十大必读「深度强化学习」论文-2019,SprekelerLab博士生Robert
【导读】深度强化学习(Deep Reinforcement Learning )是研究的热点之一,在2019年DeepMind OpenAI等发表多篇热门论文。来自SprekelerLab的博士生 Robert Tjarko Lange总结了2019年十大深度强化学习论文,涉及到大型项目、模型RL、多代理RL、学习动力学、组合先验等,值得一看。
2019年是深度强化学习(DRL)研究的重要一年,也是我在这一领域读博士的第一年。像每一个博士新手一样,我花了很多时间来阅读论文,实施一些有趣的想法,对重大问题有自己的看法。在这篇博客文章中,我想分享一些我从2019年文献中总结出来的亮点。
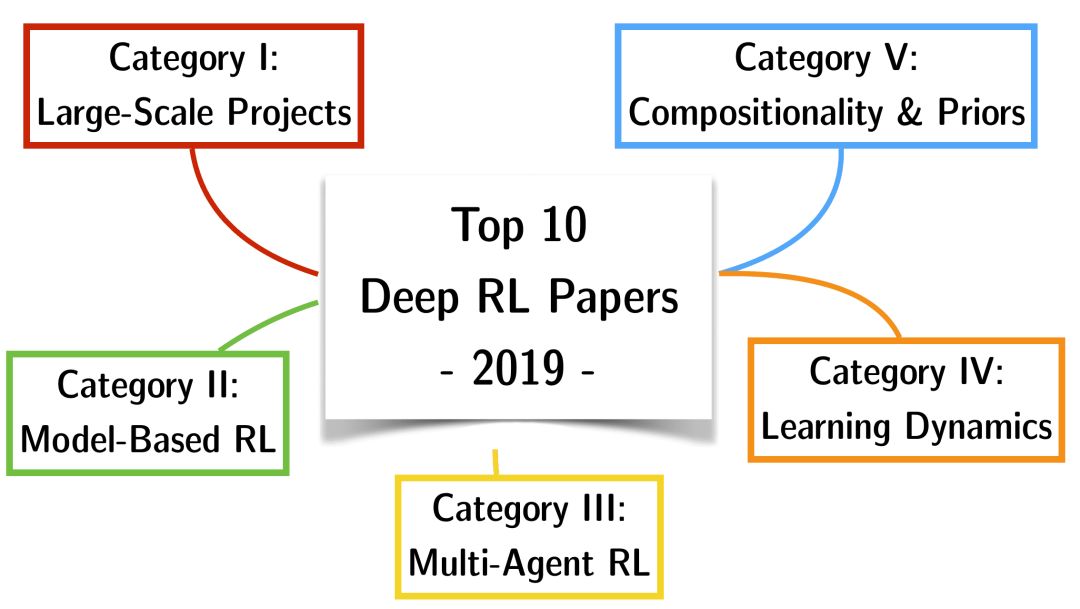
为了让这篇文章有更多的结构,我决定把论文分成5个主要类别,并选出一个冠军和亚军。进一步说,这是我2019年的十大DRL论文。
第一类: 大型项目
深度RL (如ATARI DQNs、AlphaGo/Zero)在2019年之前的大部分突破性成果,都是在行动空间有限、状态空间完全可见、授信时间尺度适中的领域中取得的。局部可见性、长时间尺度以及巨大的动作空间仍然是空缺的。另一方面,2019年证明了我们离将函数逼近与基于奖励的目标优化相结合的极限还很远。诸如《雷神之锤3》/《夺旗》、《星际争霸2》、《Dota 2》以及机器人手操作等挑战只是现代DRL能够解决的一部分令人兴奋的新领域。我试图根据科学贡献而不是现有算法的大规模扩展来选择第一类的获胜者。每个人如果有足够的计算能力-都可以做PPO一样的疯狂的事情。
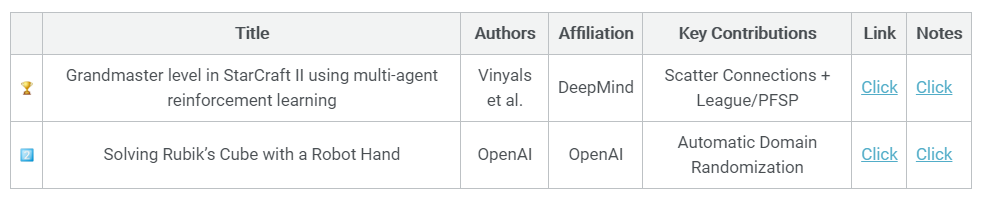
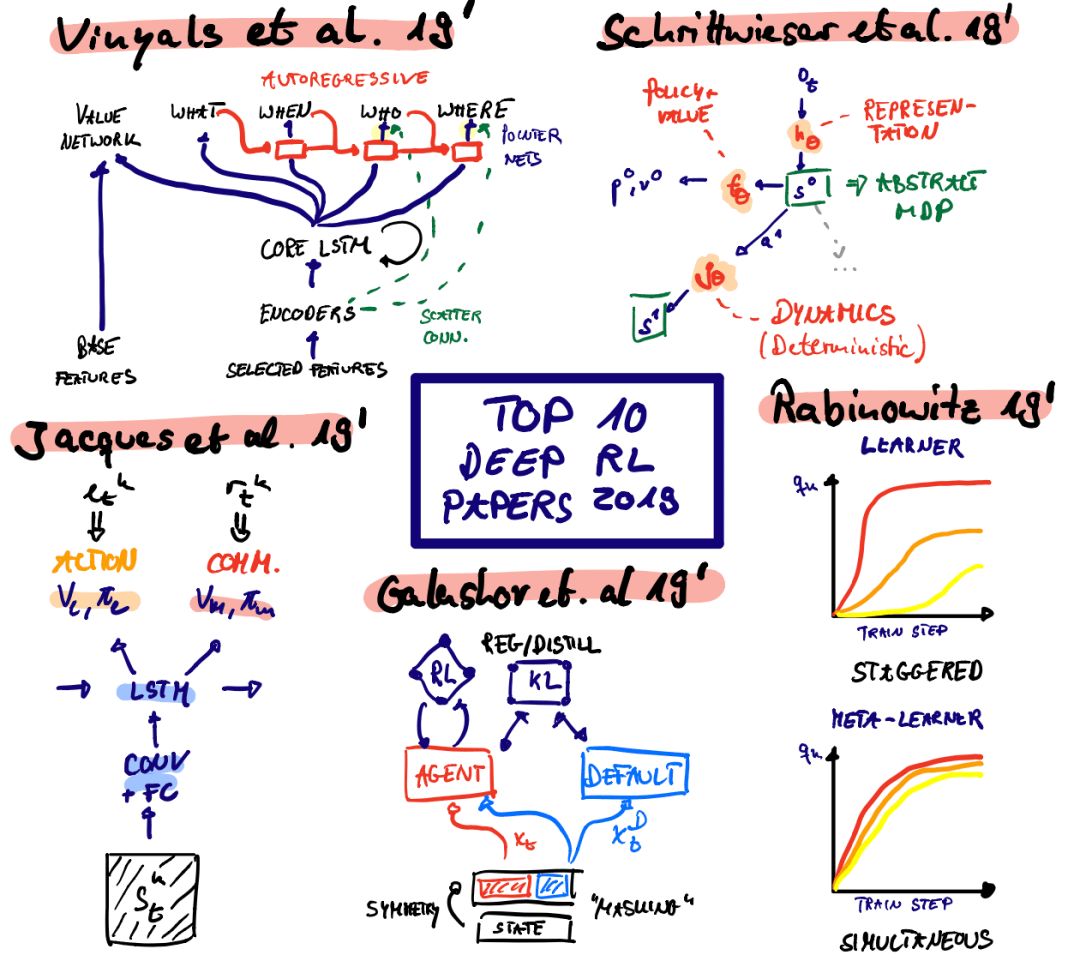
DeepMind AlphaStar (Vinyals et al, 2019)
DeepMind的AlphaStar项目由Oriol Vinyals领导。在阅读《自然》杂志的论文时,我意识到这个项目很大程度上是基于FTW设置来处理Quake III: 将分布式IMPALA的角色-学习者设置与诱导结构化探索的强大先验相结合。
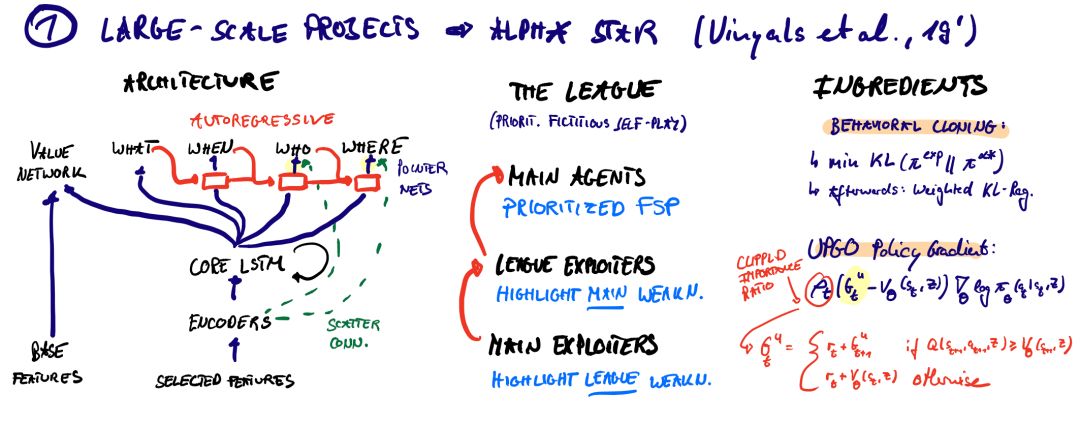
FTW使用基于两个LSTM的时间尺度层次结构的先验,而AlphaStar则使用人工示范。专家演示通过KL目标的监督最小化来预先训练代理的策略,并提供有效的正则化来确保代理的探索行为不会被星际争霸的维度诅咒所淹没。但这绝不是全部。科学贡献包括一个独特的版本虚构self-play(又名联盟),一个自回归分解与指针的策略策网络,上行策略更新的进化(UPGO - V-trace Off-Policy重要性抽样修正结构化操作空间)以及分散连接(一种特殊形式的嵌入,维护实体的空间相干映射层)。就我个人而言,我非常喜欢DeepMind,尤其是Oriol Vinyals对星际争霸社区的关心。很多时候,科幻小说让我们误以为电影是一场军备竞赛。但它是人为旨在提高我们的生活质量。
地址
https://deepmind.com/blog/article/AlphaStar-Grandmaster-level-in-StarCraft-II-using-multi-agent-reinforcement-learning
- OpenAI’s Solving’ of the Rubik’s Cube (OpenAI, 2019)
众所周知,深度学习能够解决需要提取和操作高级特征的任务。另一方面,低水平的灵活性,一种对我们来说很自然的能力,为当前的系统提供了一个主要的挑战。OpenAI灵巧性的贡献中,我最喜欢的是自动领域随机化(ADR):在机器人任务上训练深度RL代理的一个关键挑战是将仿真中所学到的知识转移到物理机器人上。模拟器只能捕获现实世界中有限的一组机制&精确地模拟摩擦需要计算时间。时间是昂贵的,否则可以用来在环境中产生更多的(但嘈杂的)过渡。提出了一种基于区域随机化的鲁棒策略。与用一组生成环境的超参数在单一环境中训练代理不同,该代理被训练在大量不同的配置上。ADR旨在设计一个环境复杂性的课程,以最大限度地提高学习进度。ADR根据agent的学习过程自动增加或减少可能的环境配置范围,为agent提供了一个伪自然课程。令人惊讶的是,这(加上基于ppo - lstm - gae的策略)导致了一种元学习形式,这种形式(到发布时)似乎还没有完全达到它的能力。Twitter上有很多关于“解决”这个词的讨论。该算法没有“完全”学习端到端解决一个立方体的正确的移动序列是什么,然后做所需的灵巧操作。但说实话,更令人印象深刻的是:用疯狂的奖励稀疏的手操作,还是学习一个相当短的符号转换序列?Woj Zaremba在2019年NeurIPS的“学习可转移技能”研讨会上提到,他们花了一天时间用DRL“解决立方体”&完全端到端的整个谜题是可能的。这是令人印象深刻。
第二类: 基于模型的强化学习 Model-based RL
虽然前两个项目令人兴奋地展示了DRL的潜力,但它们的采样效率低得可笑。我不想知道OpenAI和DeepMind必须支付电费是多少。有一些人通过在潜在空间中虚幻来提高样本(但不一定是计算)的效率,这是件好事。传统上,基于模型的RL一直在努力学习高维状态空间的动力学。通常,大量的模型容量不得不“浪费”在与状态空间无关的部分(例如,一个ATARI帧的最外层像素),而这与成功很少相关。最近,在一个抽象的空间里有很多关于规划/想象的提议。这是我最喜欢的两种方法:
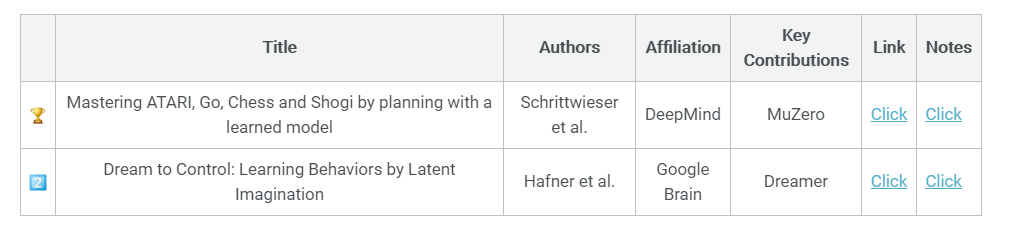

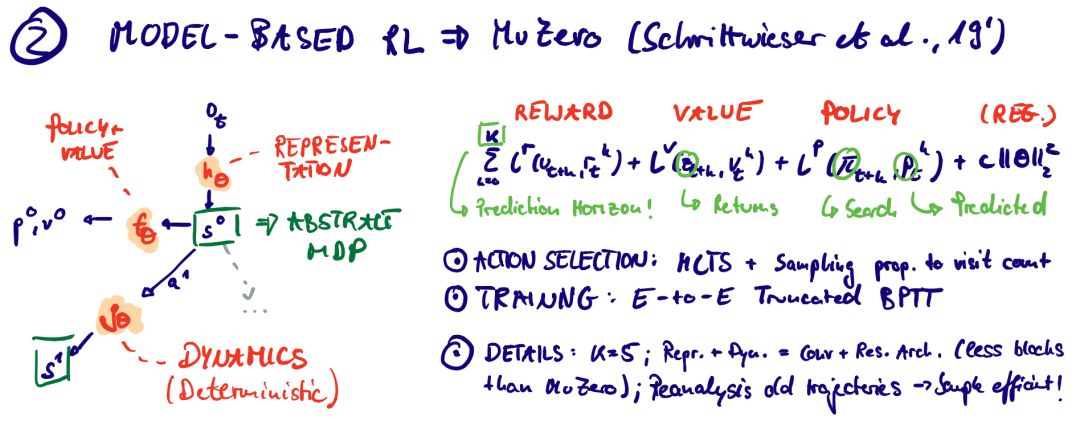
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, Timothy P. Lillicrap, David Silver:
Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model. CoRR abs/1911.08265 (2019)
MuZero提供了从AlphaGo/AlphaZero项目中删除约束的下一个迭代。具体来说,它克服了过渡动力学的认可。因此,“通用MCTS +函数逼近工具箱”可用于更一般的问题设置,如基于视觉的问题(如ATARI)。
Dreamer (aka. PlaNet 2.0; Hafner et al., 2019)
另一方面,“Dreamer”为连续的动作空间提供了原则性的扩展,能够驯服基于高维视觉输入的长视距任务。将表征学习问题分解为迭代学习一个表征、转换和奖励模型。通过使用想象的轨迹训练一个基于行为-临界的策略来交错整个优化过程。Dreamer通过一个世界模型的想象轨迹来传播学习状态值的“分析”梯度。更具体地说,利用再参数化技术,通过神经网络预测,可以有效地传播多步收益的随机梯度。该方法在DeepMind控制套件中进行了评估,能够基于64×64×3维视觉输入控制行为。最后,作者还比较了不同的表示学习方法(奖励预测、像素重建和对比估计/观察重建),结果表明像素重建通常优于对比估计。
Danijar Hafner, Timothy P. Lillicrap, Jimmy Ba, Mohammad Norouzi: Dream to Control: Learning Behaviors by Latent Imagination. CoRR abs/1912.01603 (2019)
第三类: 多代理强化学习 Multi-Agent RL
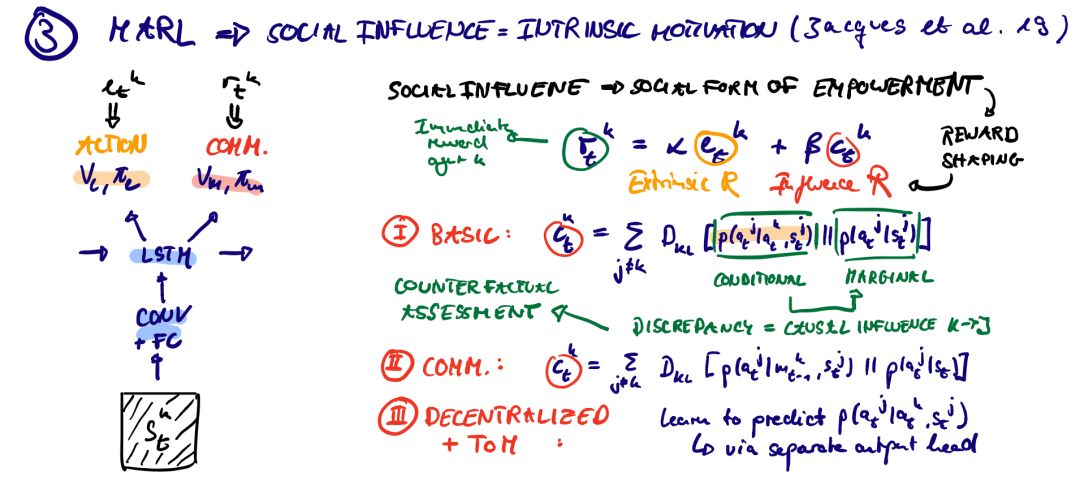
代理超越了简单的中央控制模式。我们的日常生活充满了需要预期和心理理论的情况。我们不断假设其他人的反应,并根据最近的证据重新调整我们的信念。通过梯度下降法进行的朴素独立优化容易陷入局部最优。这一点在一个简单的两个GAN特工训练的社会中已经很明显了。联合学习导致了环境中的一种非平稳性,这是多智能体RL (MARL)的核心挑战。两篇精选的MARL论文强调了两个中心观点:从经典的集中训练+分散控制范式转向社会奖励塑造&自我游戏的规模化使用和意想不到的结果。
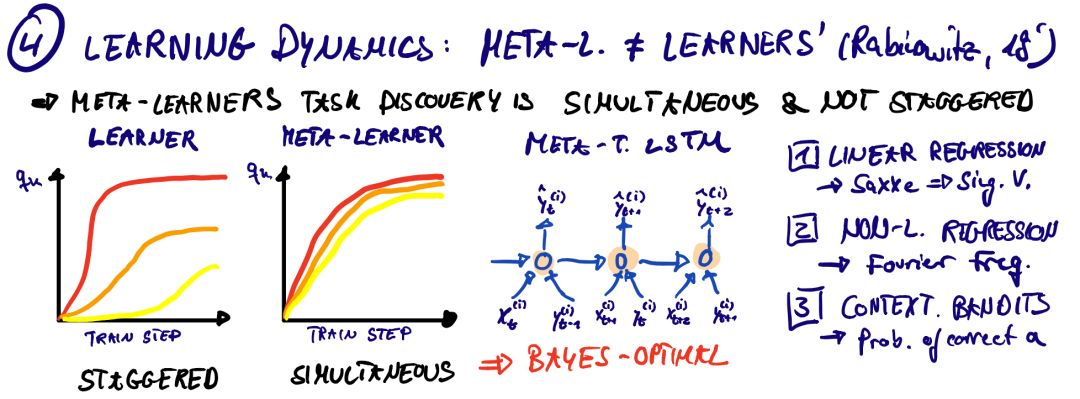
第四类: 学习动力学 Learning Dynamics
深层RL的学习动力学还远远没有被理解。与监督学习不同的是,在某种程度上,训练数据是给定的,并被视为IID(独立且同分布),RL需要一个代理来生成它们自己的训练数据。这可能会导致严重的不稳定性(例如致命的黑社会),任何玩弄过DQNs的人都会有这样的经历。仍然有一些重大的理论突破围绕着新的发现(如神经切线内核)。动力学类的两名获奖者突出了基于记忆的元学习(比RL更普遍)和基于策略的RL的基本特征。
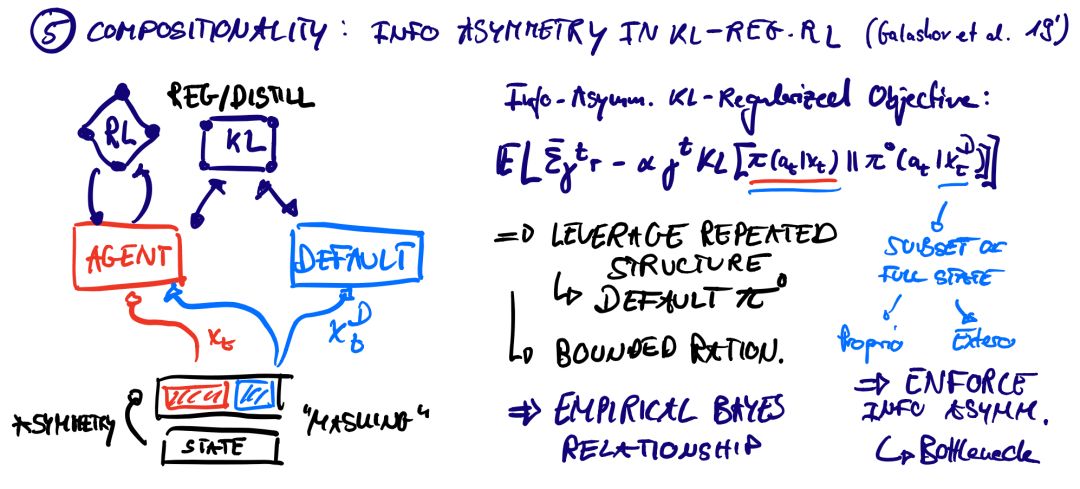
第五类: Compositionality & Priors 组合性&先验
一种获得有效和快速适应的代理的方法是知情先验。与基于非信息性知识库的学习不同,agent可以依赖于之前以先验分布的形式提取的知识,但是如何才能获得这些知识呢?以下两篇论文提出了两种截然不同的方法: 不确定目标的默认策略的同时学习&学习能够代表大量专家行为的密集嵌入空间。
结论
在整个2019年里,深度RL的巨大潜力在以前无法想象的领域得到了展现。重点介绍的大型项目还远远没有达到实地效率。但是这些问题正在被当前寻找有效的归纳偏差、先验和基于模型的方法所解决。
我对2020年将会发生的事情感到兴奋&我相信这是一个在这一领域的绝佳时机。有很多主要的问题,但是一个人所能产生的影响是相当大的。没有比现在更好的生活时机了。
地址:
https://roberttlange.github.io/posts/2019/12/blog-post-9/
References
Vinyals, O., I. Babuschkin, W. M. Czarnecki, M. Mathieu, A. Dudzik, J. Chung, D. H. Choi, et al. (2019): “Grandmaster level in StarCraft II using multi-agent reinforcement learning,”Nature, 575, 350–54.
Akkaya, I., M. Andrychowicz, M. Chociej, M. Litwin, B. McGrew, A. Petron, A. Paino, et al. (2019): “Solving Rubik’s Cube with a Robot Hand,” arXiv preprint arXiv:1910.07113, .
Schrittwieser, J., I. Antonoglou, T. Hubert, K. Simonyan, L. Sifre, S. Schmitt, A. Guez, et al. (2019): “Mastering atari, go, chess and shogi by planning with a learned model,” arXiv preprint arXiv:1911.08265, .
Hafner, D., T. Lillicrap, J. Ba, and M. Norouzi. (2019): “Dream to Control: Learning Behaviors by Latent Imagination,” arXiv preprint arXiv:1912.01603, .
Jaques, N., A. Lazaridou, E. Hughes, C. Gulcehre, P. Ortega, D. Strouse, J. Z. Leibo, and N. De Freitas. (2019): “Social Influence as Intrinsic Motivation for Multi-Agent Deep Reinforcement Learning,” International Conference on Machine Learning, .
Baker, B., I. Kanitscheider, T. Markov, Y. Wu, G. Powell, B. McGrew, and I. Mordatch. (2019): “Emergent tool use from multi-agent autocurricula,” arXiv preprint arXiv:1909.07528, .
Rabinowitz, N. C. (2019): “Meta-learners’ learning dynamics are unlike learners,’” arXiv preprint arXiv:1905.01320, .
Schaul, T., D. Borsa, J. Modayil, and R. Pascanu. (2019): “Ray Interference: a Source of Plateaus in Deep Reinforcement Learning,” arXiv preprint arXiv:1904.11455, .
Galashov, A., S. M. Jayakumar, L. Hasenclever, D. Tirumala, J. Schwarz, G. Desjardins, W. M. Czarnecki, Y. W. Teh, R. Pascanu, and N. Heess. (2019): “Information asymmetry in KL-regularized RL,” arXiv preprint arXiv:1905.01240, .
Merel, J., L. Hasenclever, A. Galashov, A. Ahuja, V. Pham, G. Wayne, Y. W. Teh, and N. Heess. (2018): “Neural probabilistic motor primitives for humanoid control,” arXiv preprint arXiv:1811.11711, .
Lowe, R., Y. Wu, A. Tamar, J. Harb, O. A. I. P. Abbeel, and I. Mordatch. (2017): “Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments,” Advances in Neural Information Processing Systems, .
Saxe, A. M., J. L. McClelland, and S. Ganguli. (2013): “Exact solutions to the nonlinear dynamics of learning in deep linear neural networks,” arXiv preprint arXiv:1312.6120, .
Rahaman, N., A. Baratin, D. Arpit, F. Draxler, M. Lin, F. A. Hamprecht, Y. Bengio, and A. Courville. (2018): “On the spectral bias of neural networks,” arXiv preprint arXiv:1806.08734, .
Wang, J. X., Z. Kurth-Nelson, D. Tirumala, H. Soyer, J. Z. Leibo, R. Munos, C. Blundell, D. Kumaran, and M. Botvinick. “Learning to reinforcement learn, 2016,” arXiv preprint arXiv:1611.05763, .
便捷查看下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“RL2019” 就可以获取《十大强化学习论文》专知资源链接索引



展开全文



