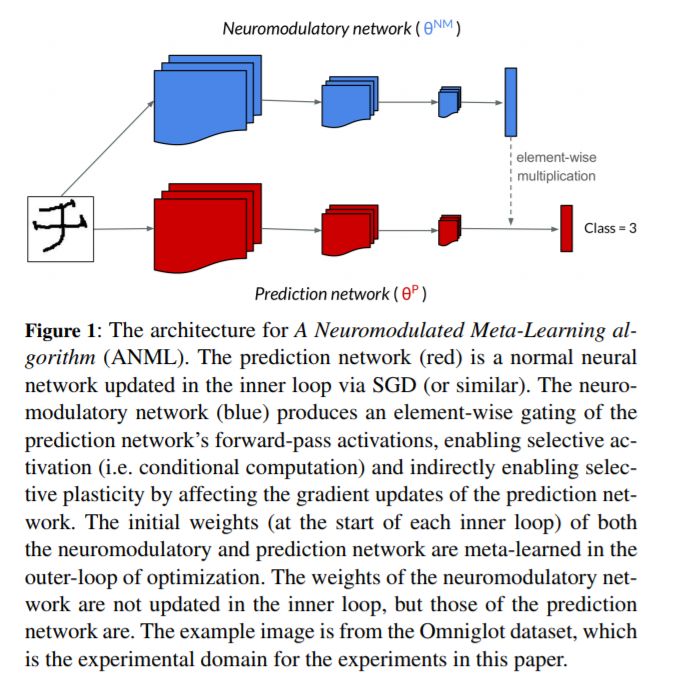
持续的终身学习需要一个代理或模型学习许多按顺序排列的任务,建立在以前的知识上而不是灾难性地忘记它。许多工作都是为了防止机器学习模型的默认趋势灾难性地遗忘,但实际上所有这些工作都涉及到手工设计的问题解决方案。我们主张元学习是一种解决灾难性遗忘的方法,允许人工智能不断学习。受大脑神经调节过程的启发,我们提出了一种神经调节元学习算法(ANML)。它通过一个连续的学习过程来区分元学习一个激活门控功能,使上下文相关的选择激活在深度神经网络中成为可能。具体地说,一个神经调节(NM)神经网络控制另一个(正常的)神经网络的前向通道,称为预测学习网络(PLN)。NM网络也因此间接地控制PLN的选择性可塑性(即PLN的后向通径)。ANML支持持续学习而不会出现大规模的灾难性遗忘:它提供了最先进的连续学习性能,连续学习多达600个类(超过9000个SGD更新)。
地址:
https://arxiv.org/abs/2002.09571
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“LCL” 就可以获取《持续元学习,Learning to Continually Learn》专知下载链接



展开全文



