【观点】漫谈推荐系统及数据库技术
点击上方“专知”关注获取更多AI知识!
【导读】推荐系统和数据库技术,一个是偏机器学习数据挖掘相关的应用,一个是偏系统存储相关的技术,这两者在实际中有很大的应用。今天,很高兴邀请到资深算法工程师宋强对此漫谈自己一些工作的独到见解,欢迎阅读~
科研工作者的前世今生
笔者早年在人工智能领域上进修硕士,研究的方向是推荐系统,虽然最终未能将所学发扬光大,但亦心存敬畏,时常拜读相关著作。随后阴差阳错,人生中的第一份正式工作是从事分布式数据库的研发。受学长相邀,写下一点感悟。
矛盾的心理
人工智能和数据库都是当前的热潮之一,二者研发的目的都是为了尽可能的提升性能,但通往两者目标道路之间却有着本质的差别。前者常常将最小化辨识误差作为优化目标,通过一系列构造、松弛或正则约束获得最佳的模型参数。后者则将数据存取毫无偏差作为一条真理,通过数据一致性算法等方式实现高可用。绝大多数的机器学习算法并不适用于数据库研发,所以就有了职场小白的概念。不过仔细想想,两者之间的关联性就像海绵里的水,挤挤还是有的。
我所熟悉的一类推荐算法
近年来,随着互联网技术快速发展,信息呈现爆炸式增长,如何帮助用户在短时间内准确获取对自己有价值的信息,提高信息使用率,是现今互联网应用所面临的一大难题。[1]我所熟悉的一类算法名为协同过滤,本质的意思就是通过相似用户曾经购买过的相似商品推荐潜在喜爱的商品给目标用户。
经典推荐算法
最常用的协同过滤算法是矩阵分解(喜欢深究的同学推荐看看张志华老师的Matrix Completion [2])。它将用户和商品通过一个隐含因子f联系在一起,例如:电影评分中,我们仅知道部分观众对部分电影的打分。通过该方式可估算出其他缺失的打分。具体而言,每个商品i都可表示为一个一维向量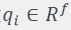

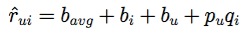
其中,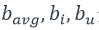
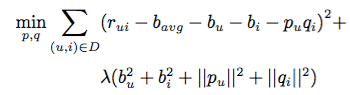
该方法可以通过随机梯度下降求解(SGD),在此不赘述。
多维推荐算法
更进一步,商品可能包含多个不同的领域,虽然每个领域的数据较少,但加在一起整体来看可以丰富推荐素材。比如,用户间音乐上的共识往往能够挖掘出电影或书籍方面的潜在爱好。这便萌生了多维推荐系统(Multi-Domain Recommendation)
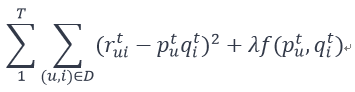
Pairwise倾向性推荐算法
此外,相较于评分而言,用户常常更喜欢使用倾向性的选择,即观众更喜欢描述电影i比j好看,小说x比y羞涩等等。所以在优化函数设计上,将倾向性作为优化方向更加合适。比如[3]:
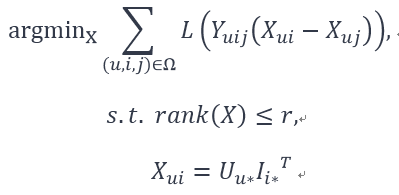
其中,L表示模型等损失函数,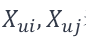
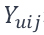
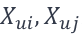
高维推荐算法(拓扑至N维)
然而,二维平面的分析仅仅是我们理论研究的一块基石,而现实中的数据往往涵盖了多个维度。例如,在真实的推荐场景汇总,除了最为常见的用户和商品维度外,实际上还有时间、标签、查询、价格等诸多有价值的维度,充分利用及挖掘它们之间的潜在联系可以有效地了解用户真实的需求。N维(
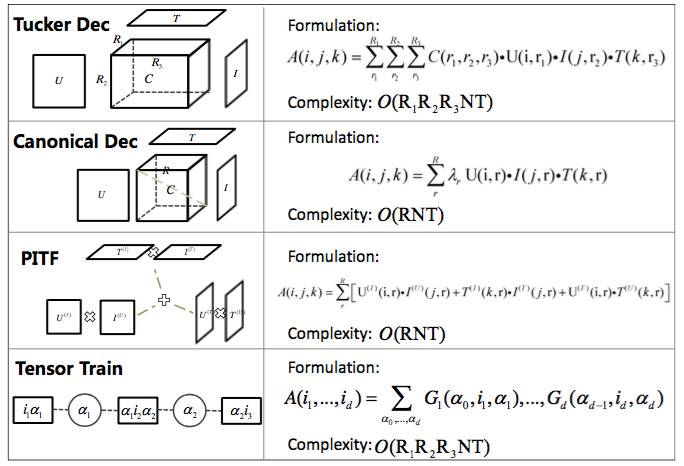
基于协同过滤方式的N维(不妨N=3)推荐算法如下:
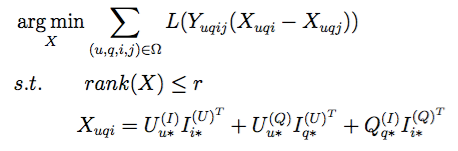
该优化表达式可以通过随机对偶坐标下降法(Stochastic Dual Coordinate Descent)求解。
关于推荐系统的介绍就在此告一段落,感兴趣的同学可以继续关注我们专知AI(www.zhuanzhi.ai)。
我所学习过的数据库技术
漫谈数据库技术
在当下的互联网信息时代,数据库对任何一个公司乃至行业的发展都是至关重要的。无论是搜索引擎,例如Google、Baidu,亦或是生活服务类网站,例如淘宝、京东,还是金融市场及其服务领域,例如金融资讯、交易、登记结算等;无论是人工智能、大数据,亦或是云计算平台,幕后都离不开数据库的支撑。
高可用是数据库系统一个关键的指标,当前几乎所有的热门数据库都标榜着自己是稳定高可用的。比如:Amazon的RDS、阿里云的SQL以及OceanBase等。而腾讯云数据库则是宣称达到了工信部认证的99.95%。由高可用衍生出来的问题包括单点问题、自动恢复和在线扩容等。以单点问题为例:存在单点服务的情况下,一旦单点服务挂掉,整个服务就不可用。消除单点问题最常用的方案就是复制(Replication),通过数据冗余的方式来实现高可用。
大数据时代的来临,催生来许多新鲜的科技萌生和进步。在分布式数据库相关领域,热门的技术很多,例如paxos、raft等一系列数据一致性算法,kafka技术、基于弱XA的分布式事务、HLC混合逻辑时钟等等。下面将介绍一个当前比较热门的技术:
Raft数据一致性算法
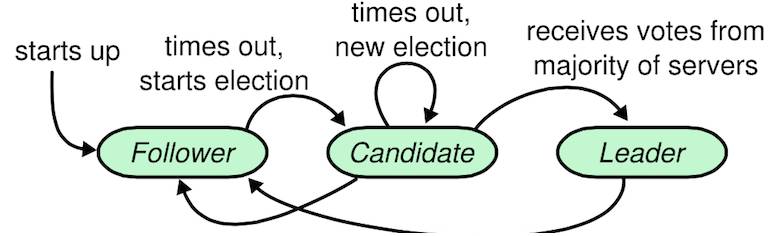
Raft算法[4]是一种简化版的数据一致性算法,由于其理论通熟易懂,且实现较为便捷,使之成为当前比较热门的数据库技术。通俗地说,它是一种将一份数据同时保存在多个节点上,保障任意节点宕机仍然能够提供稳定高可用服务的技术。它的实现机理可以类比于美国总统大选的流程。
节点的角色有follower(跟随者)、candidate(候选人)、leader(领导)三种。初始的状态都是follower,节点与节点间通过心跳的方式进行通信,如果当下没有leader,则每个follower都会经过一个随机产生的时间后发起选举,同时升级为candidate,并通过广播的形式告知其他节点给自己投票(随机时间的目的是为了防止candidate数量太多)。经过一轮角逐后,票数最高的candidate节点成为了leader,而其他落选的candidate则降级成为follower。成功当选Leader的节点将即刻将自己当前还未落地的数据通过广播方式同步给其他follower节点。值得注意的是,leader永远只有1个或者没有leader。当投票结束且出现同票现象时,将重现进行新一轮选举。此外,当某个follower节点长时间没有收到leader的广播,则也会在一定时间后发起新的选举。
成功当选Leader的节点开始为客户端提供服务。客户端的每一个请求都包含一条被复制状态机执行的指令。leader把这条指令作为一条新的日志数据附加到日志中去,然后并行的发起附加数据以RPCs方式给其他的follower节点,让他们复制这条日志数据。当这条日志数据被绝大多数(N/2+1)follower节点接受时,leader会即刻将这条日志数据到它的状态机中然后把执行的结果返回给客户端。如果follower崩溃或者运行缓慢,再或者网络丢包,leader会不断的重复尝试附加日志数据RPCs(尽管已经回复了客户端)直到所有的follower都最终存储了该日志数据。
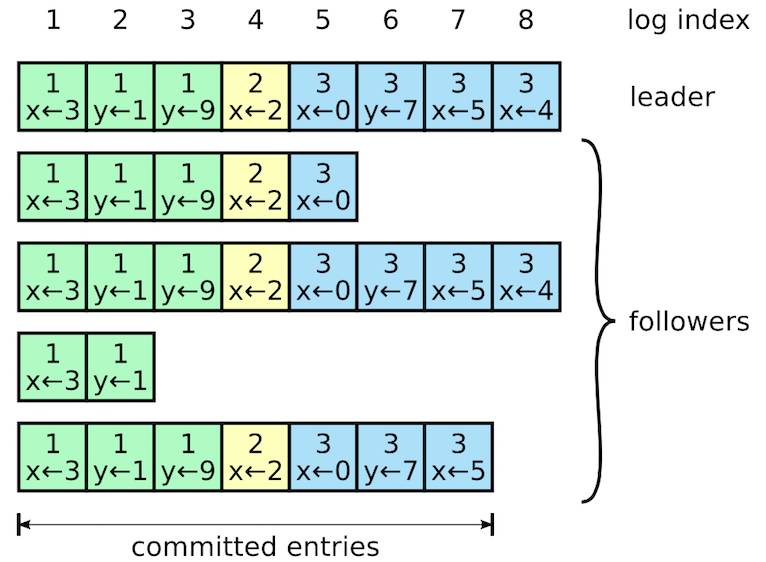
在正常的操作中,leader和follower的日志保持一致性,所以附加日志RPC的一致性检查从来不会失败。然而,leader崩溃的情况会使得日志处于不一致的状态(老的leader可能还没有完全复制所有的日志数据)。这种不一致问题会在一系列的leader和follower崩溃的情况下加剧。在Raft算法中,leader处理不一致现象是通过强follower直接复制自己的日志来解决的。这意味着在follower中的冲突的日志数据会被leader的日志覆盖。要使得follower的日志进入和自己一致的状态,leader必须找到最后两者达成一致的地方,然后删除从那个点之后的所有日志数据,发送自己的日志给follower。所有的这些操作都在进行附加日志RPCs的一致性检查时完成。leader针对每一个follower维护了一个 nextIndex,这表示下一个需要发送给follower的日志数据的索引地址。当一个leader刚上任开始,他初始化所有的nextIndex值为自己的最后一条日志的index加1。如果一个follower的日志和leader不一致,那么在下一次的附加日志RPC 时的一致性检查就会失败。在被follower拒绝之后,leader就会减小 nextIndex值并进行重试。最终 nextIndex 会在某个位置使得leader和follower的日志达成一致。
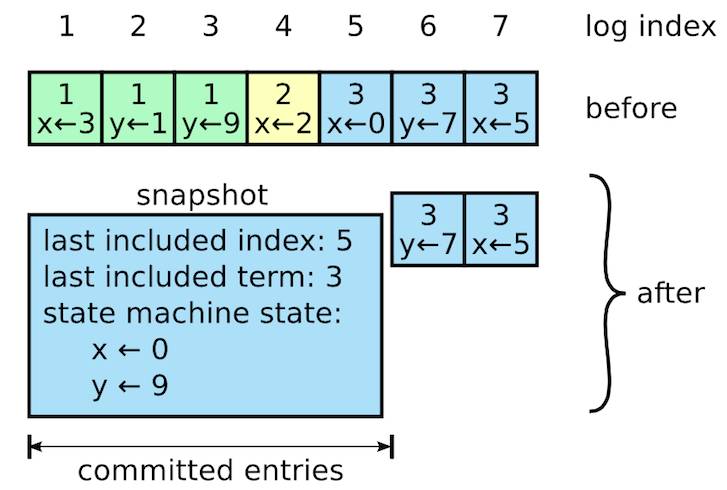
为了保证已经提交的数据不会被新的leader更改,raft算法对可能成为leader的candidate节点进行了约束,只有包含所有已经提交数据的candidate才能成为leader。这一约束条件具体的做法是,RPC中包含了候选人的日志信息,然后投票人会拒绝掉那些日志没有自己新的投票请求。
Raft的日志在正常操作中不断的增长,但是在实际的系统中,日志不能无限制的增长。随着日志不断增长,他会占用越来越多的空间,花费越来越多的时间来重置。Raft采用了snapshot快照的方式,对已经提交的日志进行压缩和同步。
Raft算法在分布式系统上的应用
Raft算法要求底层的数据节点为2N + 1个(目的为了方便选出leader)。假定默认设置为3个,那么,它将如何应用到一个有6个数据节点的分布式系统呢?
解决的思路为:对数据进行分区,要求彼此相互独立;对每个分区随机的选择3个数据节点作为存储,这便是Multi-raft的设计初衷。
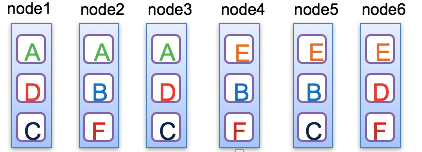
Raft算法如何实现在线扩容的呢?这里实际上涵盖了两个子问题,一者是raft环内怎么实现节点个数的增加(参与选举的节点变多);另一者是raft怎么实现水平扩充(可以存储的数据变多)。
前者的解决思路为:新增的节点首先从leader上进行数据同步,在同步期间不具备参与选举的权利,当同步完成后,再自然而然的恢复选举权。后者的解决思路为:在某一时刻,某个raft环X达到了存储数据的阈值,则开始进入分裂阶段,计划拆分成X1和X2两段。新增加一组raft环Y同步X2的数据,但X仍然继续工作,当Y同步X2完成后,X更改成X1,同时Y对外提供X2服务。
人工智能在数据库上的应用
如何将人工智能算法引入到数据库应用中是一个值得思考的问题。下面提供两个可能的应用:
在数据库的研发中,对底层存储的设计是一个核心工作。考虑到分布式数据库存储多个相互独立的raft环,每个raft环中的数据都需要持久化落地,而IO读写性能也是一个约束(减少IO读写次数对于系统存取性能的提升非常重要)。在存储设计上,考虑批量落地策略,按各个Raft环的数据顺序放入队列中,并定期一次性存储,同时建立逻辑文件链式索引,当遇到查询指令且cache没有命中时,可以考虑通过raft环各自的索引访问底层存储。其中,cache上的热数据筛选的设计可以引入机器学习算法,提升查询命中率。此外,索引的设计上是否也可以考虑现今的大规模检索技术。
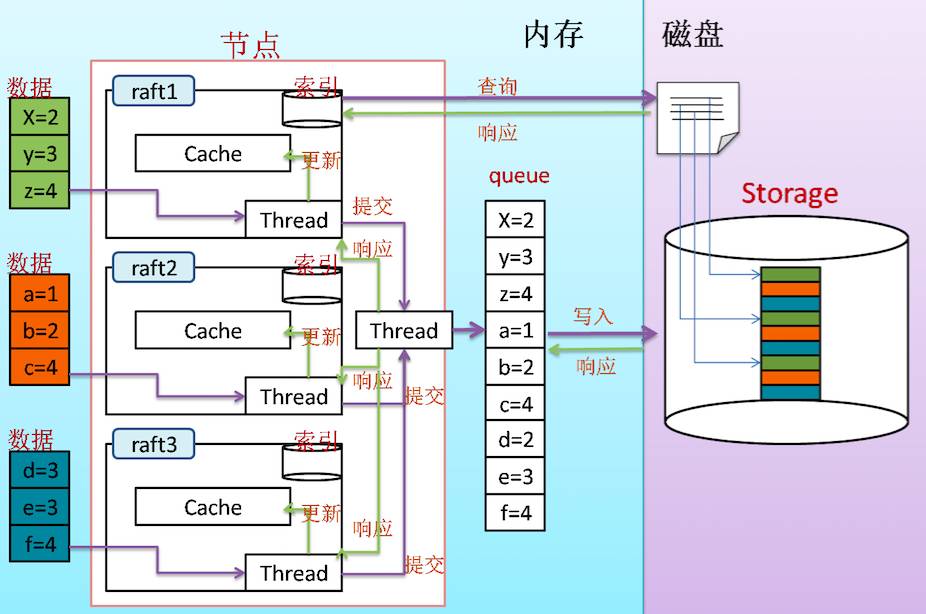
引入机器学习算法解决建议选主,提升raft数据同步性能,当前leader和follower的数据同步是通过心跳模式进行收发的。在raft一致性算法实际运行过程中,我们发现通过随机选举出来的leader在运行过程中,某些时候并不一定是最理想的leader(数据同步失败较多),这萌生了建议选主的想法。进而考虑引入人工智能的策略。主从心跳发送和响应可以记录下通信的传输时间(表示主从间的通信质量),考虑对raft不加入过多外部干预的情况下,通过将leader中获取的这些数据同时发送给monitor,由monitor在收集到一定数据量的信息时,利用人工智能算法预测出当前环境中最佳的leader候选。
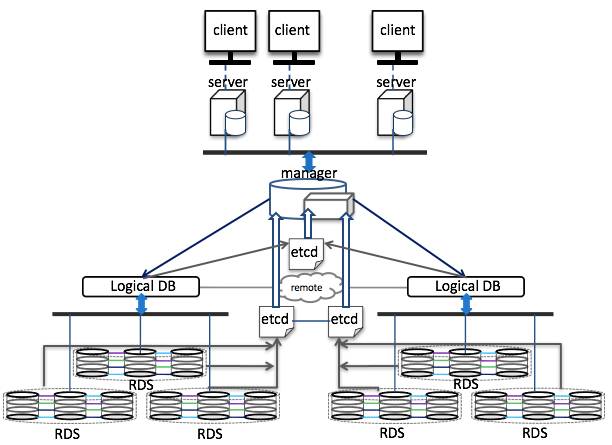
下期如有机会,将会介绍下分布式数据库的时间生成算法,包括google的原子钟及规避读写冲突的技巧和HLC混合逻辑时钟原理及应用。最后福利,附上一张基于Raft算法的数据库架构图(底层的RDS是通过Raft实现):
参考文献
F.Ricci, L.Rokach, and B.Shapira, Introduction to recommender systemshandbook. Springer, 2011.
http://dblp.uni-trier.de/pers/hd/z/Zhang:Zhihua
D. Park, J. Neeman, J. Zhang, S. Sanghavi, and I. S. Dhillon, “Preferencecompletion: Large-scale collaborative ranking from pairwise comparisons,” ICML,
https://raft.github.io, Raft Consensus Algorithm
作者简介:
特注:
本篇由宋强投稿专知发送,欢迎各位行业技术专家投稿专知,分享您的技术与观点!
Email:zhuanzhi2017@outlook.com; 或者扫描以下小助手联系!
请加入AI创作者计划,了解更多!
欢迎转发分享到微信群和朋友圈!
请扫描小助手,加入专知人工智能群,交流分享~

获取更多关于ACM Multimedia 2017的资料,以及机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!
展开全文



