【AlphaGo Zero 核心技术-深度强化学习教程代码实战06】给Agent添加记忆功能
点击上方“专知”关注获取更多AI知识!
【导读】Google DeepMind在Nature上发表最新论文,介绍了迄今最强最新的版本AlphaGo Zero,不使用人类先验知识,使用纯强化学习,将价值网络和策略网络整合为一个架构,3天训练后就以100比0击败了上一版本的AlphaGo。Alpha Zero的背后核心技术是深度强化学习,为此,专知有幸邀请到叶强博士根据DeepMind AlphaGo的研究人员David Silver《深度强化学习》视频公开课进行创作的中文学习笔记,在专知发布推荐给大家!(关注专知公众号,获取强化学习pdf资料,详情文章末尾查看!)
叶博士创作的David Silver的《强化学习》学习笔记包括以下:
笔记序言:【教程】AlphaGo Zero 核心技术 - David Silver深度强化学习课程中文学习笔记
《强化学习》第七讲 策略梯度
《强化学习》第八讲 整合学习与规划
《强化学习》第九讲 探索与利用
以及包括也叶博士独家创作的强化学习实践系列!
强化学习实践六 给Agent添加记忆功能
强化学习实践七 DQN的实现
今天实践六 给Agent添加记忆功能
在《强化学习》第一部分的实践中,我们主要剖析了gym环境的建模思想,随后设计了一个针对一维离散状态空间的格子世界环境类,在此基础上实现了SARSA和SARSA(λ)算法。《强化学习》第二部分内容聚焦于解决大规模问题,这类问题下的环境的观测空间通常是多维的而且观测的通常是连续变量,或者行为不再是离散的简单行为,而是由可在一定区间内连续取值的变量构成,在解决这类大规模问题时必须要对价值函数(或策略函数)进行一定程度的近似表示。在对这些函数进行近似表示的时候,可以使用多种机器学习算法,其中最常用的是线性回归或(深度)神经网络。从本实践六开始,我将尝试实现一些用于解决大规模问题的强化学习算法。之所以说尝试主要是因为这类算法的调试和训练需要花费大量的精力,限于水平也可能得不到令人满意的结果,所以只能量力而为,有兴趣一起做的朋友可以合力编写代码。
在这部分的实践中,我将主要利用gym里提供的一些经典环境,比如CartPole、MountainCar等。同时,我也编写了公开课提到的一个PuckWorld的环境类,这个环境也很有意思,我也会用它来测试编写的代码。本次实践,我将把之前的两个Agent类抽象成一个基类(Agent),同时针对状态转换、Episode等进行建模以实现Agent可以具备一定的记忆功能以及从可以从记忆里批量学习,最后我将简单介绍一下PuckWorld环境。
抽象的Agent基类
为了体现继承和多态性,增加代码的复用性和可读性,我们先把Agent类做一个抽象,基类Agent除具备之前提到的一些执行策略、执行行为、学习等基本功能外,同时还具有记住一定数量的已经经历过的状态转换对象的功能,最后还应能从记忆中随机获取一定数量的状态转换对象以供批量学习的功能,为此,Agent类可以如下设计:
class Agent(object):
'''Base Class of Agent '''
def __init__(self, env: Env = None,
trans_capacity = 0):
# 保存一些Agent可以观测到的环境信息以及已经学到的经验
self.env = env
self.obs_space = env.observation_space if env is not None else None
self.action_space = env.action_space if env is not None else None
self.experience = Experience(capacity = trans_capacity)
# 有一个变量记录agent当前的state相对来说还是比较方便的。要注意对该变量的维护、更新
self.state = None # current observation of an agent
def performPolicy(self,policy_fun, s):
if policy_fun is None:
return self.action_space.sample()
return policy_fun(s)
def act(self, a0):
s0 = self.state
s1, r1, is_done, info = self.env.step(a0)
# TODO add extra code here
trans = Transition(s0, a0, r1, is_done, s1)
total_reward = self.experience.push(trans)
self.state = s1
return s1, r1, is_done, info, total_reward
def learning(self):
'''need to be implemented by all subclasses '''
raise NotImplementedError
def sample(self, batch_size = 64):
'''随机取样 '''
return self.experience.sample(batch_size)
@property
def total_trans(self):
'''得到Experience里记录的总的状态转换数量 '''
return self.experience.total_trans在上面的代码中,Agent类维护了从env对象得来的状态和行为空间对象,同时维护了一个state对象用于记录个体当前的状态(观测),此外多了一个experience对象。该对象表示的即是个体的记忆内容,它将记录个体在一定期限内所经历过的状态和行为等相关信息。让个体记住经历过的事件主要目的是使得个体可以从中随机获取一定数量的相互之间基本没有关联的状态转换信息,这些无关的状态转换信息将使得个体可以学到一个更好的价值函数的近似表示。在我的设计中,经历(Experience)将由一系列有序的Episode组成,每一个场景片段(Episode)由一系列有序状态转换(Transition)组成,而每一个Transition则用几个变量来描述,这几个变量记录了个体的状态转化过程以及相关的一些信息。Transition、Episode、Experience这三个概念是依次被包含的关系。接下来我将依次具体介绍这几个概念(类)的建模。
个体记忆相关概念的建模
状态转换(Transition)类
状态转换(Transition)记录了:个体的当前状态s0、个体在当前状态下执行的行为a0、个体在状态s0时执行a0后环境给以的即时奖励值reward以及新状态s1,此外用一个Bool变量记录了状态s1是不是一个终止状态,以此表明该包含该状态转换的Episode是不是一个完整的Episode。关于Transition类,我编写的代码如下:
class Transition(object):
def __init__(self, s0, a0, reward:float, is_done:bool, s1):
self.data = [s0,a0,reward,is_done,s1]
def __iter__(self):
return iter(self.data)
def __str__(self):
return "s:{0:<3} a:{1:<3} r:{2:<4} is_end:{3:<5} s1:{4:<3}".\ format(self.data[0],
self.data[1],
self.data[2],
self.data[3],
self.data[4])
@property
def s0(self): return self.data[0]
@property
def a0(self): return self.data[1]
@property
def reward(self): return self.data[2]
@property
def is_done(self): return self.data[3]
@property
def s1(self): return self.data[4]场景片段(Episode)类
Episode类的主要功能是记录一系列的Episode,这些Episode就是由一系列的有序Transition对象构成,同时为了便于分析,我们额外添加了一些功能,比如在记录一个Transition对象的同时累加其即时奖励值以获得个体在经历一个Episode时获得的总奖励;又比如我们可以从Episode中随机获取一定数量、无序的Transition,以提高离线学习的准确性;此外由于一个Episode是不是一个完整的Episode在强化学习里是一个非常重要的信息,为此特别设计了一个方法来执行这一功能。至此,实现上述功能的Episode代码可以是如下的样子:
class Episode(object):
def __init__(self, e_id:int = 0) -> None:
self.total_reward = 0 # 总的获得的奖励
self.trans_list = [] # 状态转移列表
self.name = str(e_id) # 可以给Episode起个名字:"成功闯关,黯然失败?"
def push(self, trans:Transition) -> float:
self.trans_list.append(trans)
self.total_reward += trans.reward
return self.total_reward
@property
def len(self):
return len(self.trans_list)
def __str__(self):
return "episode {0:<4} {1:>4} steps,total reward:{2:<8.2f}".\ format(self.name, self.len,self.total_reward)
def print_detail(self):
print("detail of ({0}):".format(self))
for i,trans in enumerate(self.trans_list):
print("step{0:<4} ".format(i),end=" ")
print(trans)
def pop(self) -> Transition:
'''normally this method shouldn't be invoked. '''
if self.len > 1:
trans = self.trans_list.pop()
self.total_reward -= trans.reward
return trans
else:
return None
def is_complete(self) -> bool:
'''check if an episode is an complete episode '''
if self.len == 0:
return False
return self.trans_list[self.len-1].is_done
def sample(self,batch_size = 1):
'''随即产生一个trans '''
return random.sample(self.trans_list, k = batch_size)
def __len__(self) -> int:
return self.len从上面的代码可以看出:我们用一个list来存储状态转换对象系列;我们可以为每一个Episode取一个名字,默认使用参数传递的数字来命名;我们也设计了一些方法来方便输出Episode的简要和详细信息;当然一个Episode的长度也是一个重要的属性。有了Episode类,Experience类写起来就又更加方便了。
经历(Experience)类
一个个Episode组成了个体的经历(Experience)。我看到过的一些模型使用一个叫“Memory”的概念来记录个体既往的经历,其建模思想是Memory仅无序存储一系列的Transition,不使用Episode这一概念,不反映Transition对象之间的关联,这也是可以完成基于记忆的离线学习的强化学习算法的,甚至其随机采样过程更简单。不过我还是额外设计了Episode以及在此基础上的Experience。读者可以根据喜好决定自己的建模。
一般来说经历或者记忆的容量是有限的,为此我们需要给其设定一个能够记录的Transition对象的最大上限,称为容量(capacity)。一旦个体经历的Transition数量超过该容量,则将抹去最早期的Transition,为将来的Transition腾出空间。可以想象,一个Experience类应该至少具备如下功能:移除早期的Transition;记住一个Transition;从Experience中随机采样一定数量的Transition。一个可能的Experience类的实现如下:
class Experience(object):
'''this class is used to record the whole experience of an agent organized by an episode list. agent can randomly sample transitions or episodes from its experience. '''
def __init__(self, capacity:int = 20000):
self.capacity = capacity # 容量:指的是trans总数量
self.episodes = [] # episode列表
self.next_id = 0 # 下一个episode的Id
self.total_trans = 0 # 总的状态转换数量
def __str__(self):
return "exp info:{0:5} episodes, memory usage {1}/{2}".\ format(self.len, self.total_trans, self.capacity)
def __len__(self):
return self.len
@property
def len(self):
return len(self.episodes)
def _remove(self, index = 0):
'''扔掉一个Episode,默认第一个。 remove an episode, defautly the first one. args: the index of the episode to remove return: if exists return the episode else return None '''
if index > self.len - 1:
raise(Exception("invalid index"))
if self.len > 0:
episode = self.episodes[index]
self.episodes.remove(episode)
self.total_trans -= episode.len
return episode
else:
return None
def _remove_first(self):
self._remove(index = 0)
def push(self, trans):
'''压入一个状态转换 '''
if self.capacity <= 0:
return
while self.total_trans >= self.capacity: # 可能会有空episode吗?
episode = self._remove_first()
cur_episode = None
if self.len == 0 or self.episodes[self.len-1].is_complete():
cur_episode = Episode(self.next_id)
self.next_id += 1
self.episodes.append(cur_episode)
else:
cur_episode = self.episodes[self.len-1]
self.total_trans += 1
return cur_episode.push(trans) #return total reward of an episode
def sample(self, batch_size=1): # sample transition
'''randomly sample some transitions from agent's experience.abs 随机获取一定数量的状态转化对象Transition args: number of transitions need to be sampled return: list of Transition. '''
sample_trans = []
for _ in range(batch_size):
index = int(random.random() * self.len)
sample_trans += self.episodes[index].sample()
return sample_trans
def sample_episode(self, episode_num = 1): # sample episode
'''随机获取一定数量完整的Episode '''
return random.sample(self.episodes, k = episode_num)
@property
def last(self):
if self.len > 0:
return self.episodes[self.len-1]
return None从上面的代码我们可以看出:Experience内维护了一个Episode列表、容量信息、当前Transition数量、以及下一个Episode的序号;Experience具有移除一个Episode的功能,暂不具备移除单个Transition的功能;记录一个新Transition;随机采样一定数量的Transition或者随机采样一定数量的Episode。此外,我还额外设计了一个方法来获取经历中最近的Episode;当然也可以想终端输出其简要信息。
至此,个体基于离线学习的条件就具备了。返回我们之前设计的基类Agent,可以看出,该基类具有一个Experience对象,其act方法内完成了对新Transition的记录。同时修改后的act代码还直接返回了个体在一个Episode内当前获得的总奖励值;此外个体也具备了随机采样的功能。
注:上述代码经过了初步的测试,但不排除仍有错误、异常发生的可能,欢迎读者指出错误或提出完善方法。
在实践七中,我们将使用这些代码来实现《强化学习》第六讲提到的用神经网络来近似表示价值函数的Q学习算法:DQN。
在本篇结束之前,我简要介绍下PuckWorld环境类,今后将会用该环境来测试我们实现的代码。
PuckWorld环境
PuckWorld环境出现在《强化学习》第七讲中,它描述的是一个连续的二维空间中的个体追逐一个目标物体这样一个场景。如下图所示:在矩形空间里,个体试图尽可能得靠近五角形的目标以获取更多的奖励;与此同时,目标物体(五角形)每隔一定的时间将重新出现的区域里随机的位置,个体需要对此做出反应,调整行为接近新位置下的目标物体。
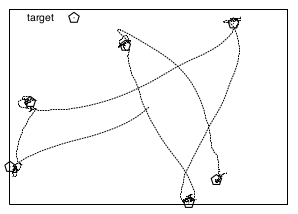
该环境相比之前的格子世界环境最大的不同之处在于矩形区域是一个用二维连续变量描述的空间。此时要描述个体或目标物体的位置,必须要使用连续的值。在经典的PuckWorld环境中,个体的观测空间由6个变量组成,分别是:2个变量描述个体的位置(水平和垂直方向上的坐标值)、2个变量描述目标物体的位置(水平和垂直方向上的坐标值)、以及个体运动的速度在水平和垂直方向上的分量。个体的行为空间仍然是一维的离散空间,有5个可能的取值,分别为:增加左、右、上、下四个方向的单位速率值以及维持当前速度。环境的动力学体现在个体下一个时刻的位置由当前位置及其速度决定;目标物体以固定的周期随机刷新其位置;个体越接近目标物体获得的即时奖励越高;如果个体距离目标物体的距离在某一设定值以内,则当前Episode结束。该环境的动力学可以用下面的代码描述:
# 该代码不是PuckWorld类完整的代码def _step(self, action):
assert self.action_space.contains(action), \ "%r (%s) invalid" % (action, type(action))
self.action = action # action for rendering
ppx, ppy, pvx, pvy, tx, ty = self.state # 获取agent位置,速度,目标位置
ppx, ppy = ppx + pvx, ppy + pvy # update agent position
pvx, pvy = pvx*0.95, pvy*0.95 # natural velocity loss
if action == 0: pvx -= self.accel # left
if action == 1: pvx += self.accel # right
if action == 2: pvy += self.accel # up
if action == 3: pvy -= self.accel # down
if action == 4: pass # no move
if ppx < self.rad: # encounter left bound
pvx *= -0.5
ppx = self.rad
if ppx > 1 - self.rad: # right bound
pvx *= -0.5
ppx = 1 - self.rad
if ppy < self.rad: # bottom bound
pvy *= -0.5
ppy = self.rad
if ppy > 1 - self.rad: # right bound
pvy *= -0.5
ppy = 1 - self.rad
self.t += 1
if self.t % self.update_time == 0: # update target position
tx = self._random_pos() # randomly
ty = self._random_pos()
dx, dy = ppx - tx, ppy - ty # calculate distance from
dis = self._compute_dis(dx, dy) # agent to target
self.reward = self.goal_dis - dis # give an reward
done = bool(dis <= self.goal_dis)
self.state = (ppx, ppy, pvx, pvy, tx, ty)
return np.array(self.state), self.reward, done, {}下面的视频动态地展示了该环境以及一个经过DQN算法训练过的个体的表现。视频中,我使用小绿色圆球表示目标物体,大球表示个体,当个体距离目标物体较近时,个体显示为偏绿色,反之则偏红色。个体内部使用箭头表示当前行为。由于个体存在一定程度的探索(Exploration)以及学习时间并不长,它并不是直接朝着目标移动。
该环境类的编写借鉴了Karpathy编写的PuckWorld代码,在此表示感谢。
注:本篇涉及的代码均可以在我的github上找到,分别在core.py和puckworld.py两个文件内,由于重新组织了代码,将之前的一些示例代码全部编入examples文件夹中,可能会导致之前几篇的部分链接暂时失效。
欢迎志同道合的朋友们一起完善相关强化学习算法。
本篇内容就写到这里,下一次实践将聚焦DQN算法的实现。敬请期待!
作者简介:
叶强,眼科专家,上海交通大学医学博士, 工学学士,现从事医学+AI相关的研究工作。
特注:
请登录www.zhuanzhi.ai或者点击阅读原文,
顶端搜索“强化学习” 主题,直接获取查看获得全网收录资源进行查看, 涵盖论文等资源下载链接,并获取更多与强化学习的知识资料!如下图所示。
此外,请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),后台回复“强化学习” 就可以获取深度强化学习知识资料全集(论文/代码/教程/视频/文章等)的pdf文档!
欢迎转发到你的微信群和朋友圈,分享专业AI知识!
请感兴趣的同学,扫一扫下面群二维码,加入到专知-深度强化学习交流群!

请扫描小助手,加入专知人工智能群,交流分享~

获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!
展开全文



