【CVPR2019教程】视频理解中的图表示学习
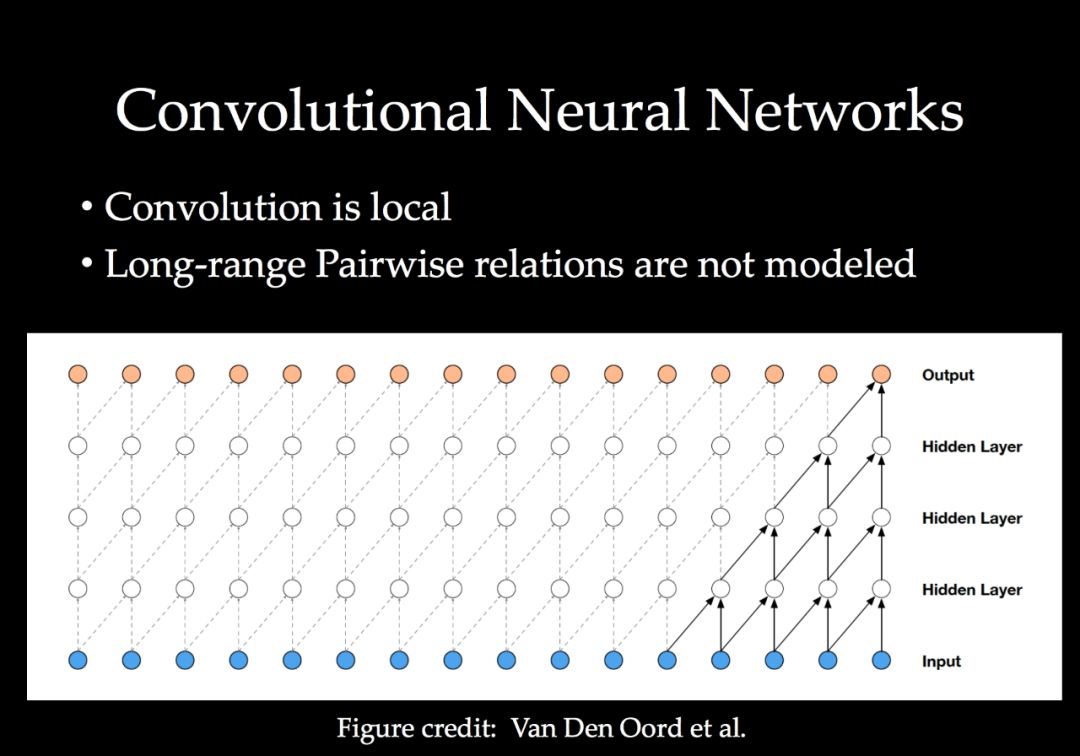
【导读】近年来,卷积神经网络(ConvNets)在众多计算机视觉任务中的应用出现了戏剧性的增长。卷积的结构被证明是强大的,在许多任务中捕捉相关性和抽象概念的图像像素。然而,当计算机视觉处理更困难的人工智能任务时,ConvNets也被证明在建模相当多的属性方面存在缺陷。这些特性包括成对关系、全局上下文和处理空间网格之外的不规则数据的能力。
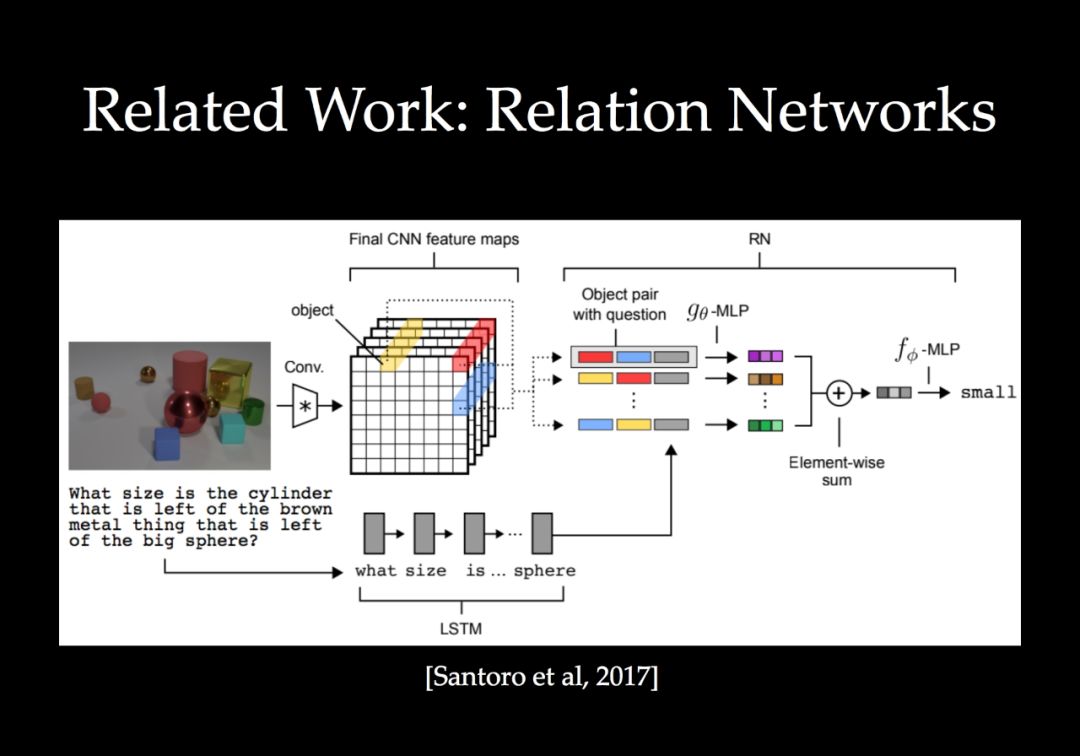
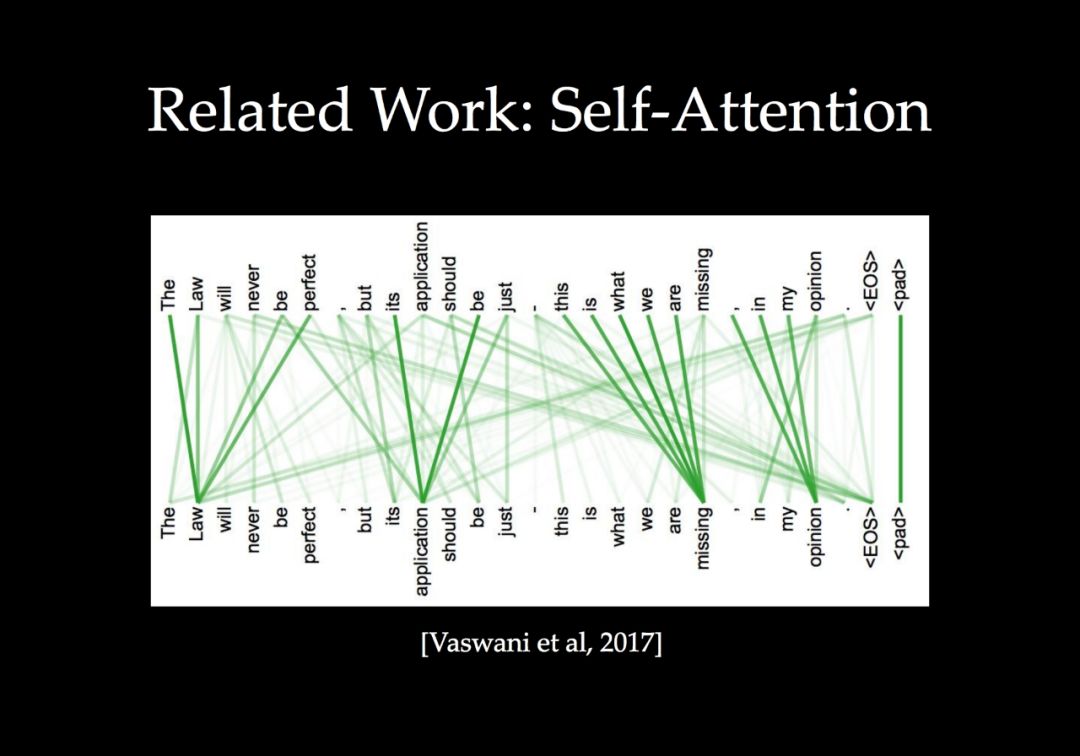
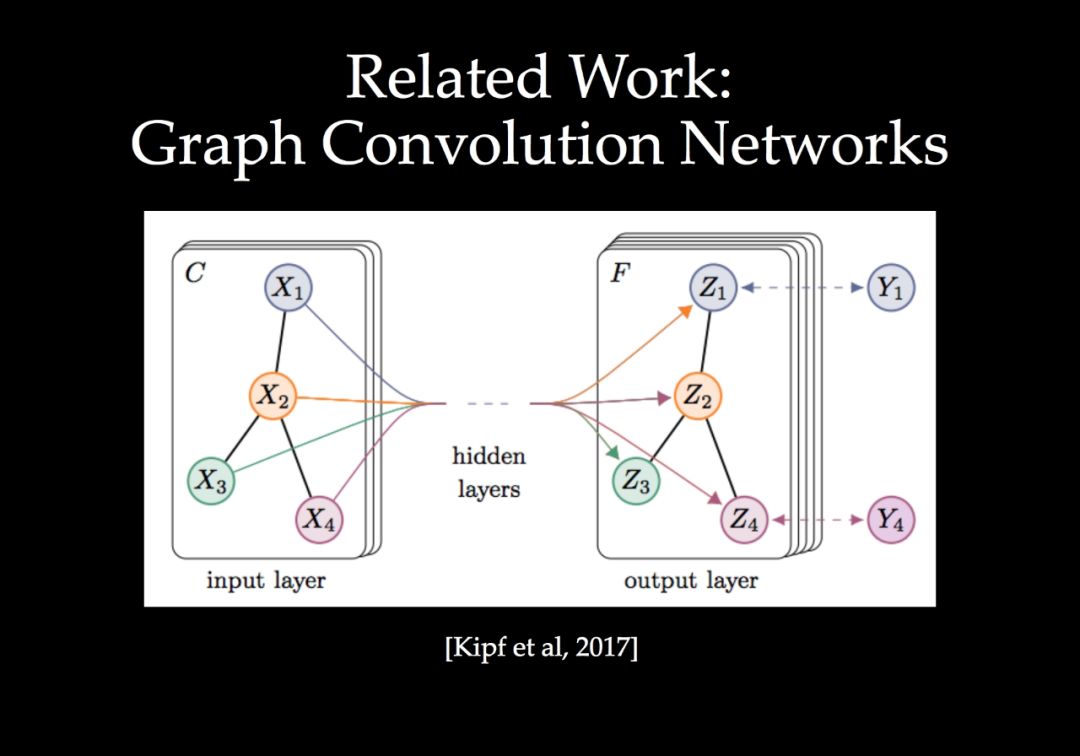
一个有效的方向是根据手头的任务用图重新组织要处理的数据,同时构建网络模块,在图中跨视觉元素关联和传播信息。我们将这些具有传播模块的网络称为图结构网络。在本教程中,我们将介绍一系列有效的图结构网络,包括非局部神经网络、空间传播网络、稀疏高维CNNs和场景图网络。我们也将讨论在许多视觉问题中仍然存在的相关开放挑战。
请关注专知公众号(点击上方蓝色专知关注)
后台回复“LGRVU” 就可以获取《Learning Graph Representations for Video Understanding》的下载链接~
【作者简介】
王小龙是卡内基梅陇大学机器人研究所的五年级博士生,导师是Abhinav Gupta教授。曾获得Facebook、NVIDIA、baidu Fellowship。他的研究方向是计算机视觉和机器学学习,如自主学习、视频理解、常识和互动等。
【部分PPT】




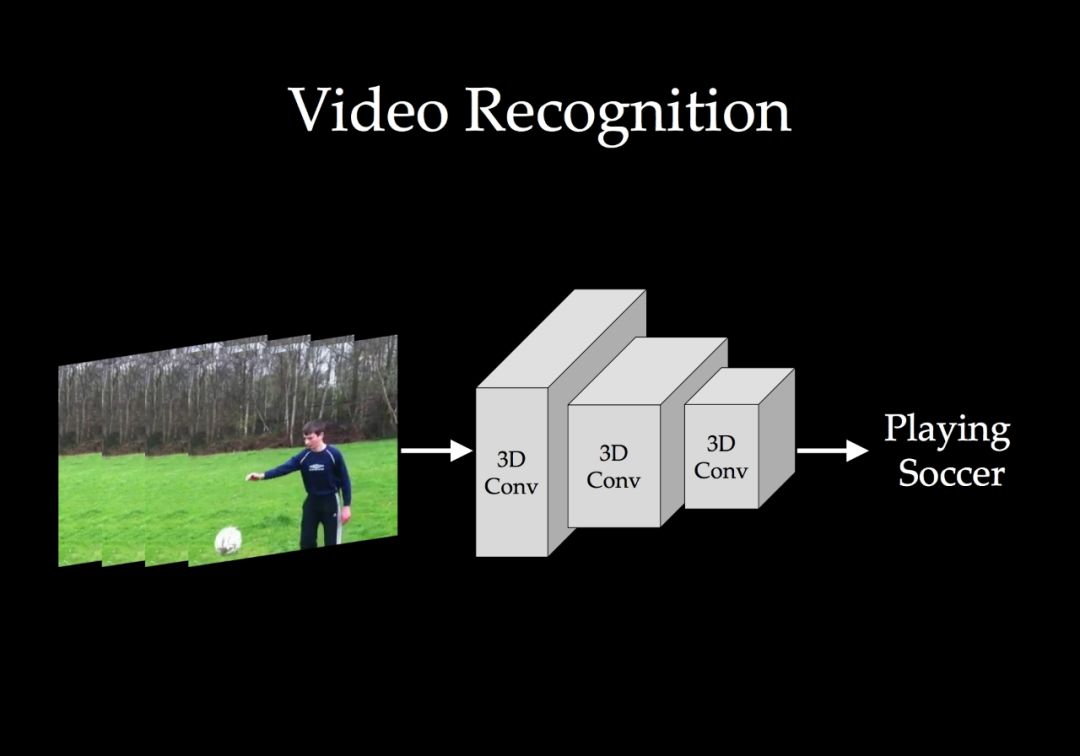




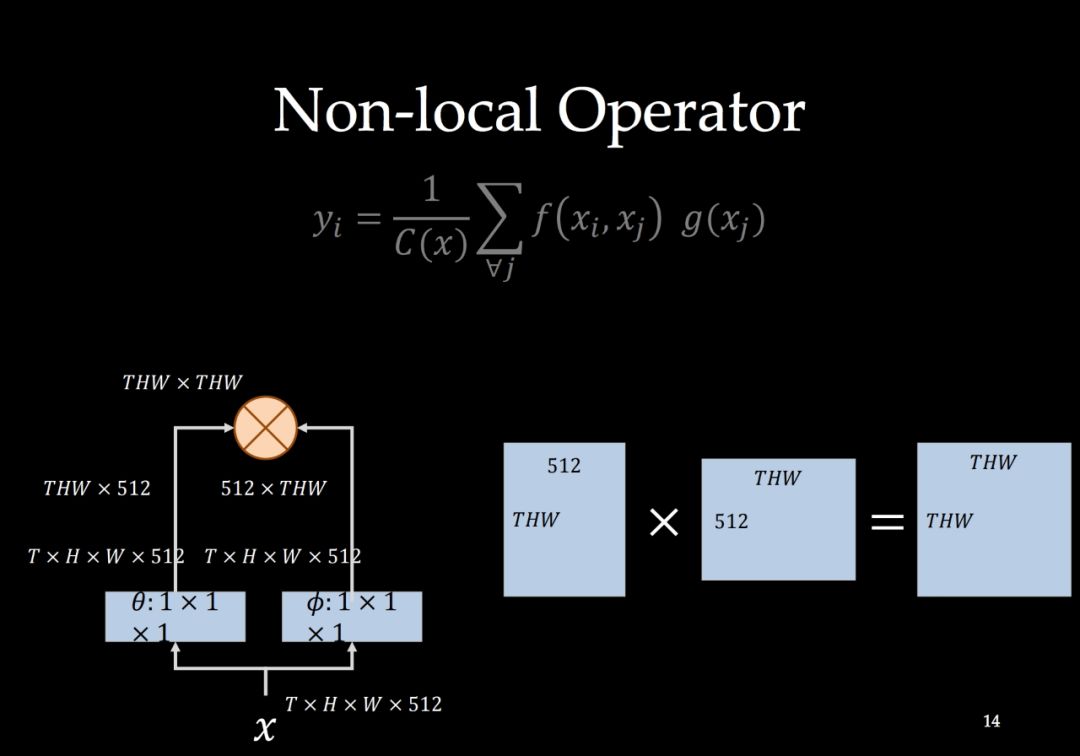
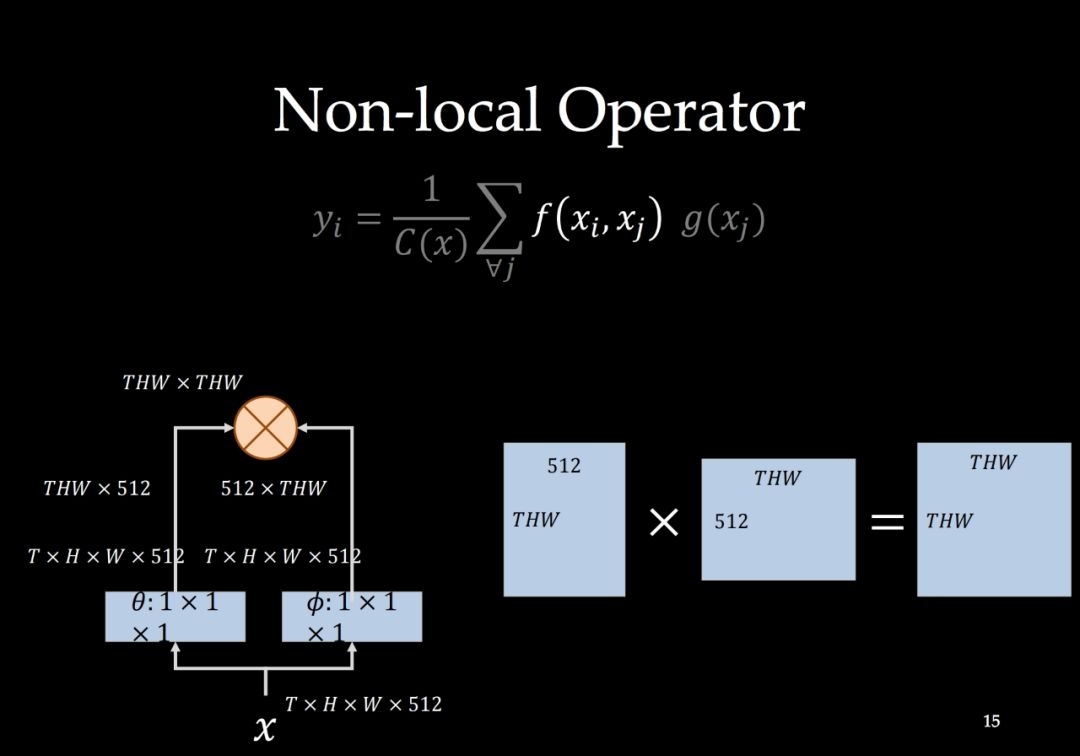


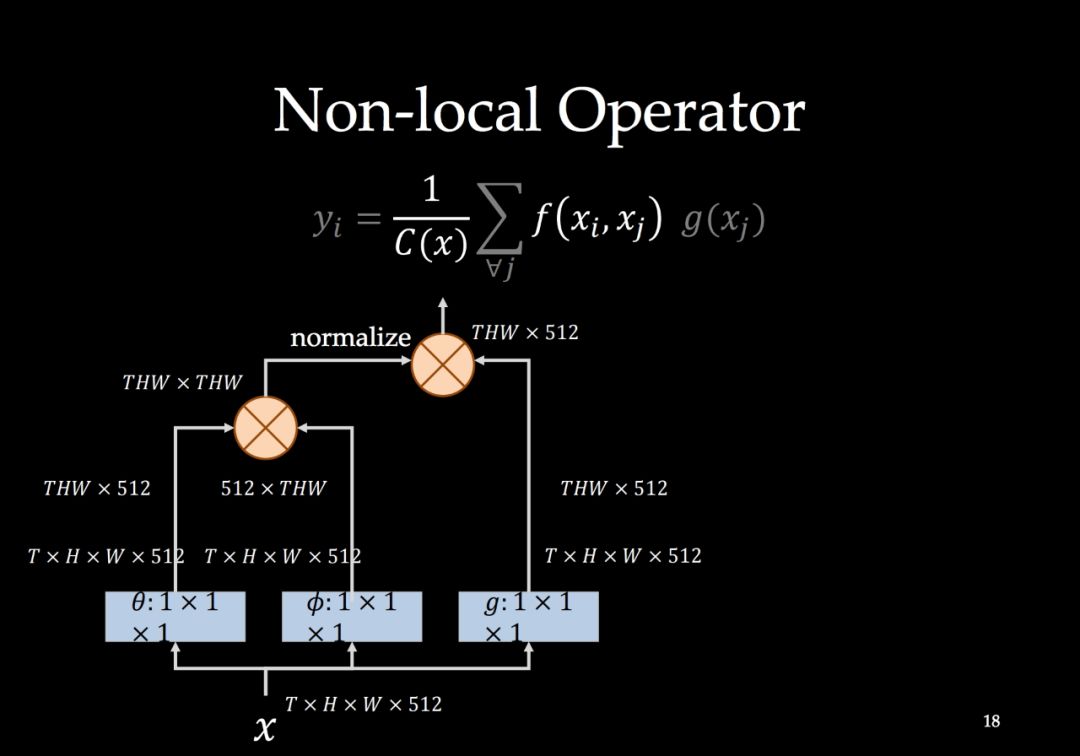
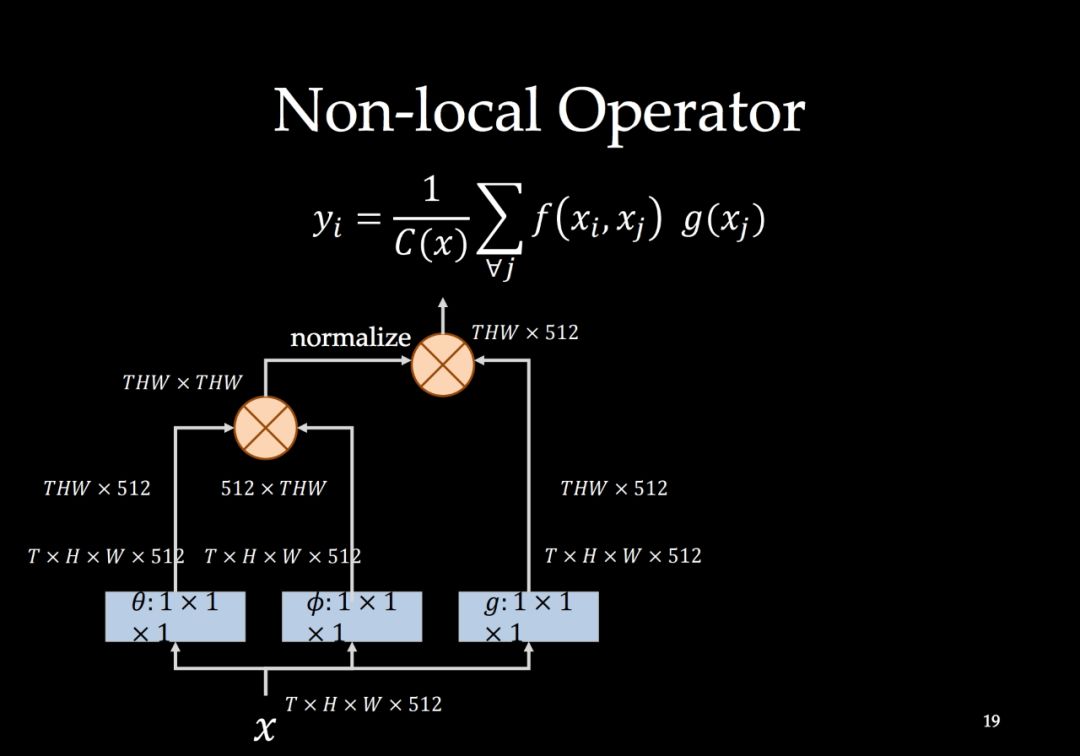
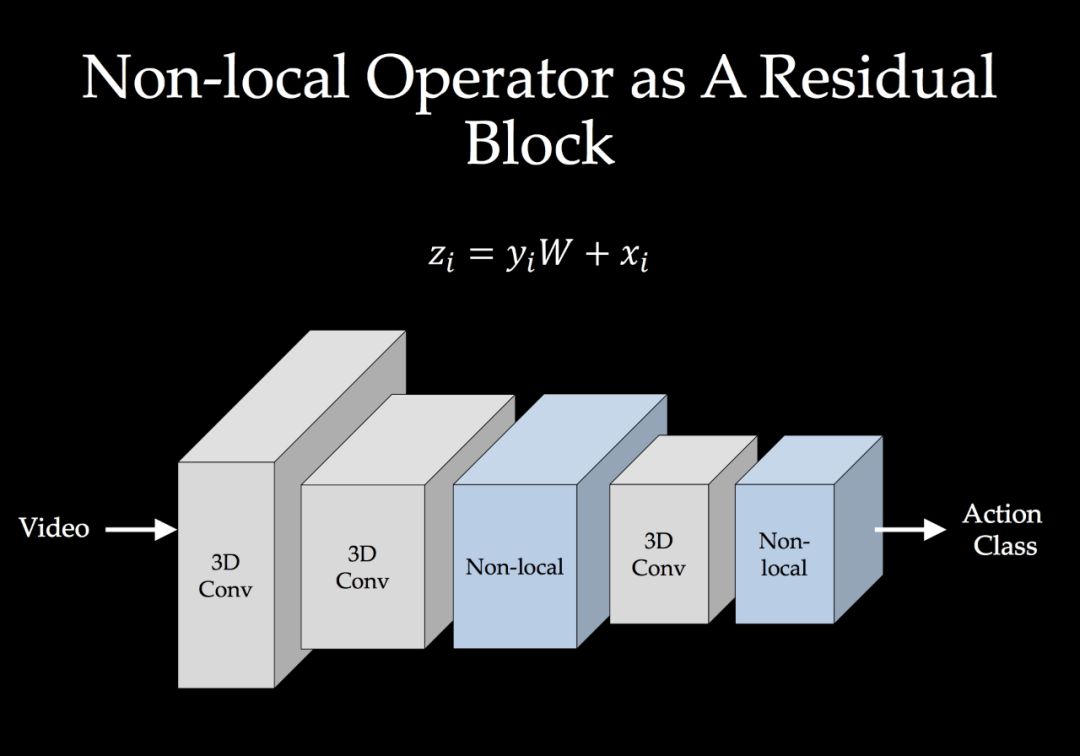
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!550+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



