【论文推荐】最新十篇机器翻译相关论文—记忆增强、词嵌入、形态学信息、非自回归神经序列、用户反馈、语法纠错、单语语料、自注意力机制
【导读】既昨天推出十篇机器翻译(Machine Translation)相关文章,专知内容组今天又推出最近十篇篇机器翻译相关文章,为大家进行介绍,欢迎查看!
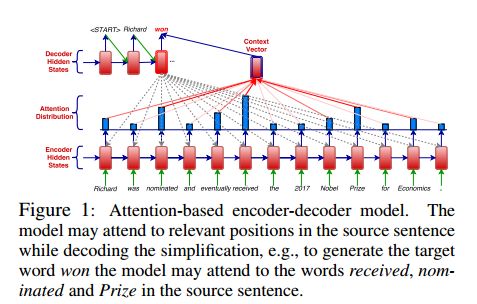
11. Sentence Simplification with Memory-Augmented Neural Networks(用记忆增强神经网络简化句子)
作者:Tu Vu,Baotian Hu,Tsendsuren Munkhdalai,Hong Yu
机构:University of Massachusetts Medical School
摘要:Sentence simplification aims to simplify the content and structure of complex sentences, and thus make them easier to interpret for human readers, and easier to process for downstream NLP applications. Recent advances in neural machine translation have paved the way for novel approaches to the task. In this paper, we adapt an architecture with augmented memory capacities called Neural Semantic Encoders (Munkhdalai and Yu, 2017) for sentence simplification. Our experiments demonstrate the effectiveness of our approach on different simplification datasets, both in terms of automatic evaluation measures and human judgments.
期刊:arXiv, 2018年4月20日
网址:
http://www.zhuanzhi.ai/document/00cd908c10f9d303be8b02bdb8a30151
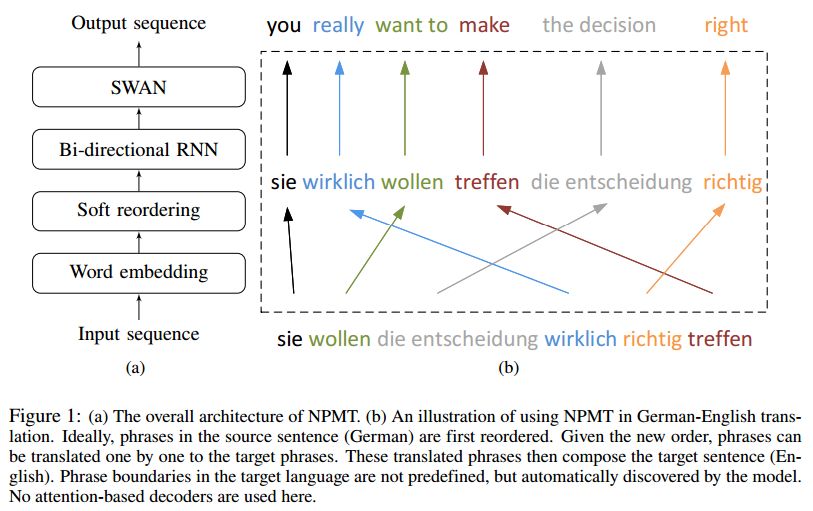
12. Towards Neural Phrase-based Machine Translation(基于神经短语的机器翻译)
作者:Po-Sen Huang,Chong Wang,Sitao Huang,Dengyong Zhou,Li Deng
机构:University of Illinois at Urbana-Champaign
摘要:In this paper, we present Neural Phrase-based Machine Translation (NPMT). Our method explicitly models the phrase structures in output sequences using Sleep-WAke Networks (SWAN), a recently proposed segmentation-based sequence modeling method. To mitigate the monotonic alignment requirement of SWAN, we introduce a new layer to perform (soft) local reordering of input sequences. Different from existing neural machine translation (NMT) approaches, NPMT does not use attention-based decoding mechanisms. Instead, it directly outputs phrases in a sequential order and can decode in linear time. Our experiments show that NPMT achieves superior performances on IWSLT 2014 German-English/English-German and IWSLT 2015 English-Vietnamese machine translation tasks compared with strong NMT baselines. We also observe that our method produces meaningful phrases in output languages.
期刊:arXiv, 2018年4月19日
网址:
http://www.zhuanzhi.ai/document/dc6dac245850a7f6250338219536a945
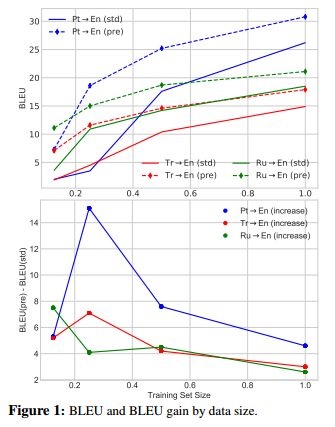
13. When and Why are Pre-trained Word Embeddings Useful for Neural Machine Translation?(什么时候和为什么预先训练的词嵌入对神经机器翻译有用)
作者:Ye Qi,Devendra Singh Sachan,Matthieu Felix,Sarguna Janani Padmanabhan,Graham Neubig
机构:Carnegie Mellon University
摘要:The performance of Neural Machine Translation (NMT) systems often suffers in low-resource scenarios where sufficiently large-scale parallel corpora cannot be obtained. Pre-trained word embeddings have proven to be invaluable for improving performance in natural language analysis tasks, which often suffer from paucity of data. However, their utility for NMT has not been extensively explored. In this work, we perform five sets of experiments that analyze when we can expect pre-trained word embeddings to help in NMT tasks. We show that such embeddings can be surprisingly effective in some cases -- providing gains of up to 20 BLEU points in the most favorable setting.
期刊:arXiv, 2018年4月18日
网址:
http://www.zhuanzhi.ai/document/3dc9d6241fbe93331d99570dbdae5d52
14. Improving Character-based Decoding Using Target-Side Morphological Information for Neural Machine Translation(利用Target-Side形态学信息对基于字符的神经机器翻译进行改进)
作者:Peyman Passban,Qun Liu,Andy Way
机构:Dublin City University
摘要:Recently, neural machine translation (NMT) has emerged as a powerful alternative to conventional statistical approaches. However, its performance drops considerably in the presence of morphologically rich languages (MRLs). Neural engines usually fail to tackle the large vocabulary and high out-of-vocabulary (OOV) word rate of MRLs. Therefore, it is not suitable to exploit existing word-based models to translate this set of languages. In this paper, we propose an extension to the state-of-the-art model of Chung et al. (2016), which works at the character level and boosts the decoder with target-side morphological information. In our architecture, an additional morphology table is plugged into the model. Each time the decoder samples from a target vocabulary, the table sends auxiliary signals from the most relevant affixes in order to enrich the decoder's current state and constrain it to provide better predictions. We evaluated our model to translate English into German, Russian, and Turkish as three MRLs and observed significant improvements.

期刊:arXiv, 2018年4月18日
网址:
http://www.zhuanzhi.ai/document/9a6f60c6ea5ff905ca14333ee4378876
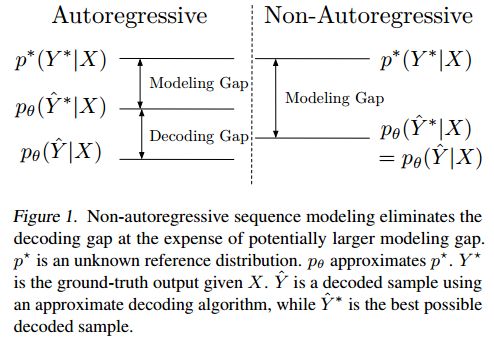
15. Deterministic Non-Autoregressive Neural Sequence Modeling by Iterative Refinement(确定性非自回归神经序列模型的迭代细化)
作者:Jason Lee,Elman Mansimov,Kyunghyun Cho
摘要:We propose a conditional non-autoregressive neural sequence model based on iterative refinement. The proposed model is designed based on the principles of latent variable models and denoising autoencoders, and is generally applicable to any sequence generation task. We extensively evaluate the proposed model on machine translation (En-De and En-Ro) and image caption generation, and observe that it significantly speeds up decoding while maintaining the generation quality comparable to the autoregressive counterpart.
期刊:arXiv, 2018年4月18日
网址:
http://www.zhuanzhi.ai/document/714005ea52db2a8a6b4f5cb1b8f27b1d
16. Can Neural Machine Translation be Improved with User Feedback?(神经机器翻译可以通过用户的反馈来改进吗?)
作者:Julia Kreutzer,Shahram Khadivi,Evgeny Matusov,Stefan Riezler
机构:Heidelberg University
摘要:We present the first real-world application of methods for improving neural machine translation (NMT) with human reinforcement, based on explicit and implicit user feedback collected on the eBay e-commerce platform. Previous work has been confined to simulation experiments, whereas in this paper we work with real logged feedback for offline bandit learning of NMT parameters. We conduct a thorough analysis of the available explicit user judgments---five-star ratings of translation quality---and show that they are not reliable enough to yield significant improvements in bandit learning. In contrast, we successfully utilize implicit task-based feedback collected in a cross-lingual search task to improve task-specific and machine translation quality metrics.
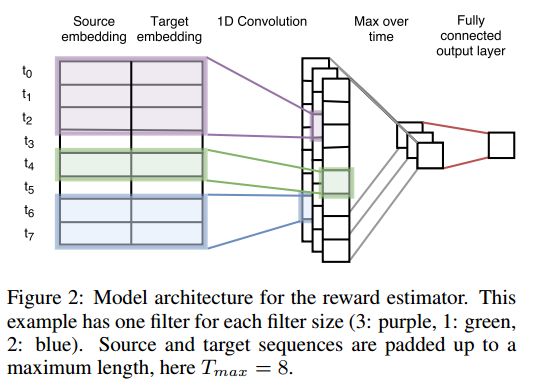
期刊:arXiv, 2018年4月17日
网址:
http://www.zhuanzhi.ai/document/995e166c55b280444d5f68e004f4b923
17. Near Human-Level Performance in Grammatical Error Correction with Hybrid Machine Translation(混合机器翻译在语法纠错中接近人类水平的表现)
作者:Roman Grundkiewicz,Marcin Junczys-Dowmunt
机构:University of Edinburgh
摘要:We combine two of the most popular approaches to automated Grammatical Error Correction (GEC): GEC based on Statistical Machine Translation (SMT) and GEC based on Neural Machine Translation (NMT). The hybrid system achieves new state-of-the-art results on the CoNLL-2014 and JFLEG benchmarks. This GEC system preserves the accuracy of SMT output and, at the same time, generates more fluent sentences as it typical for NMT. Our analysis shows that the created systems are closer to reaching human-level performance than any other GEC system reported so far.
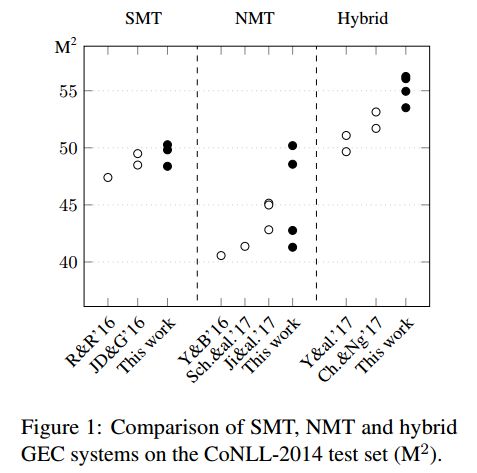
期刊:arXiv, 2018年4月17日
网址:
http://www.zhuanzhi.ai/document/8c920c38ce144f45646463eea3cf84ee
18. Approaching Neural Grammatical Error Correction as a Low-Resource Machine Translation Task(将神经语法错误校正作为一项低资源的机器翻译任务)
作者:Marcin Junczys-Dowmunt,Roman Grundkiewicz,Shubha Guha,Kenneth Heafield
机构:University of Edinburgh
摘要:Previously, neural methods in grammatical error correction (GEC) did not reach state-of-the-art results compared to phrase-based statistical machine translation (SMT) baselines. We demonstrate parallels between neural GEC and low-resource neural MT and successfully adapt several methods from low-resource MT to neural GEC. We further establish guidelines for trustable results in neural GEC and propose a set of model-independent methods for neural GEC that can be easily applied in most GEC settings. Proposed methods include adding source-side noise, domain-adaptation techniques, a GEC-specific training-objective, transfer learning with monolingual data, and ensembling of independently trained GEC models and language models. The combined effects of these methods result in better than state-of-the-art neural GEC models that outperform previously best neural GEC systems by more than 10% M$^2$ on the CoNLL-2014 benchmark and 5.9% on the JFLEG test set. Non-neural state-of-the-art systems are outperformed by more than 2% on the CoNLL-2014 benchmark and by 4% on JFLEG.
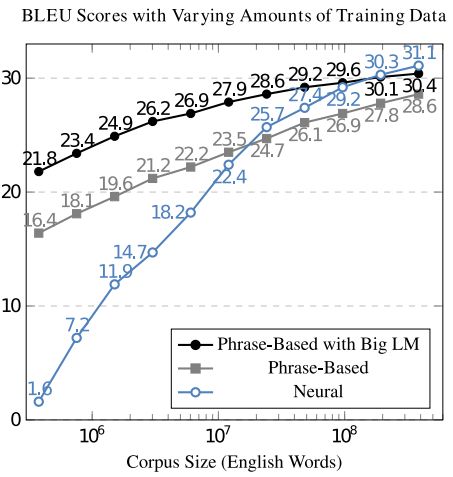
期刊:arXiv, 2018年4月17日
网址:
http://www.zhuanzhi.ai/document/8f2a250304fb2cf38481d4009f135b5d
19. Unsupervised Machine Translation Using Monolingual Corpora Only(单语语料的无监督机器翻译)
作者:Guillaume Lample,Alexis Conneau,Ludovic Denoyer,Marc'Aurelio Ranzato
机构:Sorbonne Universites
摘要:Machine translation has recently achieved impressive performance thanks to recent advances in deep learning and the availability of large-scale parallel corpora. There have been numerous attempts to extend these successes to low-resource language pairs, yet requiring tens of thousands of parallel sentences. In this work, we take this research direction to the extreme and investigate whether it is possible to learn to translate even without any parallel data. We propose a model that takes sentences from monolingual corpora in two different languages and maps them into the same latent space. By learning to reconstruct in both languages from this shared feature space, the model effectively learns to translate without using any labeled data. We demonstrate our model on two widely used datasets and two language pairs, reporting BLEU scores of 32.8 and 15.1 on the Multi30k and WMT English-French datasets, without using even a single parallel sentence at training time.
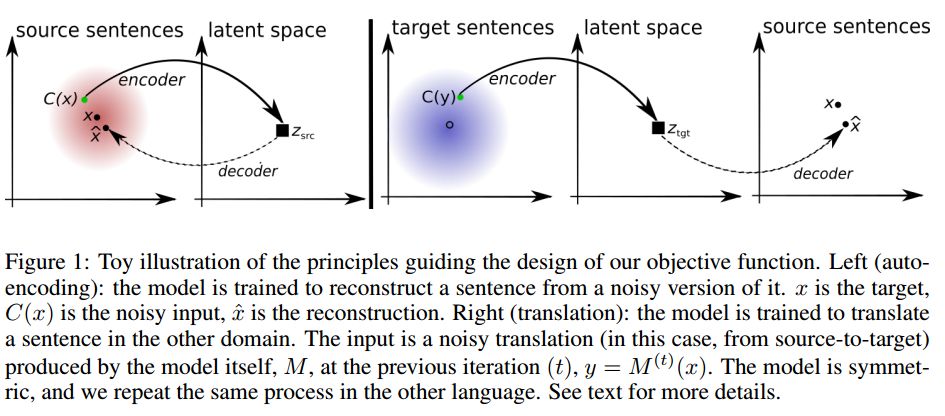
期刊:arXiv, 2018年4月13日
网址:
http://www.zhuanzhi.ai/document/2c2c7a550c265fe23c3835fb6f5131d0
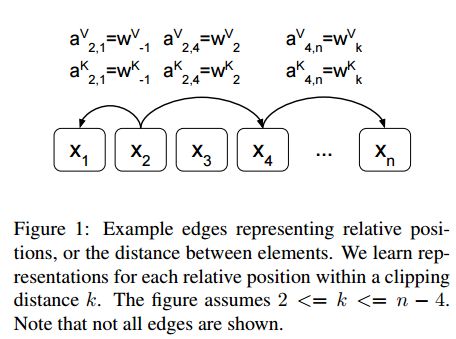
20. Self-Attention with Relative Position Representations(以相对位置表示的自注意力机制)
作者:Peter Shaw,Jakob Uszkoreit,Ashish Vaswani
机构:Google Brain
摘要:Relying entirely on an attention mechanism, the Transformer introduced by Vaswani et al. (2017) achieves state-of-the-art results for machine translation. In contrast to recurrent and convolutional neural networks, it does not explicitly model relative or absolute position information in its structure. Instead, it requires adding representations of absolute positions to its inputs. In this work we present an alternative approach, extending the self-attention mechanism to efficiently consider representations of the relative positions, or distances between sequence elements. On the WMT 2014 English-to-German and English-to-French translation tasks, this approach yields improvements of 1.3 BLEU and 0.3 BLEU over absolute position representations, respectively. Notably, we observe that combining relative and absolute position representations yields no further improvement in translation quality. We describe an efficient implementation of our method and cast it as an instance of relation-aware self-attention mechanisms that can generalize to arbitrary graph-labeled inputs.
期刊:arXiv, 2018年4月13日
网址:
http://www.zhuanzhi.ai/document/f63c5abb3335d143313ec118fc33a49c
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

点击上面图片加入会员
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

点击“阅读原文”,使用专知
展开全文



