【干货】IRGAN :生成对抗网络在搜狗图片搜索排序中的应用
点击上方“专知”关注获取专业AI知识!
https://zhuanlan.zhihu.com/p/31373052
一:背景
2014年,GAN之父Ian Goodfellow在一篇文章《Generative Adversarial Nets》 中提出对抗生成网络(GAN),一时引起轰动。自此之后,许多专家学者投身于Gan理论研究与探索,并在多个领域取得丰硕成果。比较有名的是在图像上的应用,其中以图生图,任务可以简单理解为通过对真实图像进行学习,让计算机生成逼真的图像。还有的学者试图探索Gan在自然语言处理方面的应用,比如以文生文,即文本生成被应用于chatbot,还有以文生图,以图生文等任务场景。
2017年Sigir 一篇《IRGAN: A Minimax Game for Unifying Generative and Discriminative Information Retrieval Models》, 提出了GAN另一种可能的应用,那就是信息检索。信息检索的目的就是针对用户输入的Query,返回给对方一个合适候选文档列表。论文将目前IR领域的研究分为两大流派,一种是经典的思维流派,主要的思想是产生一个用户查询与文档之间的关联分布,并通过建立统计学习模型得到综合打分,给出合适的检索结果。一种是现代流派,现代流派通过利用机器学习思想,将IR任务转化为学习排序任务。可以看到近几年各大排序模型被相继提出,逐渐形成一个体系,笔者另一篇文章《Learning To Rank 研究与应用》中,主要阐述的就是现代流派中主流的检索排序算法。
前面提到的两大流派都有各自的优势,也有各自的缺点。IRGAN的作者做了一种尝试,就是将两种流派思想分别对应到GAN模型学习的生成器与判别器上,试图相互补充。
毕竟是17年Sigir满分论文,还是满怀期待的读了好几遍,也相应的做了一些实验探索,后面将介绍一下对于笔者对于原理的理解以及实践心得。
二:原理
首先关于GAN本身的原理,大致如下面的框图。
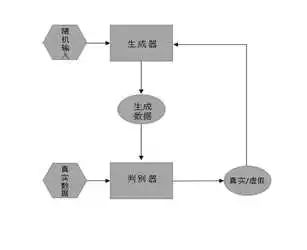
论文利用GAN思想中的博弈论原理,将任务变换成模型极大极小算法求解问题。假定对于某个查询来说,有一批已经确定符合查询结果的文档列表,暂且称它们为已观测正样本,其实就是有标签数据。对于其他的返回的候选结果,称它们为未观测样本,就是无标签数据。
生成模型作用:从给定的查询候选池中选择最接近已观测样本分布的未观测样本。这里要特别说明一下,其实在GAN的原理里面,生成样本是通过学习已知样本的分布,去真正生成一个样本。而在LTR-GAN任务中,则通过对学习选择那些最优的未观测样本来作为生成样本,也就是说,这个生成的样本本身已经存在,只是之前没有标签而已。这是由排序任务特定场景造成的。
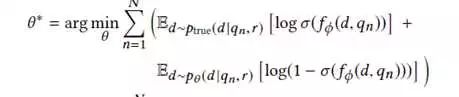
所以生成模型主要的优化目标就是最小化已观测样本与生成样本之间的差距。
判别模型作用:对于给定的样本集合,尽量准确的区分已观测样本与未观测样本。所以优化的目标就是最大化已观测样本和生成样本之间的差距。当然这些未观测样本中可能有正样本,可能有负样本。
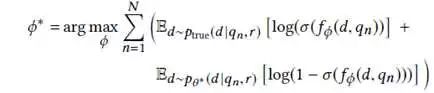
所以综合上面两个模型特点,最终的优化目标是:
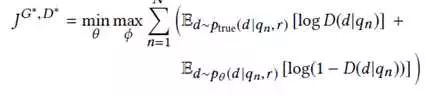
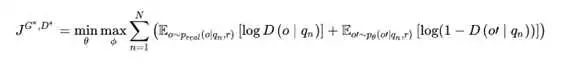
其中,o表示真实的非对称二元组,而 o’则表示生成式IR模型生成的二元组。
最终的训练过程如下:

有了这个预训练的生成器模型作为初始化模型,进行生成器和判别器的迭代训练。若干轮之后,得到最终的模型。最终判别模型和生成模型都可以拿来作为最终排序模型,具体看不同的任务效果。在IR检索任务背景下,判别模型的效果要好一些。
作者还用了小球漂浮的例子说明GAN的排序机制,但我觉得这种比喻反而更让人难懂。
三:实战
最开始是用论文公开的数据集做实验,即半监督数据集,论文中用的数据集大小为784个Query,每个Query 有5个正样本,以及1000个未标注样本。训练集和测试集的比例是4:1。这里说一点,与LTR任务中不同的是,不再对文档进行3分制,或5分制这样区别,而是用了2分制,意思就是打分大于0 的,统一为正样本,小于或等于0 ,以及没标签的的,统一为负样本。
参照着论文里面的数据集构造方式训练了一把。发现最终训练的结果指标与论文出入不大,确实如论文所说,评测指标要超过Lambdamart。
接下来就是利用自己的真实检索数据进行了实验,主要分为四个实验。
第一个实验就是pairwise和pointwise的效果比对。
数据集规模为:
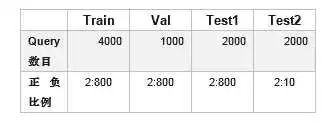
在测试集上的效果为:
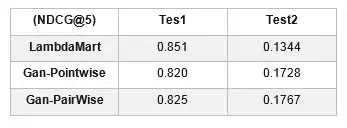
原因就是半监督数据集上将所有无标签数据都当做负样本来对待,而Gan模型就是利用半监督数据去训练的,LambdaMart的训练都是在有监督数据集上进行的,所以Gan在半监督上表现好,而LambdaMart在有监督上表现好。这就涉及到一个问题,即把无标签数据都当做负样本进行评测有没有意义。目前在我这份数据集上来看,这样做肯定是不行的,因为最终的排序效果并不如LambdaMart。
所以分析是否为数据抽样的问题导致,考虑无标签数据都是从top结果中选择的,而top结果有可能一大部分都是正样本,可能导致整个训练方向出现问题。因此,又做了第二个实验,调整抽样策略。
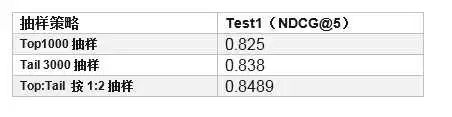
第三个实验:训练LR Pointwise排序模型进行对比。
实验结果:在同等训练集数量情况下,LR ndcg@5达到 0.837
将LR训练集扩大10倍,即由之前的4k Query扩大到4W Query,ndcg@5效果提升到0.8483。
可以看到Gan模型仅用了LR模型 1/10的有标签数据,达到的效果反而略好。
然而这个值仍然比LambdaMart 测试效果0.851 略低,虽然尝试对第三种抽样方式再做多种优化,结果从0.8489 提升到0.850,接近LambdaMart,但没超越。
因此Gan模型在笔者实验条件下未达到预期的效果。
第四个实验:考虑将Gan模型作为一种特征融合策略,加入到LTR训练中。
经实验验证,在Test1上加入Gan特征后,LambdaMart排序效果有显著提升。具体实验细节感兴趣的可以回复交流,不作细讲。
四:结语
Gan在IR上的的试水为这方面的研究者打开了一扇门,虽然几组结论验证IRGAN仍没达到期盼的效果,但是论文提供代码中用到的Gan模型仍是相对简单的,还有很大的优化空间。论文最可贵的是提出的一种排序对抗思想,即将经典流派与现代流派相结合。
特别提示-GAN资料下载:
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“GAN” 就可以获取资料下载链接~
请扫描专知小助手,加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等,或者加小助手咨询入群)交流~

-END-
专 · 知
专知荟萃知识资料全集获取(关注本公众号-专知,获取下载链接),请查看:
【专知荟萃01】深度学习知识资料大全集(入门/进阶/论文/代码/数据/综述/领域专家等)(附pdf下载)
【专知荟萃02】自然语言处理NLP知识资料大全集(入门/进阶/论文/Toolkit/数据/综述/专家等)(附pdf下载)
【专知荟萃03】知识图谱KG知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附pdf下载)
【专知荟萃04】自动问答QA知识资料全集(入门/进阶/论文/代码/数据/综述/专家等)(附pdf下载)
【专知荟萃05】聊天机器人Chatbot知识资料全集(入门/进阶/论文/软件/数据/专家等)(附pdf下载)
【专知荟萃06】计算机视觉CV知识资料大全集(入门/进阶/论文/课程/会议/专家等)(附pdf下载)
更多请点击查看:【专知荟萃】人工智能领域22个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!
请关注我们的公众号,获取人工智能的专业知识。扫一扫关注我们的微信公众号。


点击“阅读原文”,使用专知!
展开全文



