走进深度生成模型:变分自动编码器(VAE)和生成对抗网络(GAN)
【导读】近日,深度学习爱好者Prakash Pandey发布一篇博文介绍深度生成模型。我们知道,有监督学习在很多方面都达到了很好的效果,但是,由于有监督学习由于数据集太少等缺点,研究者逐渐偏向于探索无监督学习方法。本文主要介绍深度生成模型,利用无监督学习来学习数据的真实分布。本文的内容主要包括:变分自编码器(VAE)和生成对抗网络(GAN),并探索其背后的工作原理。如今,无监督学习成为未来机器学习的研究方向,本文就跟大家一起聊一聊这其中热门的技术!

Deep Generative Models
深度生成模型
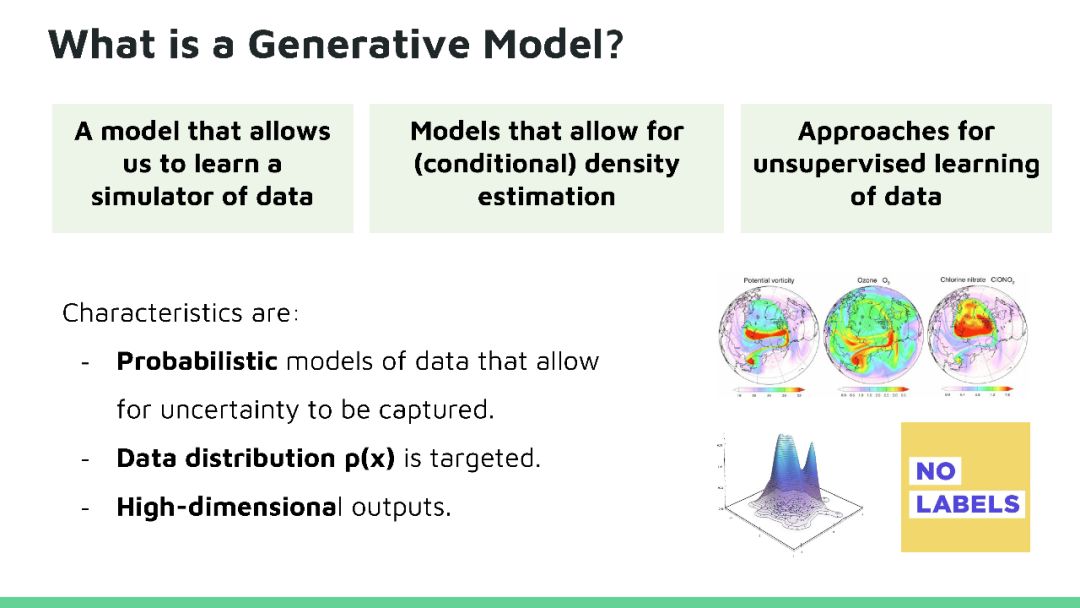
生成模型是使用无监督学习学习不同数据分布的有效方式,在过去短短的几年内已经取得了巨大的成功。 所有类型的生成模型都旨在学习训练集的真实数据分布,从而可以进一步产生具有一些变化的新数据。 但是隐式或者显式地学习我们数据的确切分布并不总是可行的,所以我们只能试图获得与真实数据分布尽可能相似的分布模型。 对此,我们可以利用神经网络学习一个能够将模型分布逼近真实分布的函数。
两种最常用和最有效的方法是变分自动编码器(VAE)和生成对抗网络(GAN)。 VAE旨在最大化数据对数似然下界,GAN旨在实现生成器和判别器之间的对抗平衡。 在这篇博文中,我将解释VAE和GAN的工作以及背后的解释。
▌变分自动编码器
我假设读者已经熟悉普通自动编码器的原理。我们知道,我们可以使用自动编码器将输入图像编码为更小维度的表示,从而可以存储有关输入数据分布的潜在信息。但在普通自动编码器中,编码向量只能使用解码器映射到相应的输入。它当然不能用于生成具有某些变化的同类图像。
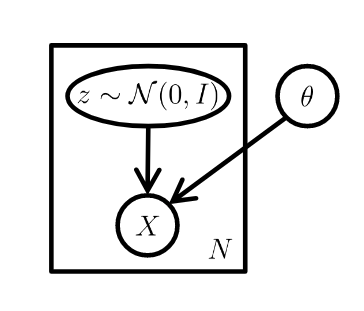
为了实现这一点,模型需要学习出训练数据的概率分布。 VAE是以非监督的方式使用神经网络学习复杂数据分布的最流行的方法之一,例如使用神经网络。这是一个植根于贝叶斯推断的概率图模型,即该模型旨在学习训练数据的基本概率分布,以便它可以容易地从该学习分布中采样新的数据。这个想法是学习一个被称为潜变量的训练数据的低维潜在表示(我们假设已经产生了我们的实际训练数据的潜变量(这些变量不是直接观察到的,而是通过数学模型推断的)。这些潜在变量可以存储有关模型需要生成的输出类型的有用信息。潜变量z的概率分布用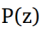
现在的主要目标是用一些参数来模拟数据,这些参数使得训练数据X的可能性最大化。总之,我们假设一个低维的潜在向量产生了我们的数据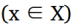
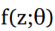
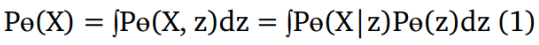
这里,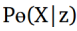
这个最大似然估计背后的直觉是,如果模型可以从这些潜变量产生训练样本,那么它也可以产生具有一些变化的相似样本。换句话说,如果我们从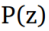
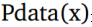
显然,手动指定想要在潜在矢量中编码的相关信息以生成输出图像是一项繁琐的任务。相反,我们依靠神经网络来计算z,只是假设这个潜在向量可以很好地近似为一个正态分布,以便在推理时很容易地进行采样。如果我们在n维空间中有z的正态分布,则总是可以使用足够复杂的函数生成任何类型的分布,并且可以使用此函数的逆来学习潜在变量本身。
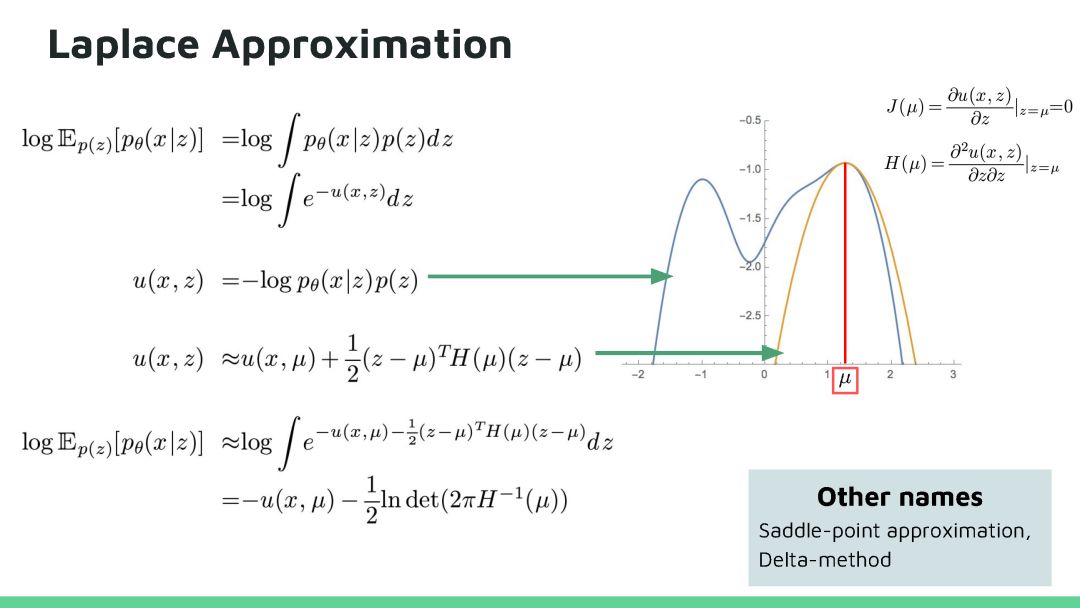
在等式1中,棘手的是积分需要在z的所有维上进行。虽然,可以使用蒙特卡罗方法来计算,这是不容易实现的。所以我们采用另一种方法来近似最大化等式1中的P(X)。VAE的想法是使用我们不知道的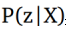
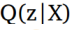
VAE的最终的目标函数是:
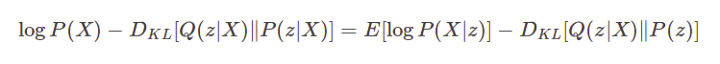
上面的等式有一个非常好的解释。术语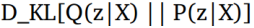
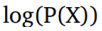
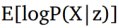
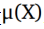
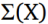
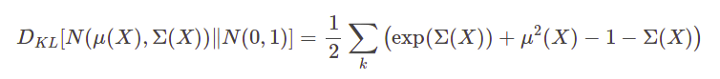
考虑到我们正在优化较低的变分边界,我们的优化函数是:
第二个问题的解决方案如上所示。
因此,我们的损失函数将包含两个项。 第一个是输入到输出的重建损失,第二个损失是KL散度项。 现在我们可以使用反向传播算法来训练网络。 但是存在一个问题,那就是第一项不仅取决于P的参数,而且还取决于Q的参数,但是这个依赖性不出现在上面的方程中。 那么如何从分布Q(z|X)或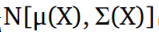
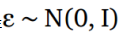
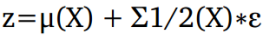
图2中显示的非常漂亮。 应该注意的是,前馈步骤对于这两个网络(左侧和右侧)是相同的,但是梯度只能通过正确的网络反向传播。
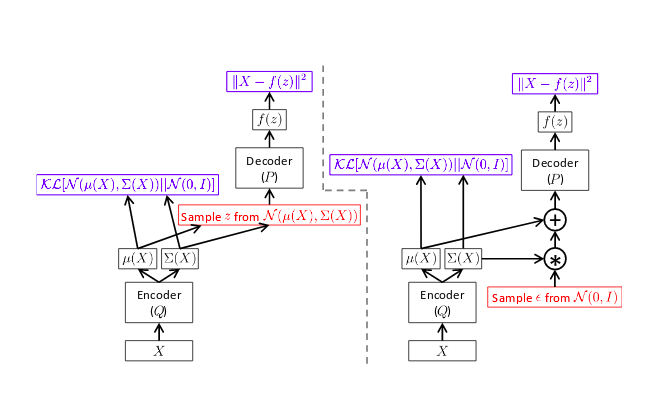
在推理时,我们可以简单地从N(0,1)中采样z并将其馈送到解码器网络以生成新的数据点。 由于我们正在优化较低的变分边界,所以生成的图像的质量与诸如生成对抗网络(Artrative Adversarial Networks)之类的最新技术相比有点差。
VAE最厉害的地方就是既能学习生成模型和又可以推理模型。 尽管VAE和GAN都是使用无监督学习来学习基础数据分布的非常令人兴奋的方法,但与VAE相比,GAN可以产生更好的结果。 在VAE中,我们优化了较低的变分边界,而在GAN中,没有这样的假设。 事实上,GAN不处理任何明确的概率密度估计。 VAE在产生清晰图像方面的失败意味着模型不能学习真正的后验分布。 VAE和GAN在训练方式上主要不同。 现在让我们进入生成对抗网络。
▌生成对抗网络
Yann LeCun曾说,对抗训练是自切片面包以来最酷的发明。如果看到生成对抗网络的普及以及它们产生的结果的质量,我想大多数人会同意他的看法。对抗训练彻底改变了我们教神经网络完成特定任务的方式。生成对抗网络不像任何明确的密度估计一样工作,如变分自动编码器。相反,它是基于博弈论的方法,目标是发现两个网络之间的纳什均衡,生成网络和判别网络。其思想是从像高斯这样的简单分布中抽样,然后学习使用通用函数逼近器(如神经网络)将这种噪声转换为数据分布。
这是通过这两个网络的对抗性培训来实现的。生成模型G学习捕获数据分布,判别模型D估计样本来自数据分布而不是模型分布的概率。基本上,生成器的任务是生成自然的图像,判别器的任务是决定图像是假的还是真实的。这可以被认为是两个网络的性能随着时间的推移而改善的迷你最大两个玩家游戏。在这个游戏中,生成器试图通过尽可能地产生真实图像来欺骗判别器,并且通过提高鉴别能力,生成器不会被判别器所迷惑。下图显示了GAN的基本架构。
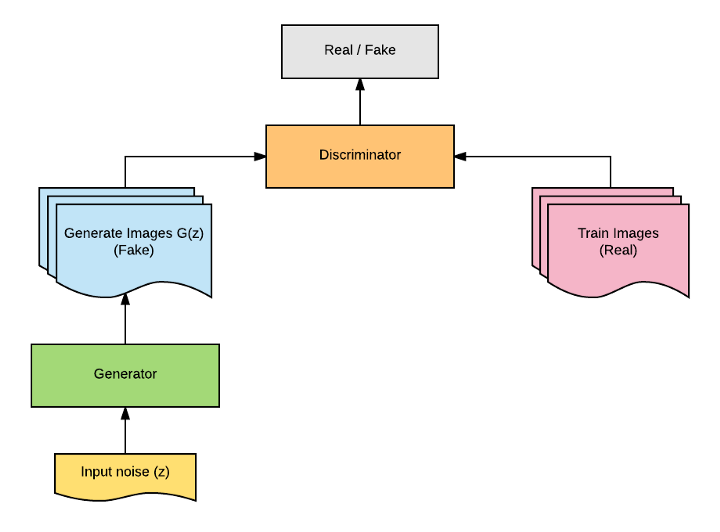
我们定义一个先验输入噪声变量P(z),然后生成器将其映射到使用具有参数өg的复微分函数的数据分布。 除此之外,我们还有另一个网络称为判别网络,它接受输入x并使用另一个带参数的微分函数。输出表示x来自真实数据分布$P\_{data}(x)$的概率的单个标量值。 GAN的目标函数被定义为
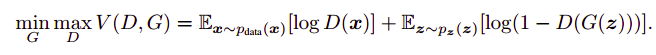
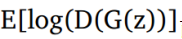
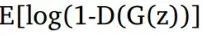
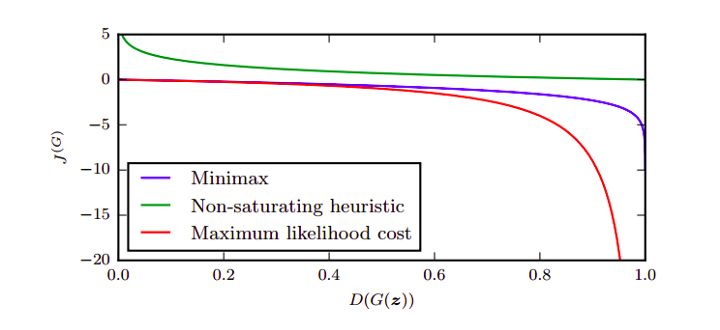
训练过程包括同时应用随机梯度下降的判别器和生成器。在训练时,我们在优化D的k个步骤之间交替,并且在小批次上优化G的一个步骤。当判别器不能区分ρg和ρdata,即D(x,өd)= 1/2或ρg=ρdata时,训练过程停止。
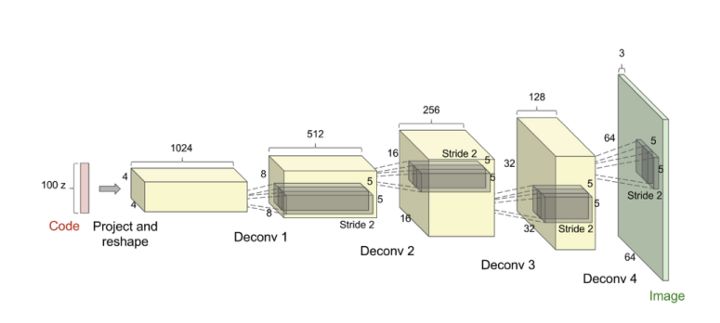
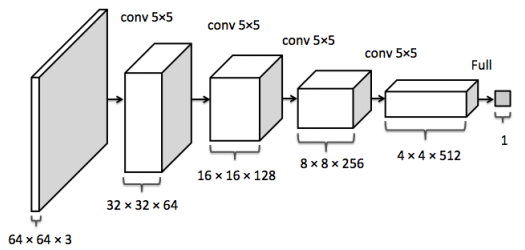
GAN应用卷积神经网络最早的模型之一是DCGAN ,它代表了深度卷积生成对抗网络(Deep Convolutional Generative Adversarial Networks)。该网络将从均匀分布画出的100个随机数作为输入,并输出所需形状的图像。网络由许多卷积,解卷积和完全连接的层组成。网络使用许多解卷积层将输入噪声映射到所需的输出图像。批量标准化用于稳定网络的训练。 ReLU激活在生成器中用于除了使用tanh层的输出层之外的所有层,并且在Discriminator中的所有层使用Leaky ReLU。这个网络是使用小批量随机梯度下降训练的,Adam优化器被用来加速训练和调整的超参数。这篇论文的结果非常有趣。作者指出,这些生成器具有有趣的矢量算术性质,我们可以用我们想要的方式来处理图像。
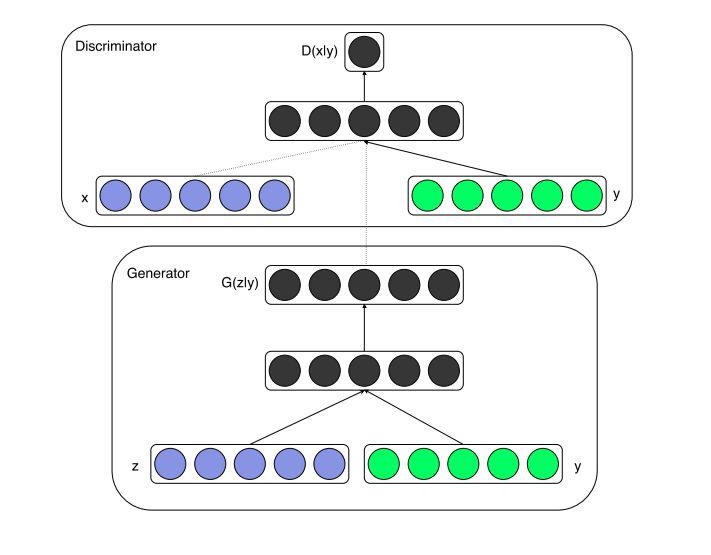
GAN最广泛使用的变体之一是有条件GAN(conditional GAN, cGAN),它是通过简单地将条件向量与噪声向量一起添加而构成的(见图7)。 在cGAN之前,我们从随机的噪声样本z中随机生成图像。 如果我们想要生成具有某些所需功能的图像,该怎么办? 有什么方法可以为模型提供额外的信息,无论如何,我们想要生成什么类型的图像? 答案是肯定的,有条件的GAN是这样做的。 通过对提供给生成器和判别器的附加信息调整模型,可以指导数据生成过程。 有条件的GAN用于各种任务,如文本到图像的生成,图像到图像的转换,图像的自动标记等。下图显示了这两个网络的统一结构。
GAN的一个很酷的事情就是,即使用小的训练数据也可以训练他们。事实上,GAN的结果是有希望的,但是训练过程并不轻松尤其是设置网络的超参数。而且,由于不容易聚合,所以GAN难以优化。当然有一些技巧和窍门来攻击GAN,但是它们可能并不总是有帮助的。你可以在这里找到一些这些技巧。此外,除了检查生成的图像是否是感性逼真之外,我们没有任何标准对结果进行定量评估。
▌结论
深度学习模型在监督学习中真正实现了人类水平的表现,但对于无监督学习来说,情况并非如此。尽管如此,深度学习的科学家正在努力提高无监督模型的性能。在这篇博文中,我们看到了两个最着名的无监督生成模型的学习框架是如何工作的。我们了解了变分自动编码器中的问题,以及为什么对抗网络能更好地生成逼真的图像。但是,GANs存在一些问题,比如训练的稳定性,这仍然是一个活跃的研究领域。然而,GAN功能非常强大,目前正被用于高质量图像和视频生成,文本到图像的翻译,图像增强,图像中物体三维模型的重建,音乐生成,癌症药物发现等。除此之外,许多深度学习的研究人员也正在努力将这两种模型统一起来,并使这两种模型得到最好的结果。看到深度学习的进步速度越来越快,我相信GAN会打开半监督学习和强化学习等人工智能问题的关闭的门。在接下来的几年中,生成模型对于图形设计,有吸引力的用户界面的设计等将会非常有帮助。使用生成对抗网络生成自然语言文本也是可能的。
原文链接:
https://towardsdatascience.com/deep-generative-models-25ab2821afd3
▌进阶
DeepMind 统计机器学习科学家Shakir Mohamed和Danilo Rezende在UAI2017大会上介绍了深度生成模型(Deep Generative Models)的最新进展。报告主要是回顾了深度生成模型(Deep Generative Models)的最新进展,两位讲者提及了深度生成模型的研究处于当前深度学习研究的前沿地带,会有越来越多的研究者关注。近几年的深度生成模型方法尝试将概率推理的普遍性与深度学习的可扩展性相结合来开发新的深度学习算法,在图像生成、语音合成和图像字幕等方面获得领先的结果。这个PPT和视频内容是学习深度生成模型非常好的资料。
摘要
Deep Generative Models
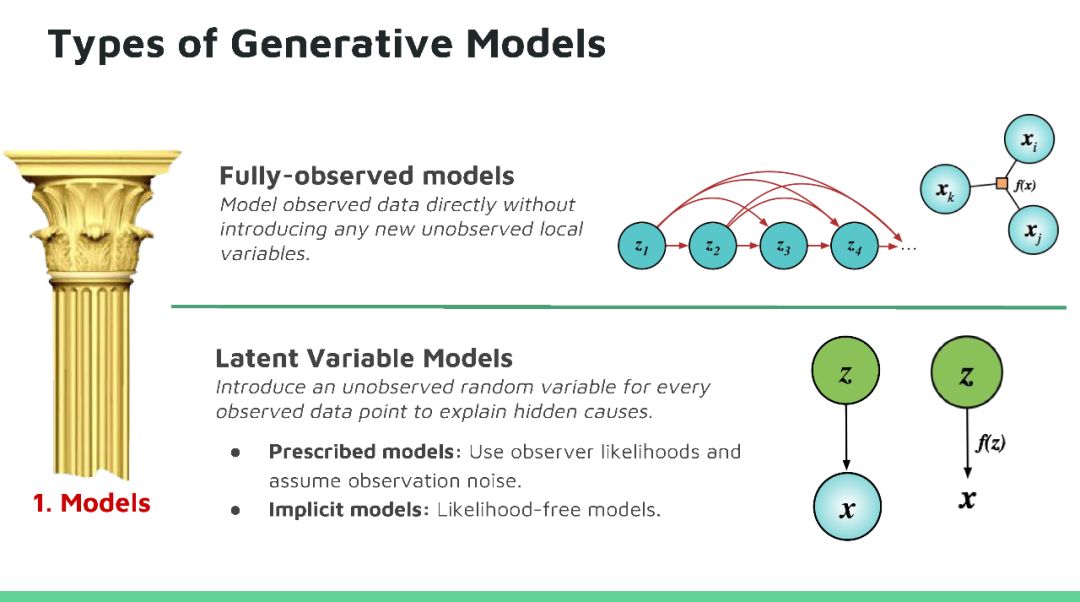
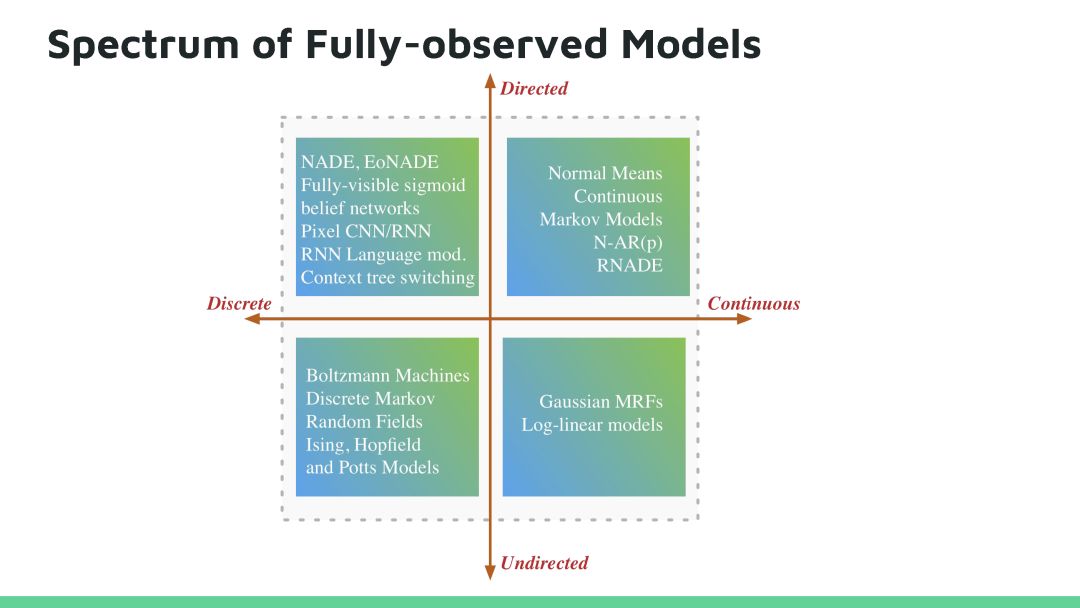
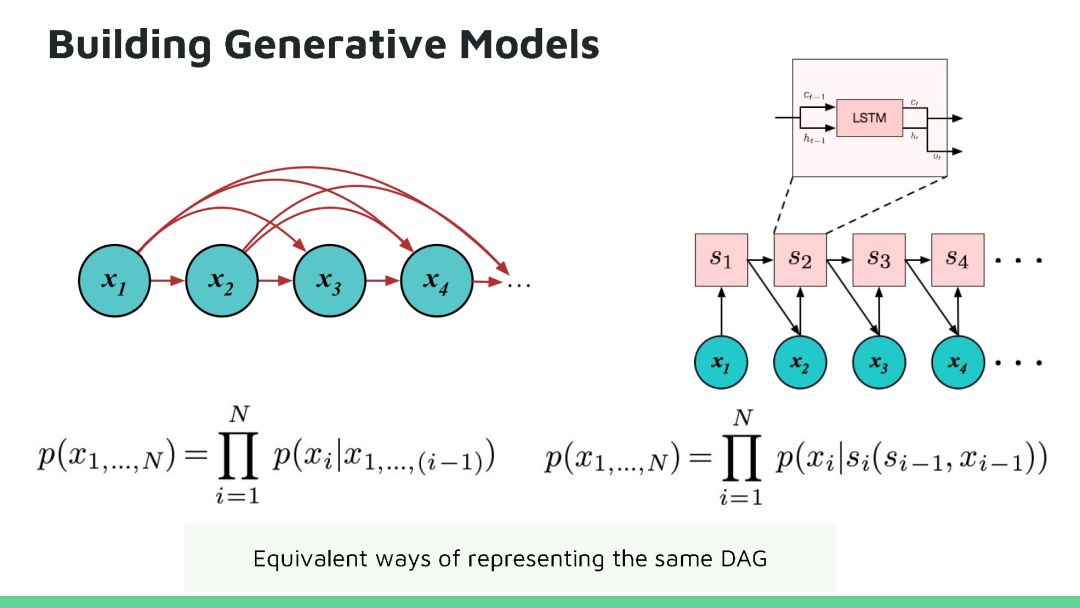
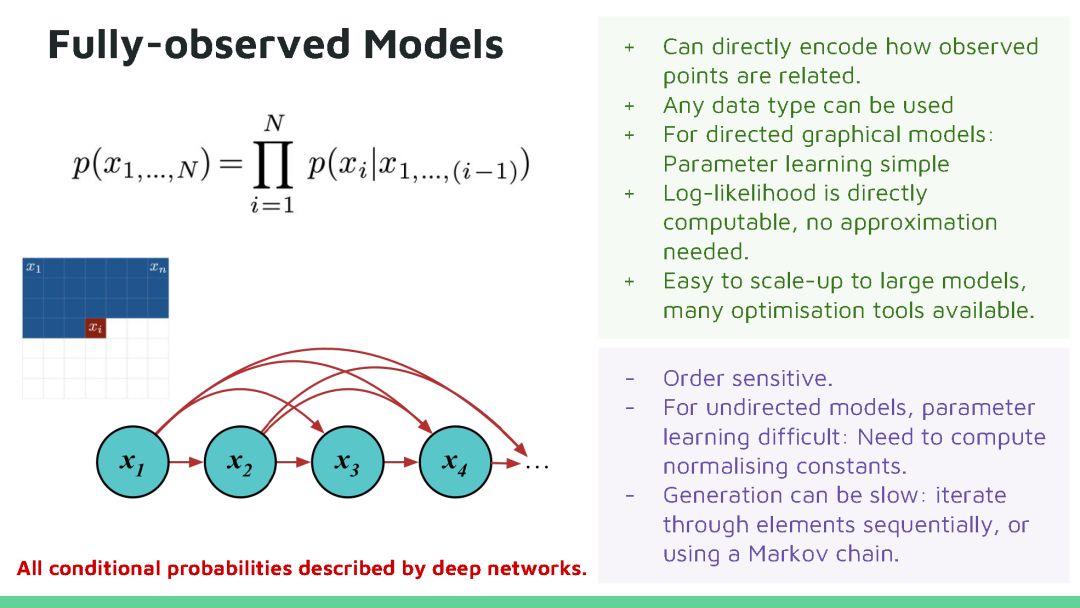
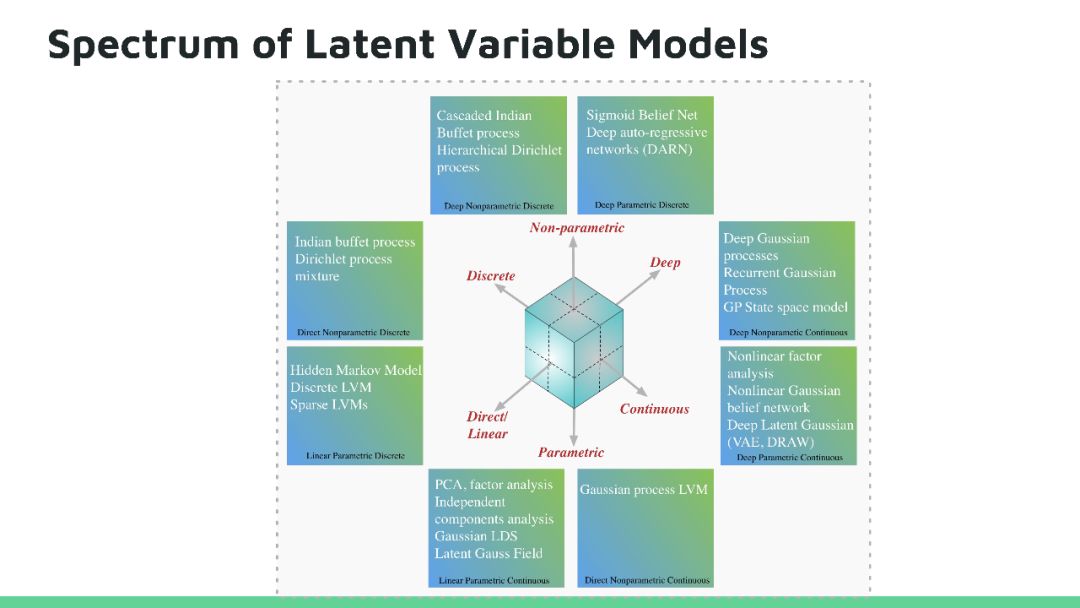
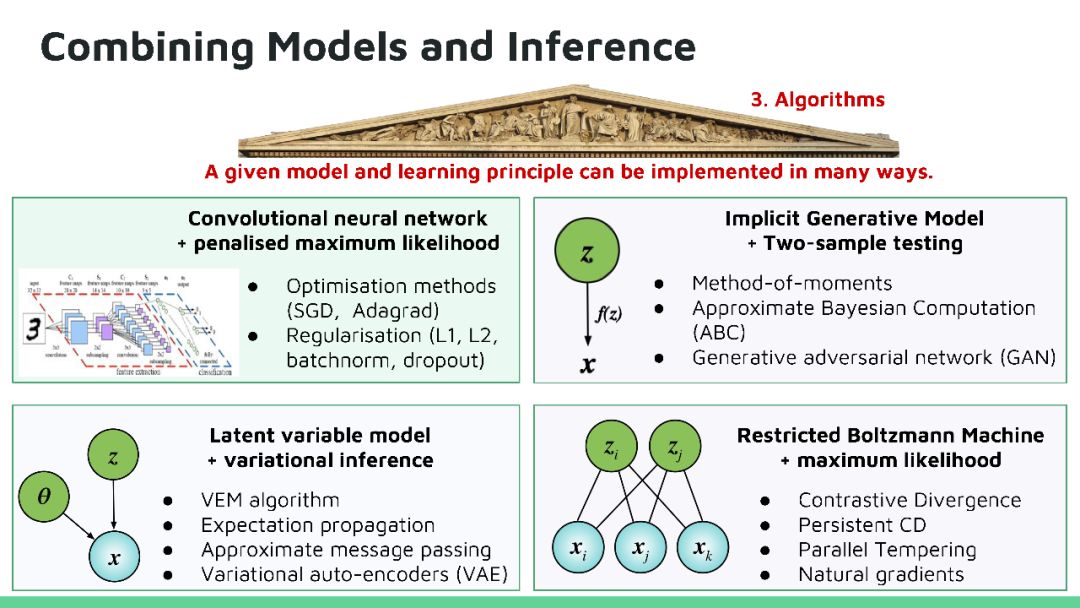
本教程将回顾深度生成模型的最新进展。生成模型在人工智能不确定(Uncertainty in Artificial Intelligence, UAI)研究方面有着悠久的历史,近期的方法尝试将概率推理的普遍性与深度学习的可扩展性相结合来开发新的深度学习算法,这些算法已经在很多问题上得到广泛应用,并在图像生成、语音合成和图像字幕等方面获得领先的结果。目前深度生成模型的研究处于深度学习研究的前沿地带,因为它高效数据学习和基于模型强化学习方面有着天然的优势。在本教程中,观众将对生成模型的最新进展有全面了解,其中包括三种最活跃模型:马尔可夫模型(Markov models,)、隐变量模型(latent variable models)和隐式模型(implicit models),以及如何将这些模型扩展到高维数据。本教程还揭示这个领域仍然存在的许多问题,所以在UAI领域还有有很多研究机会。
PPT详细内容
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“DGM” 就可以获取Deep Generative Models PPT下载~




















PPT 全部内容请点击链接:
http://mp.weixin.qq.com/s/diecjVsTkFhulTwET9N4WA
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知
展开全文



