微软-少标签样本构建高性能文本分类器
Robert Horton、Mario Inchiosa和Ali Zaidi演示了如何使用三种先进的机器学习技术-从经过训练的语言模型中迁移学习、主动学习(Active learning)以更有效地利用有限的标签样本,以及超参数调优以最大限度地提高模型性能。
作者 | Robert Horton、Mario Inchiosa、Ali Zaidi
编译 | Xiaowen

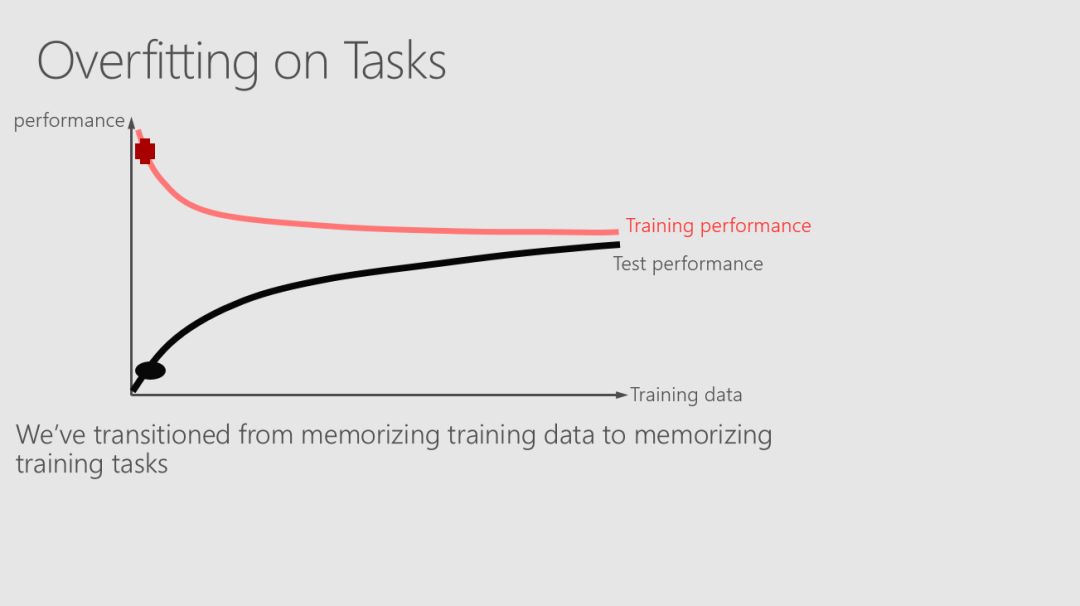
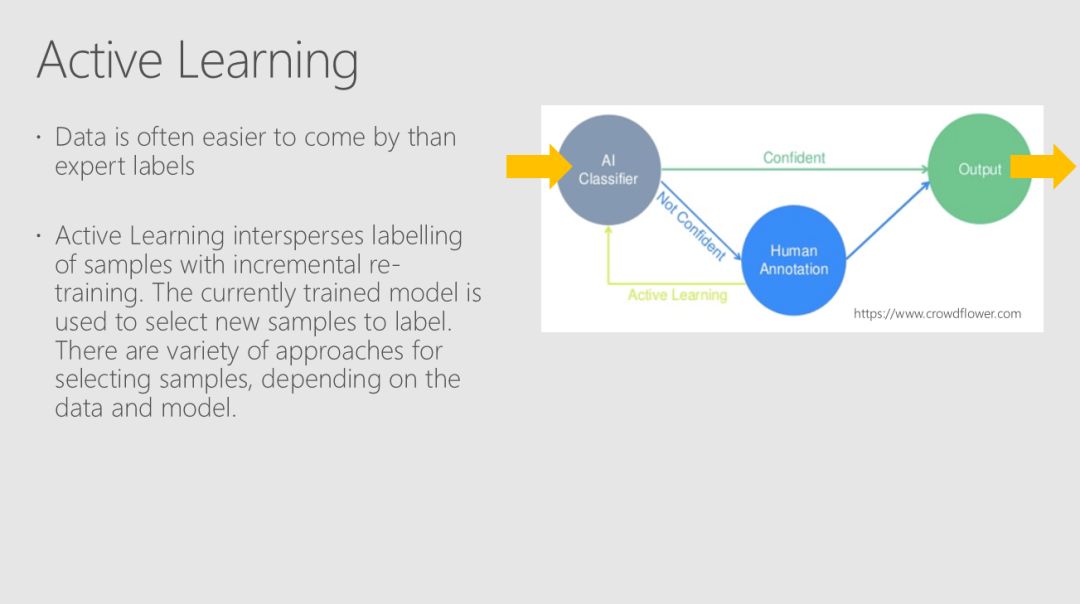
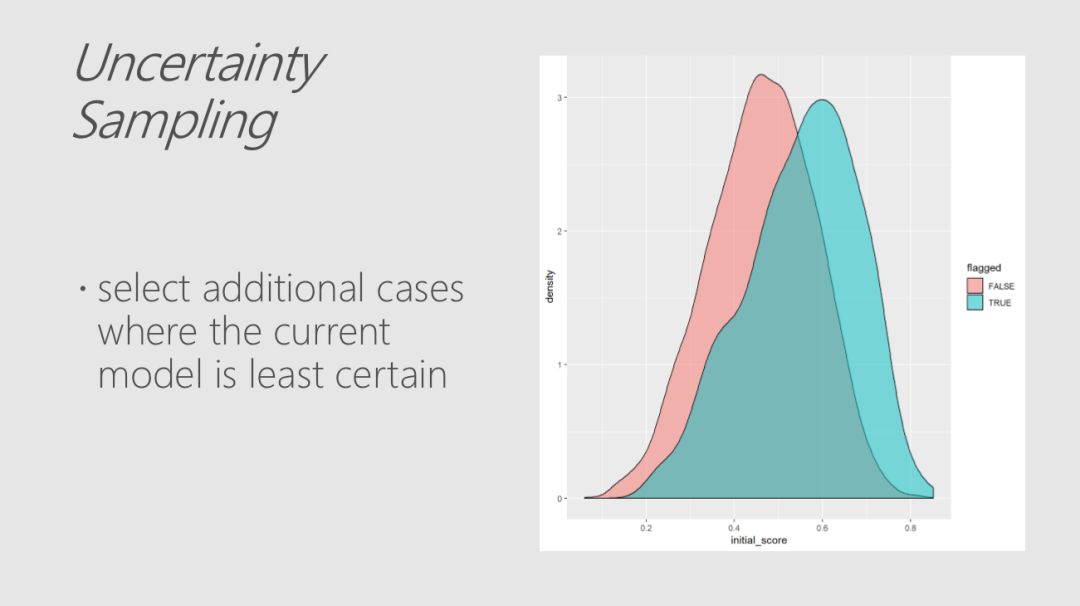
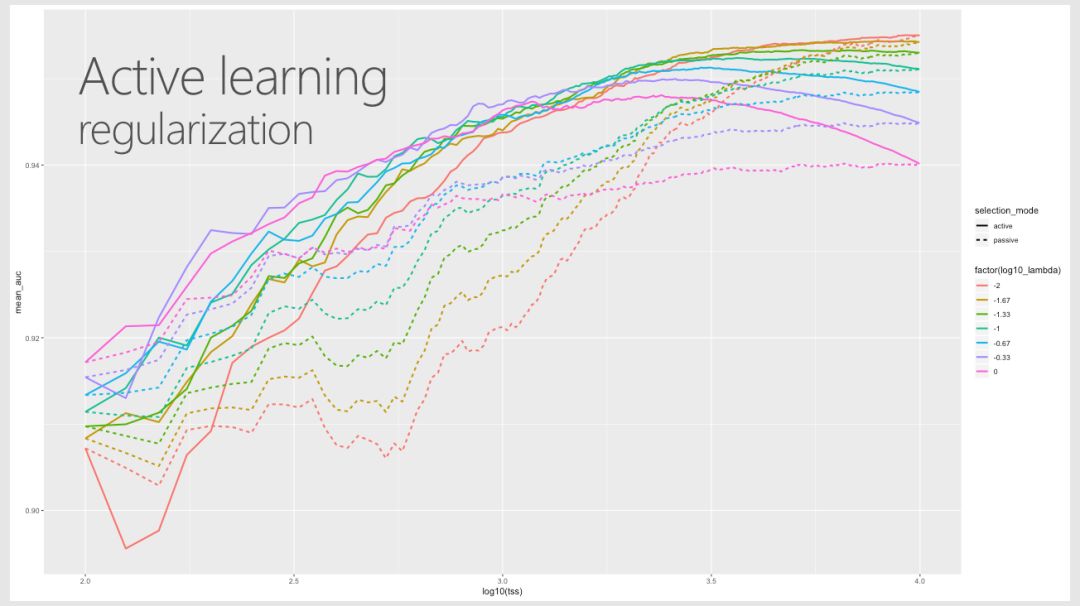
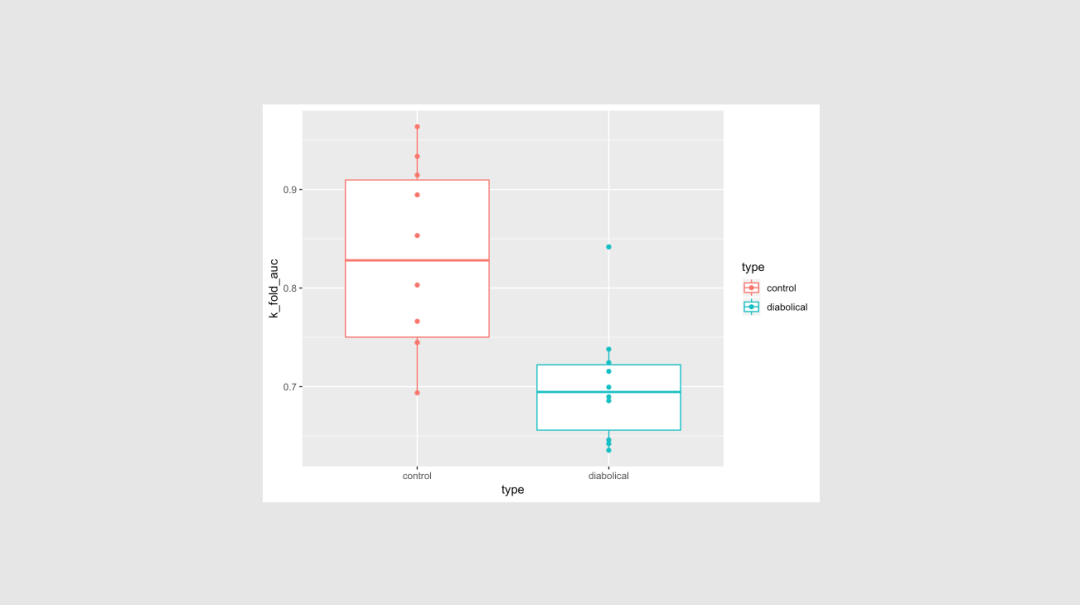
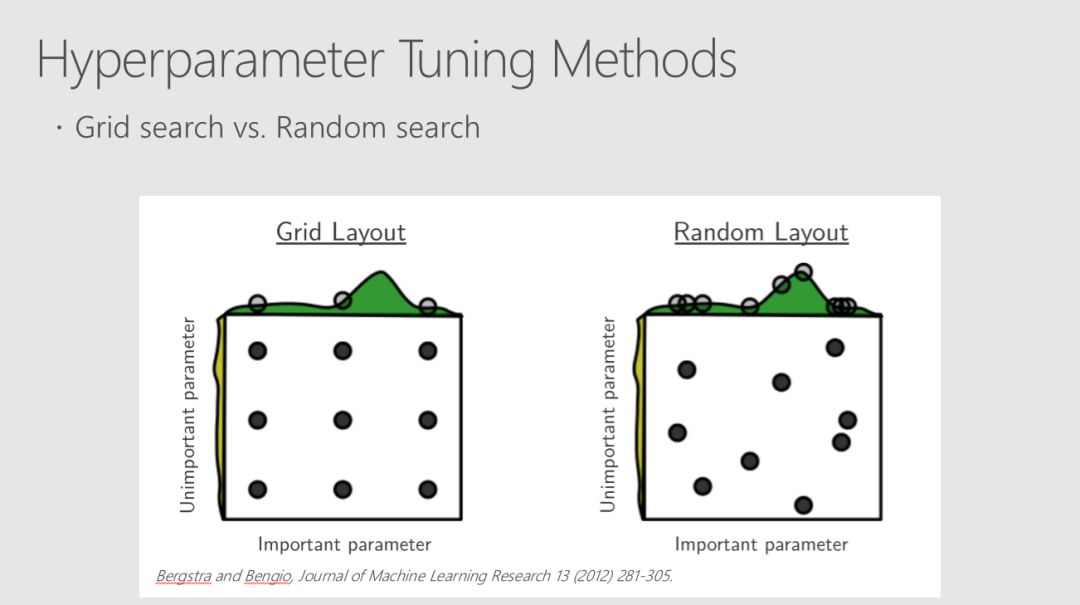
尽管在许多领域都有大量的数据可用,但应用有监督的机器学习技术的限制因素往往是有用标签的可用性。标签通常代表人类解释一个例子的表示,而获得这类标签的代价可能很高,特别是在专家报酬很高或很难找到的应用领域。主动学习是一个模式驱动的选择过程,有助于更有效地利用标签样本。
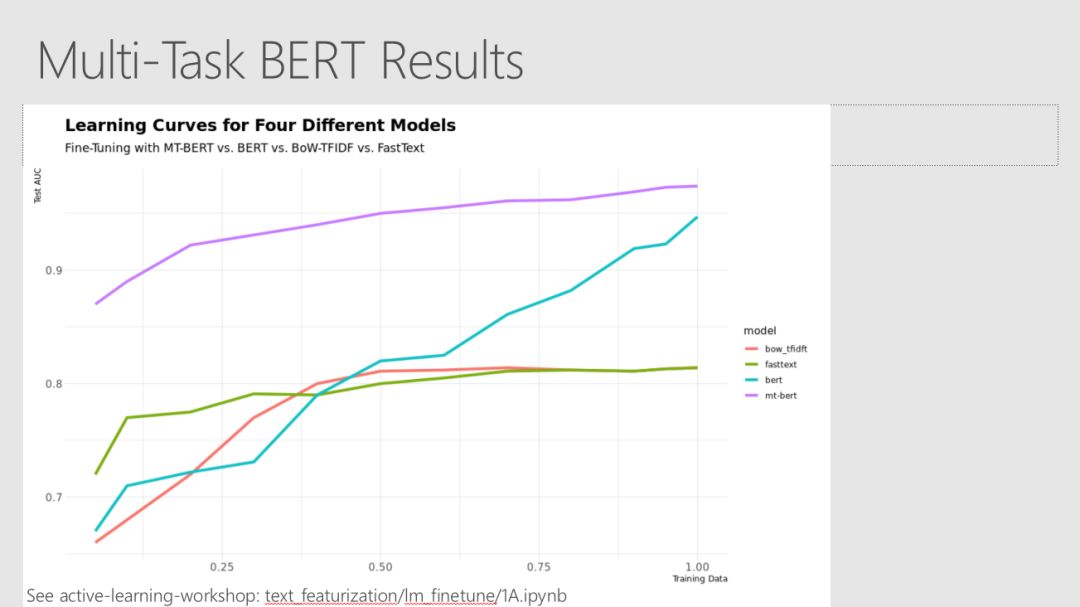
Robert、Mario和Ali从构建一个小数据集的模型开始,然后使用该模型来选择要标记的其他示例。使用多轮建模和选择,你可以从随机选择的类似大小的数据集中获得比预期要好得多的培训集,从而获得性能更好的模型。
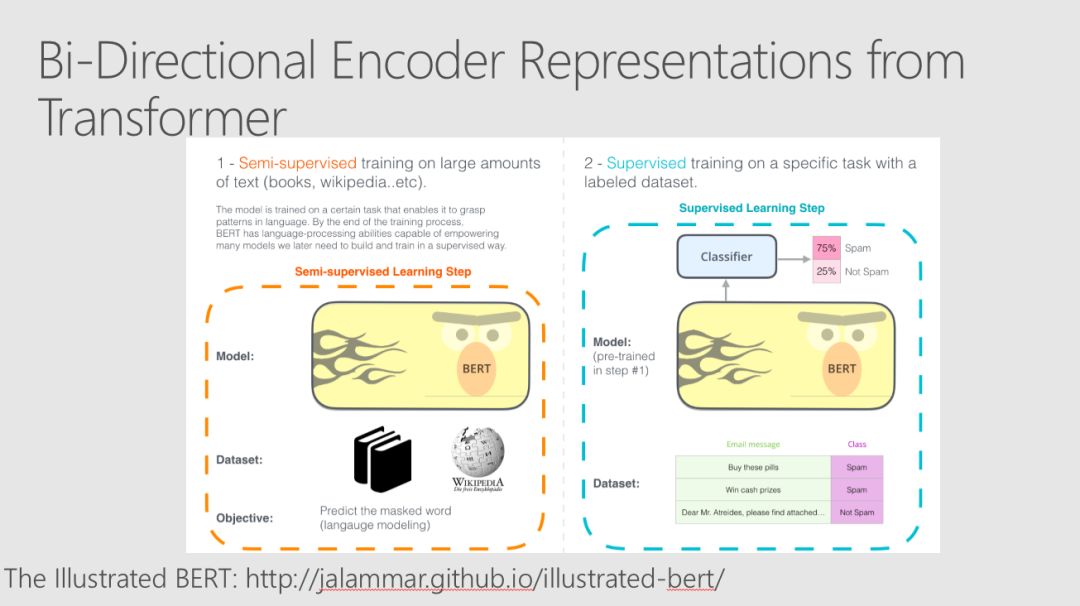
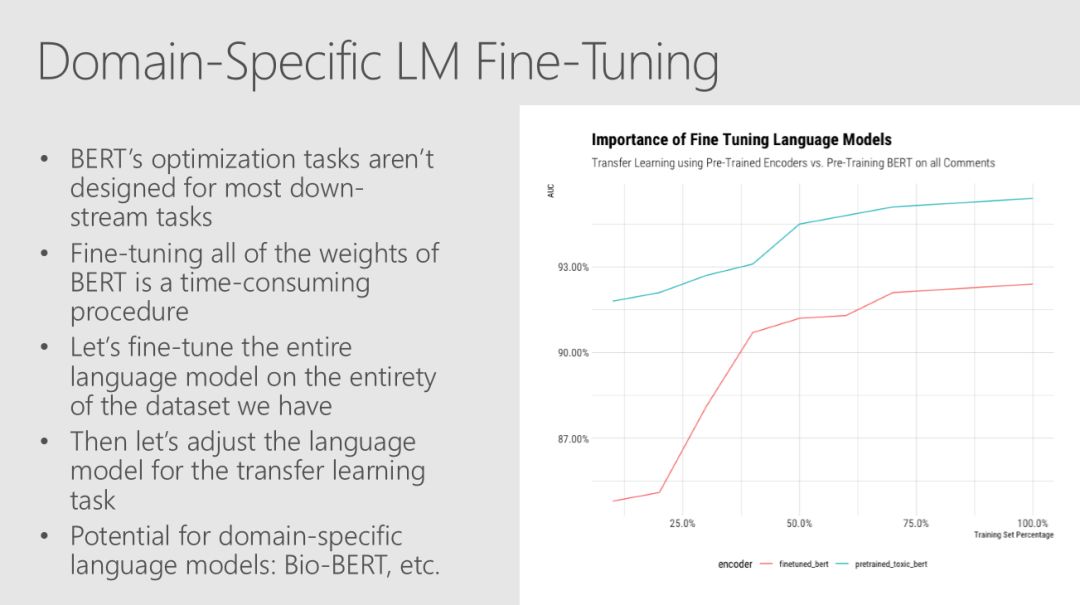
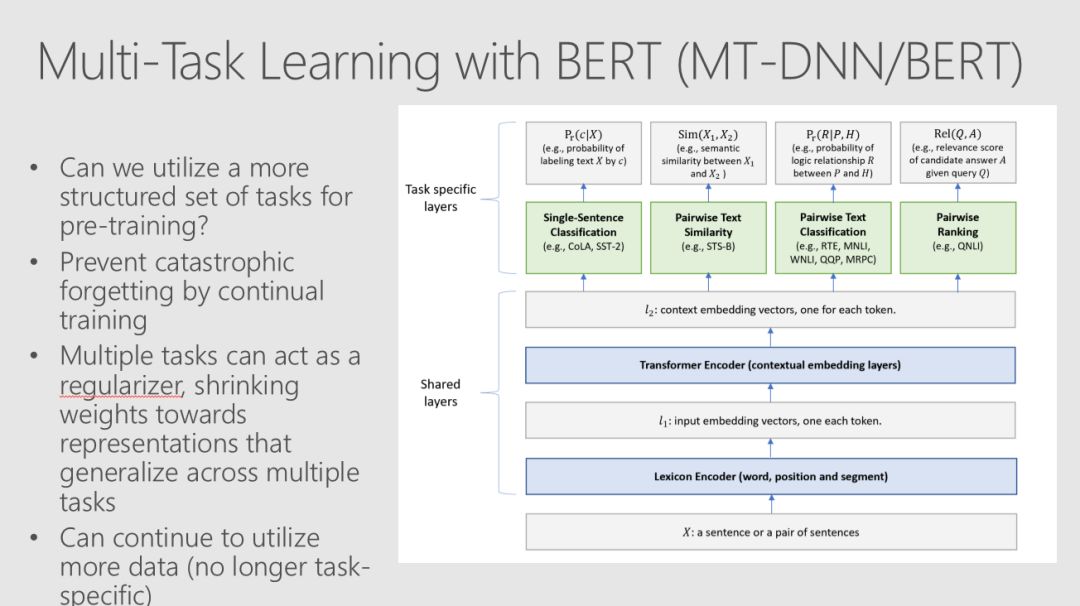
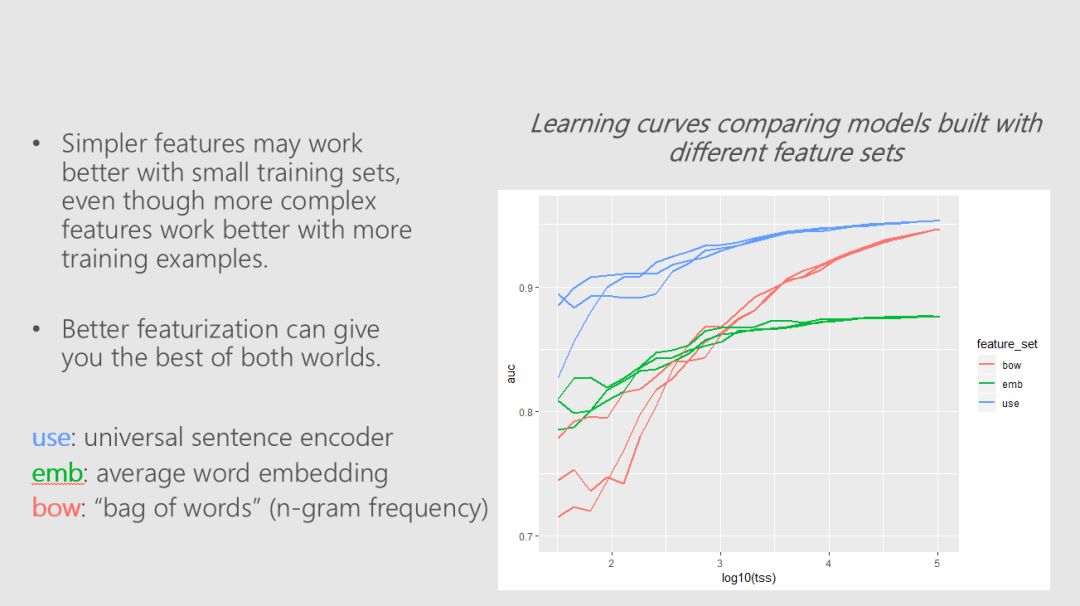
许多state-ot-the-art自然语言处理的结果依赖于使用复杂的模型和大型数据集来学习丰富的表示。Robert、 Mario和Ali的例子使用了经过预处理的语言模型中的迁移学习来生成特征,这些特征可以被能够对相对较小的数据集进行训练的低复杂度分类器模型有效地使用。
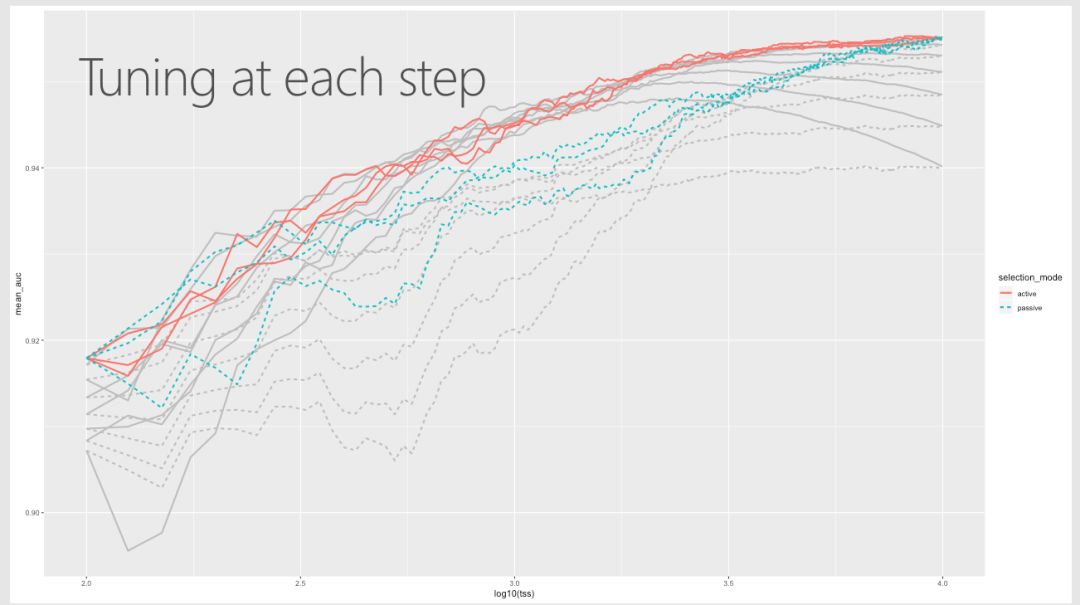
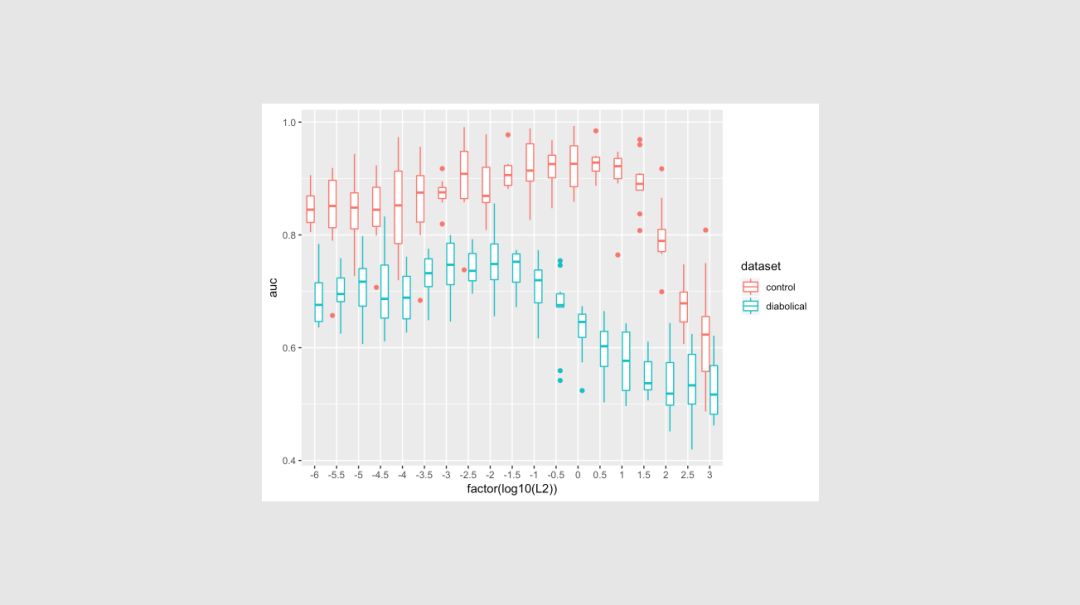
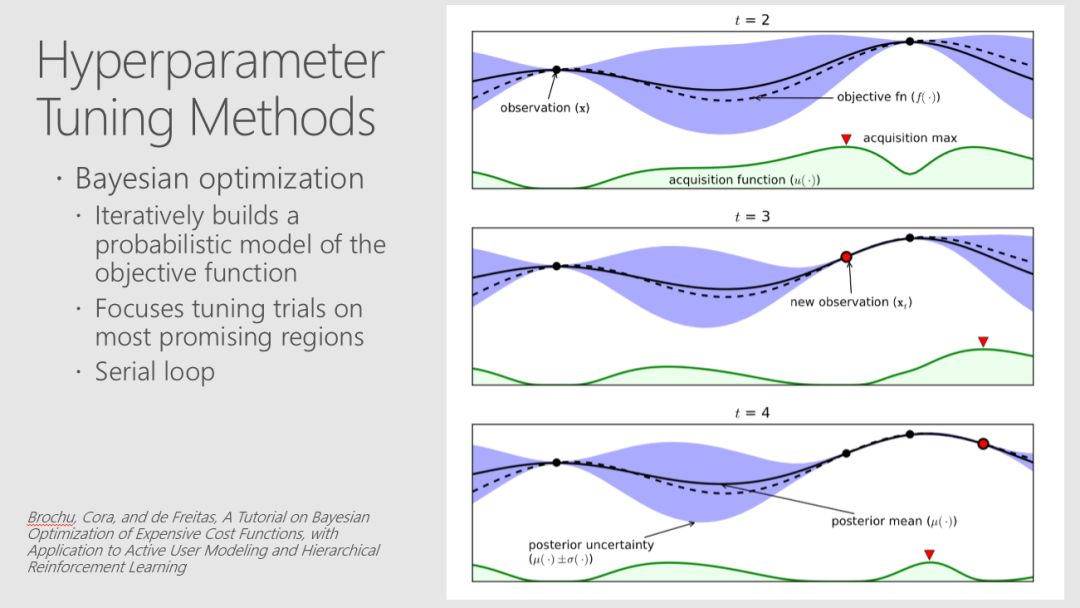
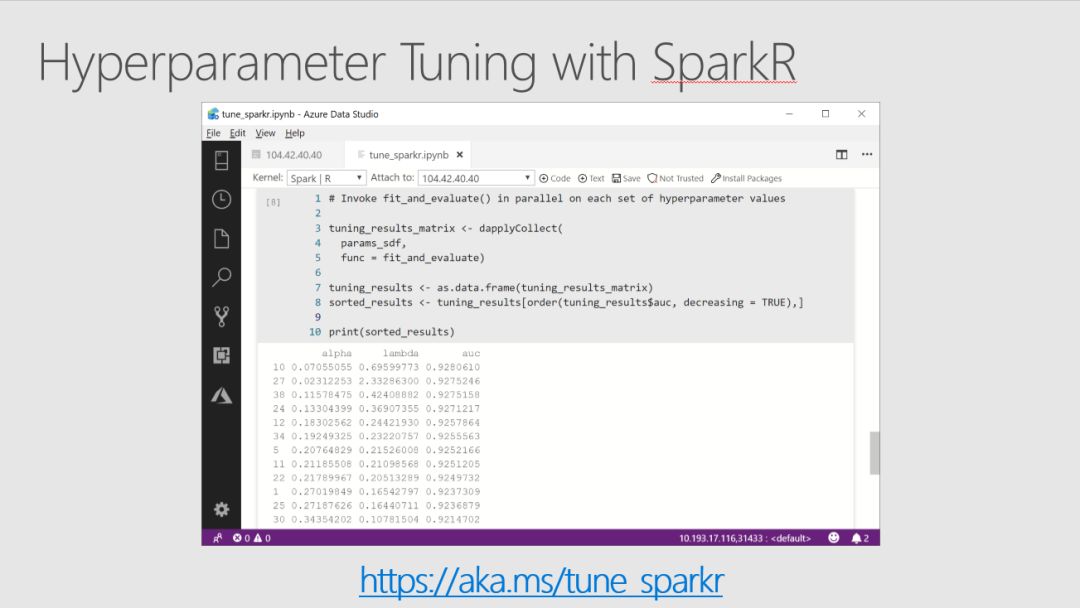
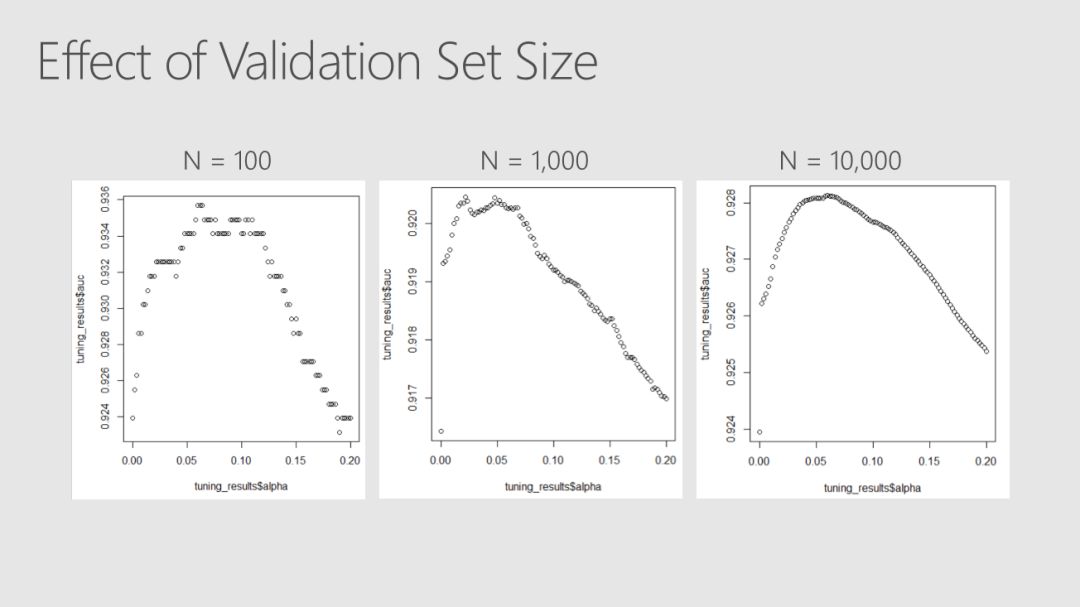
当你将机器学习和人工智能集成到业务流程中时,即使是预测性能的微小改进也可以转化为巨大的ROI,因此,超参数调优现在是许多ML pipline 中固有的一部分。Robert、Mario和Ali解释了如何利用Azure Databricks等平台中的Spark clusters来执行超参数优化,并详细介绍了此调优在分类器中产生的改进。
1
作者介绍

Robert Horton
Robert Horton 是微软知图谱表团队的高级数据科学家,负责分析客户数据并帮助设计和评估知识抽取的方法。另,担任旧金山大学健康信息学兼职教授。

Mario Inchiosa
Mario Inchiosa 是微软的软件工程师,他专注于可扩展的机器学习和人工智能,从哈佛大学获得物理学学士、硕士和博士学位。他获得了4项专利,发表了30多项研究论文,出版了两本著作。

Ali Zaidi
Ali Zaidi 是加州大学伯克利分校的统计学博士。以前他是微软AI和Research Group的数据科学家,在那里他致力于使云分布式计算和机器学习更容易、更高效。
Slides 分享
2
【Slides便捷下载】
请关注专知公众号(点击上方蓝色专知关注)
后台回复“少标签文本分类” 就可以获取《Building high-performance text classifiers on a limited labeling budget》的下载链接~













-END-
专 · 知
专知《深度学习:算法到实战》课程全部完成!520+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询《深度学习:算法到实战》课程,咨询技术商务合作~

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



