【干货】2017最火的五篇深度学习论文 总有一篇适合你
【导读】最近,MIT博士生学生GREGORY J STEIN在博客中总结了2017年他最喜欢的深度学习论文,并且列出了这一年对他研究思考影响最深的五篇论文,其中包括《CycleGAN, Deep Image Prior,苹果的simGAN, Wasserstein GAN, AlphaGo zero》,并且详细地解释了为什么会选择这篇论文的原因,值得大家细细品味!专知内容组编辑整理。

MY FAVORITE DEEP LEARNING PAPERS OF 2017
2017年我最喜欢的深度学习论文
虽然今年发表的深度学习相关的论文多如牛毛,但是仍然有些论文因其独特的贡献而脱颖而出。 下面是过去一年对我的研究思考影响最多的五篇论文。 对于每篇论文,我都解释了论文的要解决什么问题,简要总结了论文主要的创新点,并说明我觉得它很有趣的原因。
▌1. 最酷的视觉效果: CycleGAN-图像迁移
题目: Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
作者: Jun-Yan Zhu, Taesung Park, Phillip Isola, Alexei A. Efros (来自伯克利AI研究所)
目标:自动将某一类图片转换成另外一类图片。
链接:https://arxiv.org/abs/1703.10593
与其上来就说一大堆这篇论文里所做的那些技术细节,不如让我们先来看看这些令人难以置信的结果:

(旁边的注释):这些令人惊人的图像来自CycleGAN论文,作者在这篇论文中训练了一对转换网络,能够在不同类的图像集之间进行转换。
作者用来自不同领域的两组图像举例,例如普通的马和斑马。他实现了两个转换网络:其中一个将马的图像转化为斑马图像,另一个将斑马图像转化为马图像。每个转换器都实现一种样式转换,它不是针对单个图像的样式,而是去发现一组图像的聚合样式。
转换网络被训练成一组生成对抗网络GAN,每个网络都试图欺骗鉴别者相信他们“转换”的图像是真实的。另外引入了循环一致性损失函数(cycle consistency loss)来保证在通过两个转换网络之后图像保持不变。

(旁边注释)我们使用CycleGAN方法为我们最近的一篇论文在训练数据上生成逼真现场合成图像,结果看起来很炫:
这篇论文的视觉效果令人惊叹,我强烈建议您去GitHub上多看些转换示例。 我对这篇论文尤其感兴趣,因为它不像许多以前的方法,它学会在不同类的图像集之间进行转换,为可能不存在匹配图像或者图像难以获得的应用程序打开大门。除此之外,代码非常易于使用和实验,这也说明了方法的鲁棒性和高质量的代码实现。
▌2. 最优雅:使用WASSERSTEIN 距离更好地进行神经网络训练
标题:Wasserstein GAN
作者:Martin Arjovsky,Soumith Chintala,LéonBottou(来自Courant数学科学研究所和Facebook人工智能研究)
目标:使用更好的目标函数来更稳定地训练GAN。
链接:https://arxiv.org/abs/1701.07875
本文提出了通过使用一个稍微不同的目标函数来训练生成敌对网络。新提出的目标函数比标准GAN的目标函数训练起来要稳定得多,因为它避免了在训练过程中消失梯度。
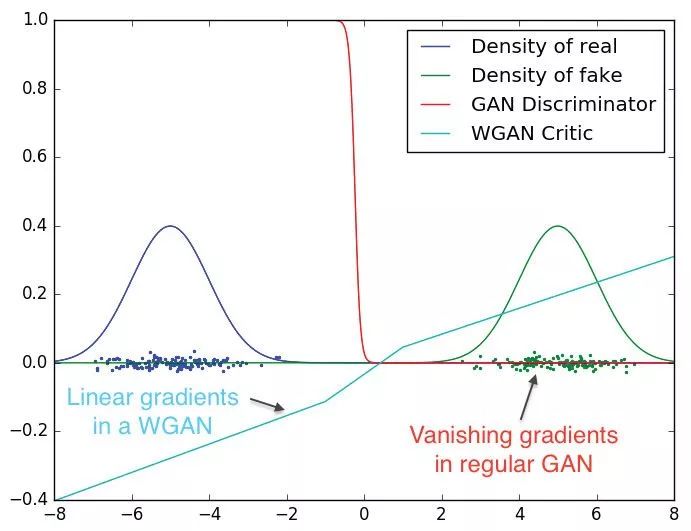
(旁边注释)从Wasserstein GAN论文中摘得的这个图片显示了所提出的WGAN目标函数如何避免出现在标准GAN中的梯度消失的问题。
使用这个修改后的目标函数,作者还避免了一个称为模式崩溃mode collapse的问题,在标准GAN中,这个问题体现为只从可能输出的一个子集中产生样本。 例如,如果GAN正在训练产生手写数字4和6,则GAN可能只能产生4,并且在训练期间无法逃离该局部最小值。Wasserstein GAN通过解决训练目标中梯度的消失来设法避免这个问题。
(旁边注释)事实上,作者声称:“我们还没有在实验中看到过WGAN算法模式崩溃的证据。”
这篇论文是非常自成体系的:
(1)作者首先提出一个简单的想法
(2)从数学上解释为什么它可以提高当前结果
(3)用一个令人印象深刻的结果去证明它的有效性。 此外,作者提出的改变在几乎所有流行的深度学习框架中都很容易实现,使得所提出的改变是切实可行的。
(旁边注释)即使我们一直在朝着神经网络越来越好的方向前进,但值得记住的是,仍然有可能通过简单的改进来产生巨大的变化。
▌3. 最有用的:simGAN---使用GAN进行无监督模拟训练数据细化
标题:Learning from Simulated and Unsupervised Images through Adversarial Training 通过对抗训练从模拟和无监督的图像中学习
作者:Ashish Shrivastava,Tomas Pfister,Oncel Tuzel,Josh Susskind,王文达,Russ Webb(苹果公司 CVPR 2017 best paper)
目标:利用真实数据来“修正”合成数据的数据分布,从而使得人工合成的图片可以用来训练
链接:https://arxiv.org/abs/1612.07828
收集真实的数据可能既困难又耗时。因此,许多研究人员经常使用仿真工具(类似于OpenAI gym的工具对尤其需要大量训练数据的深度强化学习代理特别有用),其能够产生几乎无限量的有标签训练数据。然而,大多数模拟数据对于在真实数据上操作训练的深度学习系统是不够鲁棒的。
为了克服这个限制,本文基于生成对抗网络(GAN)使用未标记的真实图像来改进标记的模拟图像。它们训练一个“refinement network”来欺骗一个判别器,该判别器被训练成能够区分细致的模拟图像和真实图像。由于refinement network和分类器是联合训练的,细致的模拟图像开始显得非常逼真:
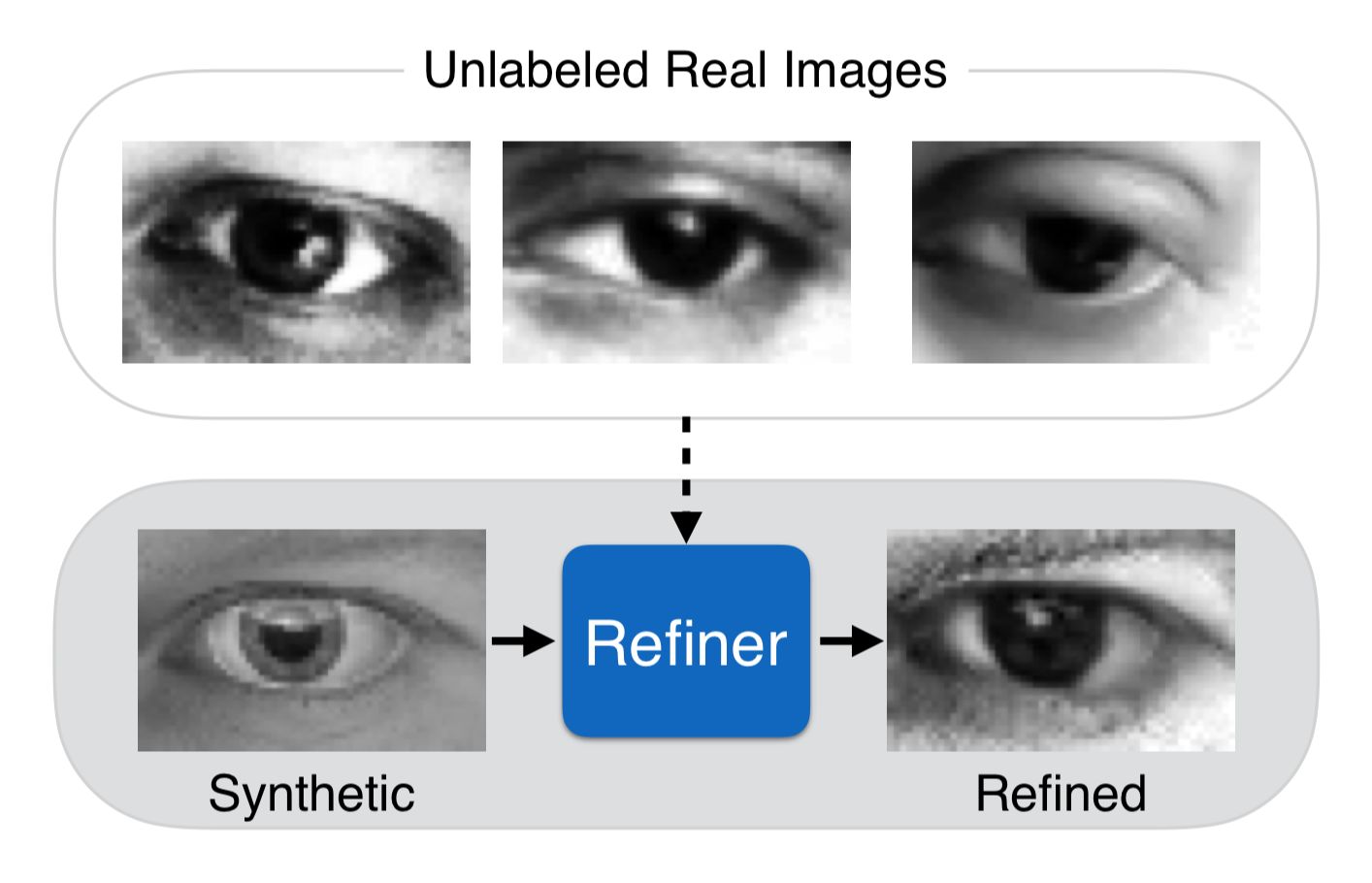
当simGAN被提出来时,我立即对这篇论文感兴趣,因为它提出了第一个缩短模拟和真实数据差距的实用方法。关键的是该算法是无监督的,这意味着用户不需要手动标记真实数据。对于深度学习应用来说,数据是最重要的,然而像我这样的大多数学术实验室没有资源来生成快速解决新研究领域问题所需的大量数据:如果您正在尝试解决的问题不存在公共数据集,则你将自己收集和标记该数据。 本文的言外信息是,只要你有一个试图解决问题的模拟器,你应该能够生成你所需要的训练数据。
▌4. 最引人关注的是:谷歌的围棋AI无需人类经验的学习
标题:在没有人类知识的情况下掌握Go游戏
Mastering the game of Go without human knowledge
作者:David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton, Yutian Chen, Timothy Lillicrap, Fan Hui, Laurent Sifre, George van den Driessche, Thore Graepel & Demis Hassabis (from DeepMind)
目标:在没有任何人类知识的情况下学会玩围棋游戏
链接:https://www.nature.com/articles/nature24270
如果缺少DeepMind在过去一年中取得的惊人成就,那么2017年的最佳名单将是不完整的,特别是考虑到DeepMind在AI围棋程序AlphaGo的成绩。我在这里就不花过多的篇幅称赞他们的成就了,因为你们中大多数人可能对DeepMind在2016年的成果,包括他们在论文中是如何构建系统的,都非常熟悉。然而,2017的这个系统是以专家级的人类围棋作为起点。
最近的“AlphaGo zero这篇论文没有使用任何人类的先验知识或对弈棋局: 只通过“自己对弈(self-play)”来进行训练。这是通过改进的强化学习过程实现的,在这种训练过程中,策略被更新为对比赛的前向模拟(forward simulations)。用于引导搜索的神经网络在游戏中得到改善,使训练速度更快。AlphaGo zero超过了AlphaGo Lee的表现,在2016年的比赛中,只通过40个小时的“自我对弈”学习,就击败了李世石(Lee Sedol)
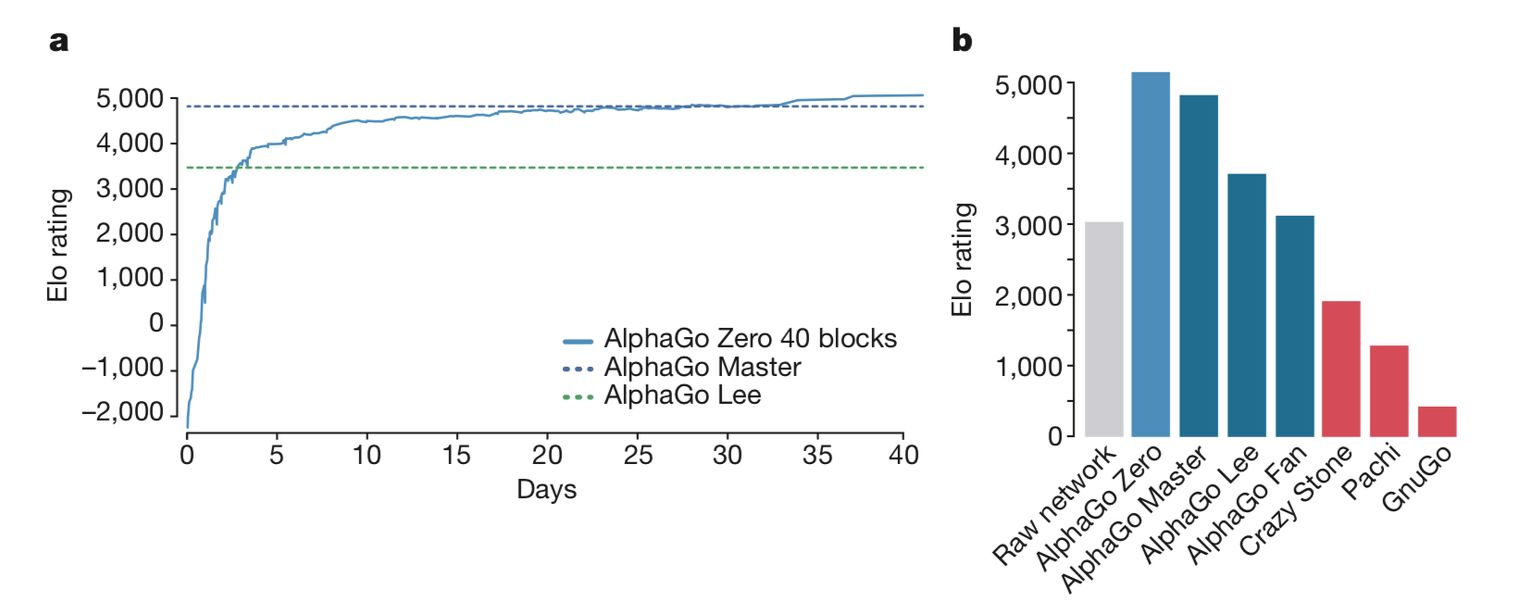
这张摘自AlphaGo Zero论文的图表,图显示了AlphaGo Zero的性能。 经过几个星期的训练,AlphaGo Zero胜过所有其他围棋程序。
尽管我对这篇论文的兴趣主要集中在工程层面,但AlphaGo采用的传统方法和深度学习方法的混合方法也很令我兴奋,在这种方法中,增加的蒙特卡洛树搜索使得系统性能优于单独的神经网络方法。因为我本身研究机器人,对这种方法情有独钟:使用传统算法作为决策的主体,并使用机器学习来提高性能或克服计算限制。这篇论文和2016 AlphaGo论文写的都很棒,技术细节和见解都非常到位。这些文章值得详细阅读。
▌5. 最值得思考的是:深度图像先验Deep Image Prior
标题:深度图像先验(Deep Image Prior)
作者:Dmitry Ulyanov, Andrea Vedaldi, and Victor Lempitsky (from Skolkovo Institute of Science and Technology and University of Oxford)
目标:理解神经网络模型中先验的作用
链接:https://dmitryulyanov.github.io/deep_image_prior
在完成这个2017年论文清单时,我发现一个比较有趣的论文,关于这篇论文我和我的同事聊了好几天。这篇文章的作者并没有用大量的数据来训练深度神经网络,而是探索如何使用神经网络本身作为先验来帮助我们处理一些流行的图像处理任务。从一个未训练的神经网络开始,用作者的话来说“在神经网络的参数空间中搜索答案,而不是在图像空间中搜索答案”,并且避免将大型数据集中预训练神经网络。
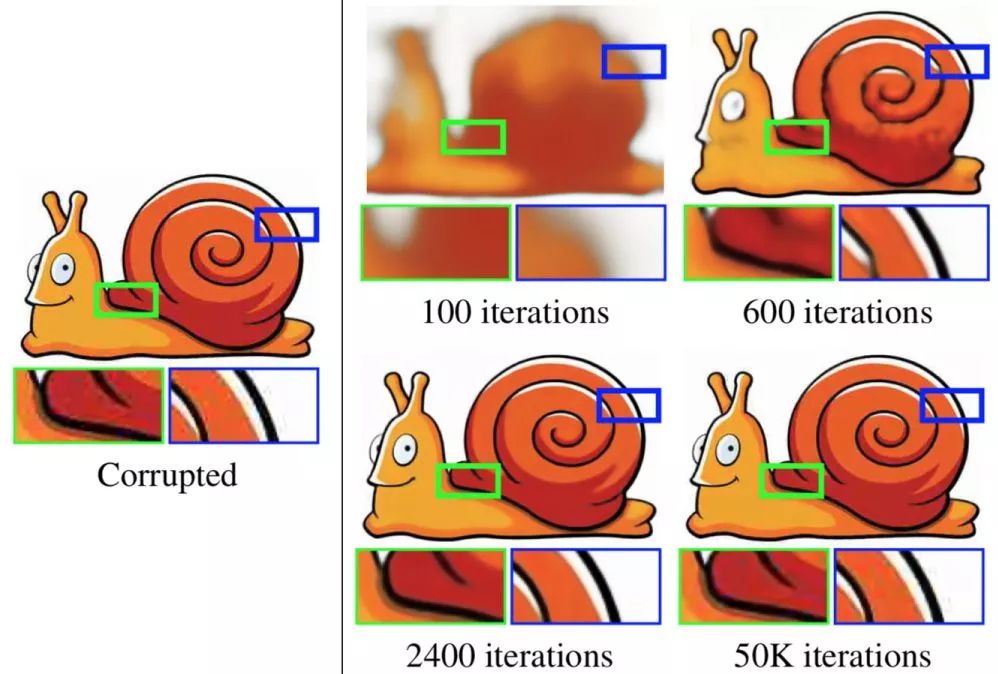
上图中的图片摘自深度图像先验的论文(Deep Image Prior paper),图中展示了应用他们的技术移除JPEG压缩伪影的效果。最左边是目标图像,它经过JPEG压缩,有很多压缩瑕疵。网络的目标是学会输出它。在100次迭代后,网络学会了输出很模糊的形体。在2400次迭代后,网络学会了输出一张清晰光滑的高质量图片。在50000次迭代后,网络才学会了输出原图,但是在此之前会首先发现没有任何伪影的更自然的图像; 网络的结构是找到一个更自然的图像比找到一个损坏的图像更容易。更多例子可以查看论文项目的页面(https://dmitryulyanov.github.io/deep_image_prior )。
我几乎是立刻被这个结果吸引:神经网络结构对于我们的数据是有哪些先验的认识?我们怎样才能更好地理解这些先验呢?我们如何利用这种方法来建立更好的网络模型?当然,我们可以隐约地感受到我们的网络结构可能也会对我们的数据造成的一些限制:比如把“斑马”的图像都被颠倒了,那么CycleGAN方法可能不会有效地工作。这也给我们的神经网络模型带来挑战,同时提供了一些未来研究方向。
▌结论
很明显,本文总结的列表并不全面,我欢迎您评论并举出您喜欢的文章。
参考链接:
http://cachestocaches.com/2017/12/favorite-deep-learning-2017/
http://gjstein.me/
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



