【论文笔记】基于门控图网络实现图到序列学习
【导读】本篇论文出自ACL 2018,作者丹尼尔·贝克(Daniel Beck)等。他们在门控神经网络的基础上,实现了图到序列的学习表示,本篇文章从理论和实验两部分介绍本篇论文。
论文地址:
https://arxiv.org/pdf/1806.09835.pdf
作者在本篇论文中提出了一种图到序列(g2s)学习的模型,该模型利用encoder-decoder架构,采用一种基于门控图卷积网络(GCNN)的编码器,在不丢失信息的情况下整合完整的图结构,这样可以将“边“表示为标签方式。对于小尺寸标签词汇表,引入图转换,将”边“改为额外的节点,不但解决了参数爆炸问题,还确保了”边“具有特定图的隐向量。
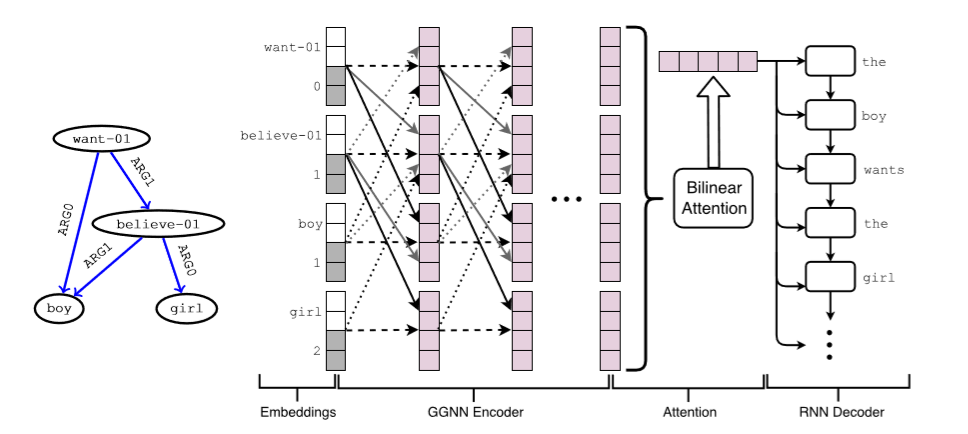
与S2S模型相似,将输入的序列由嵌入向量表示,然后通过循环或卷积网络的编码器将向量转换为隐状态,隐状态被送到注意力机制中,通过解码生成单个上下文向量。
上图为作者论文中使用的模型,第一层是节点和位置嵌入的串联,位置:距根节点的距离。GGNN编码器使用由不同颜色表示的边参数(edge-wise paras)来更新嵌入(在该示例中为ARG0和ARG1)。编码器还为每个节点添加相应的反向边(图上是较浅的虚线箭头)和自循环边(图上是深色的虚线箭头)。所有参数在层之间共享,注意力机制和解码器组件类似于标准s2s模型。

门控图神经网络
为了更容易学习节点之间长距离关系,提出了门控图神经网络(GGNN),它采用与门控递归单元(GRU)类似的门控机制,每一次更新数据时,每个节点既能接收相邻节点的信息,有可以向相邻节点发送信息。
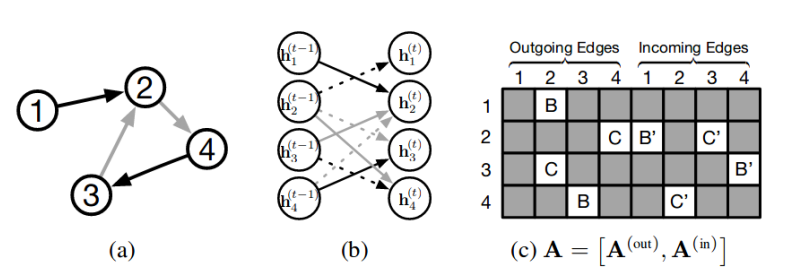
如图(a)中有4个节点,(c)可以看出节点之间连接关系,其中B,C,B',C'是边的特征,均为D*D维矩阵。矩阵A 有In和out两列,表示双向信息。
传播模型
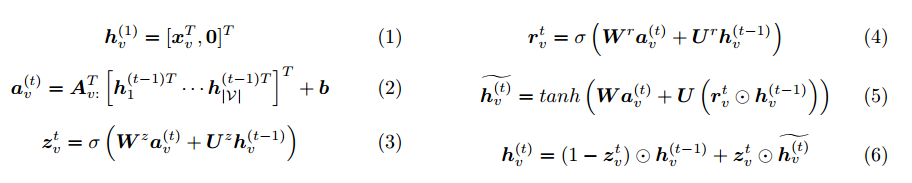
式(1)中h_v表示节点v的初态,是D维向量,当节点输入特征x维度小于D时,在后边补0。
式(2)即为图(c)中的矩阵A中选出来对应节点的两列;后边括号里边是将t-1时刻所有节点特征拼接。因此,式(2)表示节点与相邻节点间通过边的相互作用的结果。
式(3)-(6)类似GRU的计算过程。
输出模型
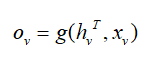
其中g是函数,表示利用逐个node的最终状态和初始输入分别求输出。
整张图输出一个值:
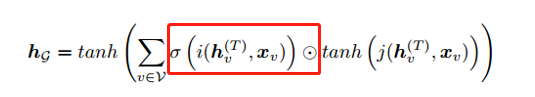
其中,i,j表示神经网络,红框是一种attention机制,用于选出哪个节点与整个graph的输出最相关。
本篇论文中与原始GGNN有所不同,但其核心内容不变。
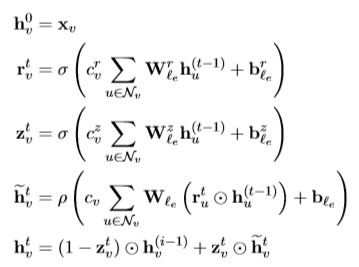
从上图公式中可以看出,本篇论文与原始GGNN的不同之处:本篇论文中在计算隐状态、复位门和更新门时增加了偏置;特定标签的矩阵不共享任何组件;在计算之前将复位门应用于所有的隐状态;添加归一化常数。
双向性和位置嵌入
在带根有向无环图,节点嵌入信息自顶向下的方式传播。然而,我们希望反方向也具有信息流,基于RNN的编码器以同样的方式从右向左的传播中(如在双向RNN中)受益。Marcheggiani和Titov、Bastings等人通过向图中添加反向边,以及每个节点的自循环边来实现此目的。这些额外的边具有特定的标签,因此它们在网络中具有自己的参数。
在这项工作中,还遵循此过程以确保信息在图中均匀传播。然而,这提出了另一个缺陷:因为图基本上变成无向的,编码器现在不知道输入中存在的任何内在层次结构,作者通过向每个节点添加位置嵌入(positional embeddings)来解决这个问题。这些嵌入(embeddings)由表示距根节点的最小距离的整数值索引,并作为模型参数进行学习。这种位置嵌入仅限于有根DAG图:对于一般图,可以采用不同的距离概念。
Levi图变换
就提出的G2S模型,存在两个关键缺陷:
1)GGNN每个边类型有三个线性变换,这样会造成参数的数量爆炸。
2)边标签信息以网络中的GGNN参数的形式编码,这意味着每个标签在所有图中都具有相同的”表示“,但实际中,边中的潜在信息可能取决于他们在图形中出现的内容。理想情况下,边应该具有特定实例(instance-specific)的隐状态,与节点的方式相同,并且这些隐状态也应该通过注意力模块通知解码器中的决策。
为了解决以上两个缺陷,将输入图转换为等效的Levi图。
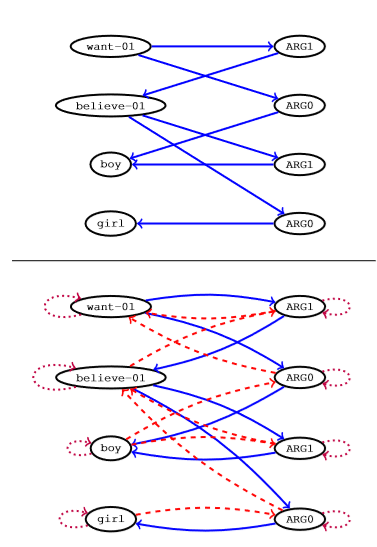
上图中上半部分将AMR图转换成相应的Levi图,下半部分为带有反向和自循环的Levi图。直观上看,这个图转换即将边转换为其他的节点。这样,原始边以和节点相同的方式表示为嵌入,编码器同样也将原始边生成隐状态。
实验一:AMR的语言生成
数据和预处理:我们使用最新的AMR语料库版本,默认分为 36521/1368/1371 个实例,用于训练/开发/测试集。使用类似于Konstas等人执行的程序对每个图进行预处理,包括实体简化和匿名化。此预处理要在将图形转换为等效的Levi图之前完成。
模型:我们的基线是注意力s2s模型,将线性图作为输入。其中编码器是BiLSTM,解码器是单向LSTM。对于g2s模型,我们将GGNN编码器中的层数设置为8。
所有模型的训练都使用Adam,初始学习率(lr)为0.0003,批量大小为16。为了使我们的模型正规化,我们在基于 混乱(perplexity)的开发集(development set)上提前停止,并且在源嵌入(source embeddings)上应用0.5的dropout。
评估:
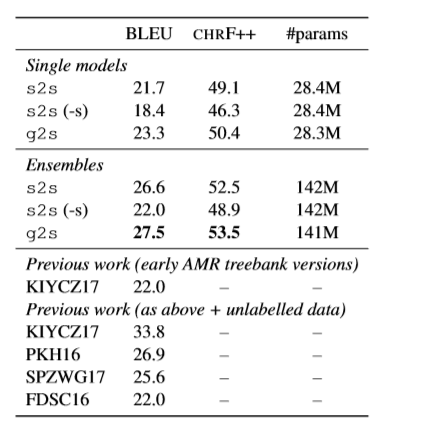
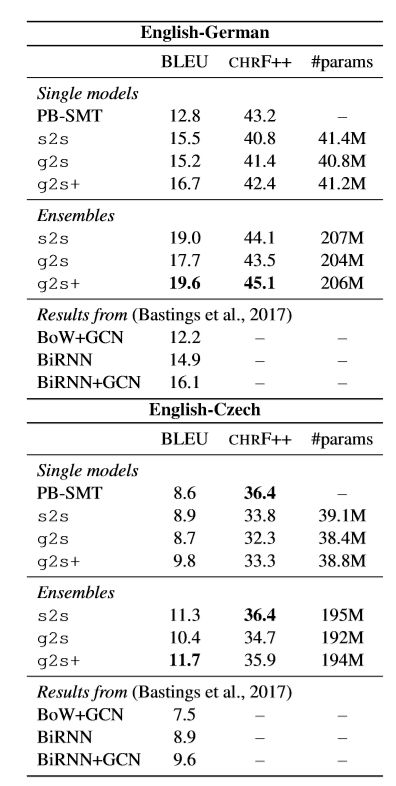
作者在BLUE、CHRF++上评估模型效果,从上表中可以看出作者提出的模型明显优于使用单独的S2S基线与集成的S2S基线。
实验二:基于语法的神经机器翻译
数据和预处理:使用Bastings等人提供的相同数据和设置,使用来自WMT16翻译任务的新闻评论V11语料库。使用SyntaxNet7对英文文本进行标记和解析,同时使用字节对编码(byte-pair encodings)对德语和捷克文本进行标记并将其拆分为子字(8000合并操作)。
模型:模型与上个实验中的模型一样,除了GGNN的维度不同。
评估:
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!560+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



