【香港科技大学】联邦半监督学习综述,A Survey on Federated Semi-supervised Learning

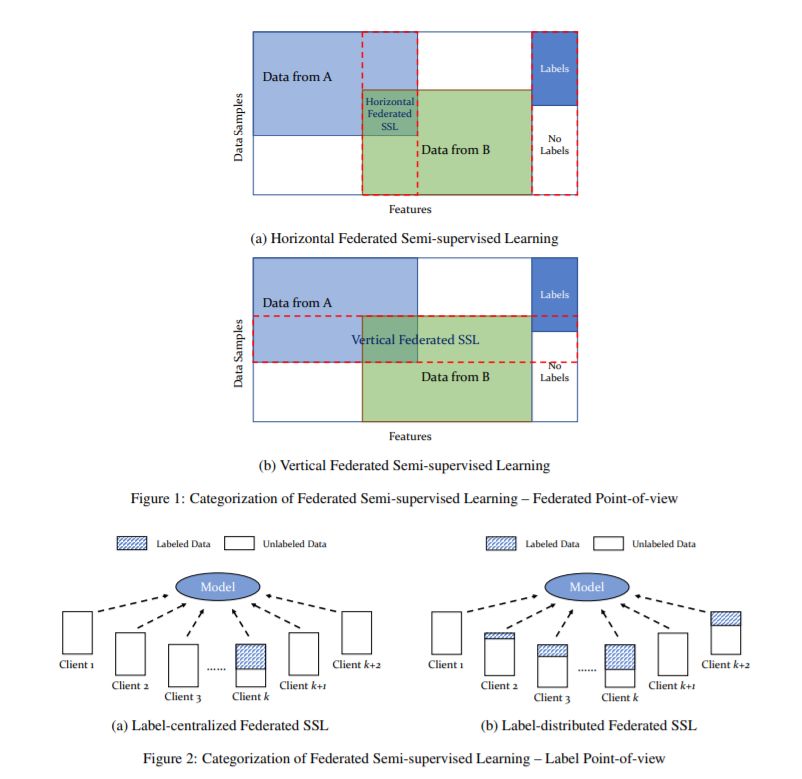
人工智能(AI)的成功应该在很大程度上归功于丰富数据的可获得性。然而,实际情况并非如此,行业中的开发人员常常面临数据不足、不完整和孤立的情况。因此,联邦学习被提议通过允许多方在不显式共享数据的情况下协作构建机器学习模型,同时保护数据隐私,来缓解这种挑战。然而,现有的联邦学习算法主要集中在数据不需要显式标记或者所有数据都有标记的情况下。然而在现实中,我们经常会遇到这样的情况,标签数据本身是昂贵的,没有足够的标签数据供应。虽然这类问题通常通过半监督学习来解决,但据我们所知,联邦半监督学习还没有投入任何努力。在这项调查中,我们简要地总结了目前流行的半监督算法,并对联邦半监督学习做了简要的展望,包括可能的方法、设置和挑战。
地址:
https://arxiv.org/abs/2002.11545
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“FSL” 就可以获取《联邦半监督学习综述,A Survey on Federated Semi-supervised Learning》论文专知下载链接



展开全文



