零基础构建神经网络:使用PyTorch从零编写前馈神经网络代码
【导读】1月20日,机器学习研究人员Jeff Hu发布一篇深度学习教程,与其他的文章略有不同,作者并不介绍深度学习最前沿技术、也没有分析深度模型的优劣,而是从基础做起,教读者如何利用PyTorch从零开始编写一个前馈神经网络,毕竟,打好基础也是至关重要的!作者从加载数据,到网络代码编写、参数设置、训练模型、测试FNN模型,一步步通过代码实现,可以说,只要你一步步跟着做基本上就能实现一个FNN网络,这样更有助于从根本上理解FNN的结构。专知内容组编辑整理。

图像来自:https://media.scmagazine.com
A Simple Starter Guide to Build a Neural Network
建立神经网络的一个简单的入门指导
从今天开始,通过PyTorch,你将能够开发和构建一个前馈神经网络(FNN)。这里是FNN的Python jupyter代码库:https://github.com/yhuag/neural-network-lab
本篇指南作为一个基本的实践工作,旨在引导你从头开始构建神经网络。但是大部分数学概念都被忽略了。你可以自己自由学习那部分内容。
▌开始着手(准备工作)
1. 请确保你的机器上安装了Python和PyTorch:
Python 3.6(安装)
链接:https://www.python.org/downloads/
PyTorch (安装)
链接:http://pytorch.org/
2. 通过在控制台的命令行检查Python安装的正确性:
python -V
输出应该是Python 3.6.3或更高版本
3. 打开一个repository(文件夹)并创建你的第一个神经网络文件:
mkdir fnn-tuto
cd fnn-tuto
touch fnn.py
▌开始编写代码
所有下面的代码应该写在fnn.py文件中
导入PyTorch
import torch
import torch.nn as nn
import torchvision.datasets as dsets
import torchvision.transforms as transforms
from torch.autograd import Variable
这可以把PyTorch加载到代码中。这是我们编程的开端,良好的开端是成功的一半。
初始化超参数(Hyper-parameters)
超参数是预先设置的强大参数,不会随着神经网络的训练而更新,设置如下。
input_size = 784 # The image size = 28 x 28 = 784
hidden_size = 500 # The number of nodes at the hidden layer
num_classes = 10 # The number of output classes. In this case, from 0 to 9
num_epochs = 5 # The number of times entire dataset is trained
batch_size = 100 # The size of input data took for one iteration
learning_rate = 0.001 # The speed of convergence
下载MNIST数据集
MNIST是一个手写数字(即0到9)的大型数据库,旨在用于图像处理研究。
train_dataset = dsets.MNIST(root='./data',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = dsets.MNIST(root='./data',
train=False,
transform=transforms.ToTensor())
加载数据集
下载MNIST数据集后,我们将它们加载到我们的代码中。
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
注意:我们对train_dataset的加载过程进行了调整,以使学习过程独立于数据顺序,但是test_loader的顺序仍然是检查我们是否能够处理未指定顺序的输入。
构建前馈神经网络
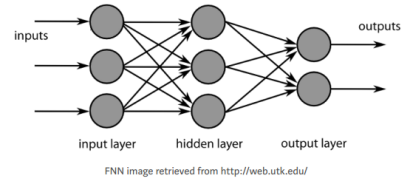
现在我们已经准备好了数据集。我们将开始构建神经网络。图结构可以解释如下:图片来源: http://web.utk.edu/
前馈神经网络模型结构
FNN包括两个全连接层(即fc1和fc2)和一个介于两者之间的非线性ReLU层。通常我们称这个结构为1-hidden layer FNN(含有一个隐藏层的前馈神经网络),但是并不把输出层(fc2)算在其中。
通过运行正向传递,输入图像(x)可以通过神经网络并生成一个输出(out),说明它属于10个类中的每个类的概率。例如,一张猫的图像可以有0.8的可能性是狗类和0.3的可能性是飞机类。
class Net(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(Net, self).__init__() # Inherited from the parent class nn.Module
self.fc1 = nn.Linear(input_size, hidden_size) # 1st Full-Connected Layer: 784 (input data) -> 500 (hidden node)
self.relu = nn.ReLU() # Non-Linear ReLU Layer: max(0,x)
self.fc2 = nn.Linear(hidden_size, num_classes) # 2nd Full-Connected Layer: 500 (hidden node) -> 10 (output class)
def forward(self, x): # Forward pass: stacking each layer together
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
实例化FNN
我们现在根据我们的结构创建一个真正的FNN。
net = Net(input_size, hidden_size, num_classes)
启用GPU
注意:你可以启用这一行来运行GPU上的代码。
# net.cuda() # You can comment out this line to disable GPU
选择损失函数和优化器
损失函数(准则)决定了如何将输出与类进行比较,这决定了神经网络的性能好坏。优化器选择了一种方法来更新权重,以收敛于这个神经网络中的最佳权重。
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=learning_rate)
训练FNN模型
此过程可能需要大约3到5分钟,具体取决于您的机器。详细解释请看如下代码中的注释(#)。
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader): # Load a batch of images with its (index, data, class)
images = Variable(images.view(-1, 28*28)) # Convert torch tensor to Variable: change image from a vector of size 784 to a matrix of 28 x 28
labels = Variable(labels)
optimizer.zero_grad() # Intialize the hidden weight to all zeros
outputs = net(images) # Forward pass: compute the output class given a image
loss = criterion(outputs, labels) # Compute the loss: difference between the output class and the pre-given label
loss.backward() # Backward pass: compute the weight
optimizer.step() # Optimizer: update the weights of hidden nodes
if (i+1) % 100 == 0: # Logging
print('Epoch [%d/%d], Step [%d/%d], Loss: %.4f'
%(epoch+1, num_epochs, i+1, len(train_dataset)//batch_size, loss.data[0]))
测试FNN模型
类似于训练神经网络,我们还需要加载批量的测试图像并收集输出。不同之处在于:
1. 没有损失和权重的计算
2. 没有权重的更新
3. 有正确的预测计算
correct = 0
total = 0
for images, labels in test_loader:
images = Variable(images.view(-1, 28*28))
outputs = net(images)
_, predicted = torch.max(outputs.data, 1) # Choose the best class from the output: The class with the best score
total += labels.size(0) # Increment the total count
correct += (predicted == labels).sum() # Increment the correct count
print('Accuracy of the network on the 10K test images: %d %%' % (100 * correct / total))
保存训练过的FNN模型以供将来使用
我们将训练好的模型保存为pickle,以便以后加载和使用。
torch.save(net.state_dict(), ‘fnn_model.pkl’)
恭喜。你已经完成了你的第一个前馈神经网络!
下一步是什么
保存并关闭文件。开始在控制台运行文件:
python fnn.py
你将会看到如下所示的训练过程:

感谢您的宝贵的阅读,并希望您喜欢这个教程。附上本教程所有代码链接:https://github.com/yhuag/neural-network-lab/blob/master/Feedforward%20Neural%20Network.ipynb
原文链接:
https://towardsdatascience.com/a-simple-starter-guide-to-build-a-neural-network-3c2cf07b8d7c
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



