【论文推荐】最新九篇目标检测相关论文—常识性知识转移、尺度不敏感、多尺度位置感知、渐进式域适应、时间感知特征图、人机合作
【导读】专知内容组整理了最近七篇目标检测(Object Detection)相关文章,为大家进行介绍,欢迎查看!
1.Single-Shot Object Detection with Enriched Semantics(具有丰富语义的单次物体检测)
作者:Zhishuai Zhang,Siyuan Qiao,Cihang Xie,Wei Shen,Bo Wang,Alan L. Yuille
机构:Johns Hopkins University,Shanghai University,Hikvision Research
摘要:We propose a novel single shot object detection network named Detection with Enriched Semantics (DES). Our motivation is to enrich the semantics of object detection features within a typical deep detector, by a semantic segmentation branch and a global activation module. The segmentation branch is supervised by weak segmentation ground-truth, i.e., no extra annotation is required. In conjunction with that, we employ a global activation module which learns relationship between channels and object classes in a self-supervised manner. Comprehensive experimental results on both PASCAL VOC and MS COCO detection datasets demonstrate the effectiveness of the proposed method. In particular, with a VGG16 based DES, we achieve an mAP of 81.7 on VOC2007 test and an mAP of 32.8 on COCO test-dev with an inference speed of 31.5 milliseconds per image on a Titan Xp GPU. With a lower resolution version, we achieve an mAP of 79.7 on VOC2007 with an inference speed of 13.0 milliseconds per image.
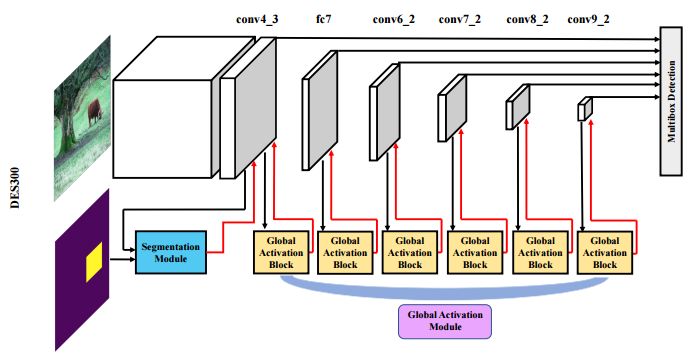
期刊:arXiv, 2018年4月8日
网址:
http://www.zhuanzhi.ai/document/da97041d6f1f72ed58f2193951e23a59
2.Transferring Common-Sense Knowledge for Object Detection(将常识性知识转移到物体检测中)
作者:Krishna Kumar Singh,Santosh Divvala,Ali Farhadi,Yong Jae Lee
机构:University of California,University of Washington
摘要:We propose the idea of transferring common-sense knowledge from source categories to target categories for scalable object detection. In our setting, the training data for the source categories have bounding box annotations, while those for the target categories only have image-level annotations. Current state-of-the-art approaches focus on image-level visual or semantic similarity to adapt a detector trained on the source categories to the new target categories. In contrast, our key idea is to (i) use similarity not at image-level, but rather at region-level, as well as (ii) leverage richer common-sense (based on attribute, spatial, etc.,) to guide the algorithm towards learning the correct detections. We acquire such common-sense cues automatically from readily-available knowledge bases without any extra human effort. On the challenging MS COCO dataset, we find that using common-sense knowledge substantially improves detection performance over existing transfer-learning baselines.
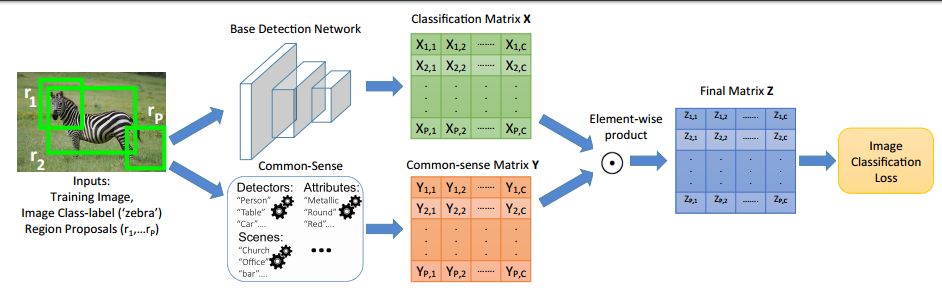
期刊:arXiv, 2018年4月4日
网址:
http://www.zhuanzhi.ai/document/3079821e1c2736d1ca1271c825251505
3.SINet: A Scale-insensitive Convolutional Neural Network for Fast Vehicle Detection(SINet:一种用于快速车辆检测的尺度不敏感的卷积神经网络)
作者:Xiaowei Hu,Xuemiao Xu,Yongjie Xiao,Hao Chen,Shengfeng He,Jing Qin,Pheng-Ann Heng
摘要:Vision-based vehicle detection approaches achieve incredible success in recent years with the development of deep convolutional neural network (CNN). However, existing CNN based algorithms suffer from the problem that the convolutional features are scale-sensitive in object detection task but it is common that traffic images and videos contain vehicles with a large variance of scales. In this paper, we delve into the source of scale sensitivity, and reveal two key issues: 1) existing RoI pooling destroys the structure of small scale objects, 2) the large intra-class distance for a large variance of scales exceeds the representation capability of a single network. Based on these findings, we present a scale-insensitive convolutional neural network (SINet) for fast detecting vehicles with a large variance of scales. First, we present a context-aware RoI pooling to maintain the contextual information and original structure of small scale objects. Second, we present a multi-branch decision network to minimize the intra-class distance of features. These lightweight techniques bring zero extra time complexity but prominent detection accuracy improvement. The proposed techniques can be equipped with any deep network architectures and keep them trained end-to-end. Our SINet achieves state-of-the-art performance in terms of accuracy and speed (up to 37 FPS) on the KITTI benchmark and a new highway dataset, which contains a large variance of scales and extremely small objects.
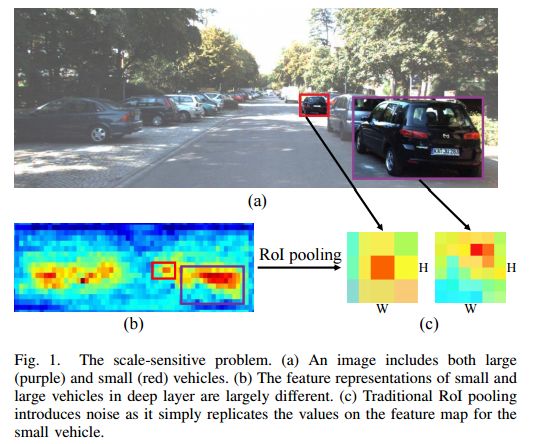
期刊:arXiv, 2018年4月2日
网址:
http://www.zhuanzhi.ai/document/a2666f4287abee7c3fb0ad29905b8bf2
4.Multi-scale Location-aware Kernel Representation for Object Detection(基于多尺度位置感知核化表示的物体检测)
作者:Hao Wang,Qilong Wang,Mingqi Gao,Peihua Li,Wangmeng Zuo
机构:Dalian University of Technology,School of Computer Science and Technology
摘要:Although Faster R-CNN and its variants have shown promising performance in object detection, they only exploit simple first-order representation of object proposals for final classification and regression. Recent classification methods demonstrate that the integration of high-order statistics into deep convolutional neural networks can achieve impressive improvement, but their goal is to model whole images by discarding location information so that they cannot be directly adopted to object detection. In this paper, we make an attempt to exploit high-order statistics in object detection, aiming at generating more discriminative representations for proposals to enhance the performance of detectors. To this end, we propose a novel Multi-scale Location-aware Kernel Representation (MLKP) to capture high-order statistics of deep features in proposals. Our MLKP can be efficiently computed on a modified multi-scale feature map using a low-dimensional polynomial kernel approximation.Moreover, different from existing orderless global representations based on high-order statistics, our proposed MLKP is location retentive and sensitive so that it can be flexibly adopted to object detection. Through integrating into Faster R-CNN schema, the proposed MLKP achieves very competitive performance with state-of-the-art methods, and improves Faster R-CNN by 4.9% (mAP), 4.7% (mAP) and 5.0% (AP at IOU=[0.5:0.05:0.95]) on PASCAL VOC 2007, VOC 2012 and MS COCO benchmarks, respectively. Code is available at: https://github.com/Hwang64/MLKP.

期刊:arXiv, 2018年4月2日
网址:
http://www.zhuanzhi.ai/document/e4a11f86460e9298c1ee11043c037b9e
5.Contrast-Oriented Deep Neural Networks for Salient Object Detection(用于显著目标检测的面向对比的深度神经网络)
作者:Guanbin Li,Yizhou Yu
摘要:Deep convolutional neural networks have become a key element in the recent breakthrough of salient object detection. However, existing CNN-based methods are based on either patch-wise (region-wise) training and inference or fully convolutional networks. Methods in the former category are generally time-consuming due to severe storage and computational redundancies among overlapping patches. To overcome this deficiency, methods in the second category attempt to directly map a raw input image to a predicted dense saliency map in a single network forward pass. Though being very efficient, it is arduous for these methods to detect salient objects of different scales or salient regions with weak semantic information. In this paper, we develop hybrid contrast-oriented deep neural networks to overcome the aforementioned limitations. Each of our deep networks is composed of two complementary components, including a fully convolutional stream for dense prediction and a segment-level spatial pooling stream for sparse saliency inference. We further propose an attentional module that learns weight maps for fusing the two saliency predictions from these two streams. A tailored alternate scheme is designed to train these deep networks by fine-tuning pre-trained baseline models. Finally, a customized fully connected CRF model incorporating a salient contour feature embedding can be optionally applied as a post-processing step to improve spatial coherence and contour positioning in the fused result from these two streams. Extensive experiments on six benchmark datasets demonstrate that our proposed model can significantly outperform the state of the art in terms of all popular evaluation metrics.
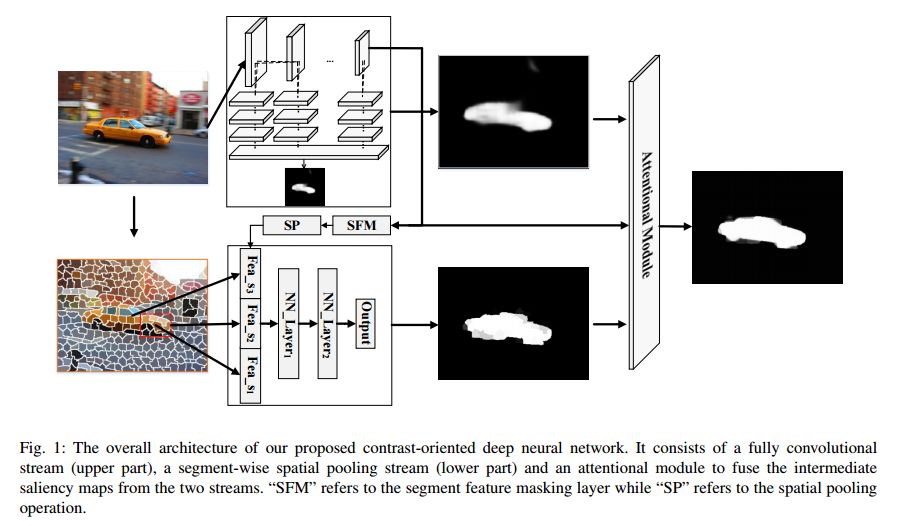
期刊:arXiv, 2018年3月30日
网址:
http://www.zhuanzhi.ai/document/2d2c703efabec0d009e07a454563f92f
6.Cross-Domain Weakly-Supervised Object Detection through Progressive Domain Adaptation(基于渐进式域适应的跨域弱监督物体检测)
作者:Naoto Inoue,Ryosuke Furuta,Toshihiko Yamasaki,Kiyoharu Aizawa
机构:The University of Tokyo
摘要:Can we detect common objects in a variety of image domains without instance-level annotations? In this paper, we present a framework for a novel task, cross-domain weakly supervised object detection, which addresses this question. For this paper, we have access to images with instance-level annotations in a source domain (e.g., natural image) and images with image-level annotations in a target domain (e.g., watercolor). In addition, the classes to be detected in the target domain are all or a subset of those in the source domain. Starting from a fully supervised object detector, which is pre-trained on the source domain, we propose a two-step progressive domain adaptation technique by fine-tuning the detector on two types of artificially and automatically generated samples. We test our methods on our newly collected datasets containing three image domains, and achieve an improvement of approximately 5 to 20 percentage points in terms of mean average precision (mAP) compared to the best-performing baselines.
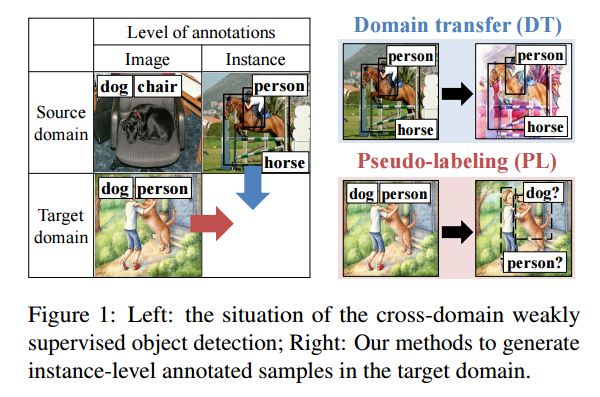
期刊:arXiv, 2018年3月30日
网址:
http://www.zhuanzhi.ai/document/e486a05cba7bb5961fe4b0c33594ed8b
7.Mobile Video Object Detection with Temporally-Aware Feature Maps(利用时间感知特征图的移动端视频物体检测)
作者:Mason Liu,Menglong Zhu
机构:Google
摘要:This paper introduces an online model for object detection in videos designed to run in real-time on low-powered mobile and embedded devices. Our approach combines fast single-image object detection with convolutional long short term memory (LSTM) layers to create an interweaved recurrent-convolutional architecture. Additionally, we propose an efficient Bottleneck-LSTM layer that significantly reduces computational cost compared to regular LSTMs. Our network achieves temporal awareness by using Bottleneck-LSTMs to refine and propagate feature maps across frames. This approach is substantially faster than existing detection methods in video, outperforming the fastest single-frame models in model size and computational cost while attaining accuracy comparable to much more expensive single-frame models on the Imagenet VID 2015 dataset. Our model reaches a real-time inference speed of up to 15 FPS on a mobile CPU.
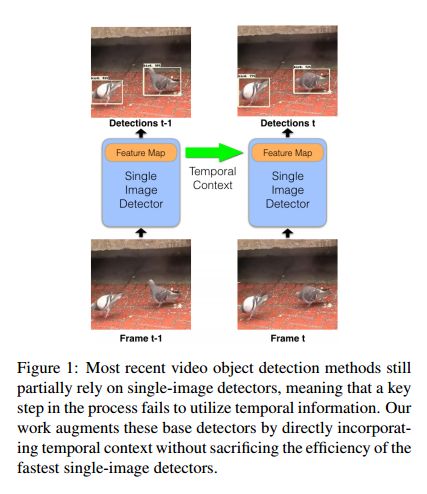
期刊:arXiv, 2018年3月29日
网址:
http://www.zhuanzhi.ai/document/92134bac4d1b997f51bb96ef6fe9d6f2
8.Dynamic Zoom-in Network for Fast Object Detection in Large Images( 基于动态Zoom-in网络的大图像中的快速物体检测)
作者:Mingfei Gao,Ruichi Yu,Ang Li,Vlad I. Morariu,Larry S. Davis
机构:Adobe Research,University of Maryland
摘要:We introduce a generic framework that reduces the computational cost of object detection while retaining accuracy for scenarios where objects with varied sizes appear in high resolution images. Detection progresses in a coarse-to-fine manner, first on a down-sampled version of the image and then on a sequence of higher resolution regions identified as likely to improve the detection accuracy. Built upon reinforcement learning, our approach consists of a model (R-net) that uses coarse detection results to predict the potential accuracy gain for analyzing a region at a higher resolution and another model (Q-net) that sequentially selects regions to zoom in. Experiments on the Caltech Pedestrians dataset show that our approach reduces the number of processed pixels by over 50% without a drop in detection accuracy. The merits of our approach become more significant on a high resolution test set collected from YFCC100M dataset, where our approach maintains high detection performance while reducing the number of processed pixels by about 70% and the detection time by over 50%.
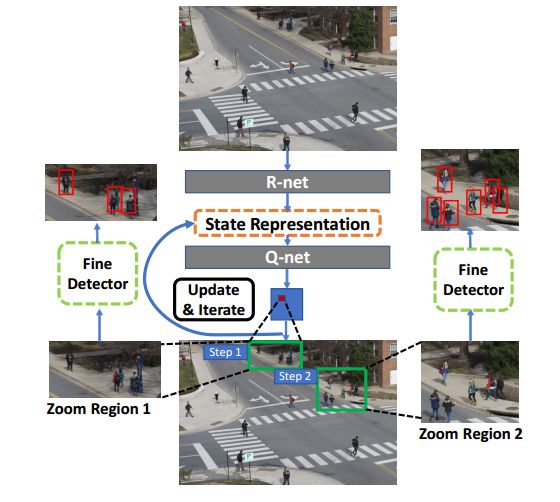
期刊:arXiv, 2018年3月27日
网址:
http://www.zhuanzhi.ai/document/3f713d0b55396afaeab8803effe5cc38
9.Towards Human-Machine Cooperation: Self-supervised Sample Mining for Object Detection(走向人机合作:用于物体检测的自监督样本挖掘)
作者:Keze Wang,Xiaopeng Yan,Dongyu Zhang,Lei Zhang,Liang Lin
机构:The Hong Kong Polytechnic University,Sun Yat-sen University
摘要:Though quite challenging, leveraging large-scale unlabeled or partially labeled images in a cost-effective way has increasingly attracted interests for its great importance to computer vision. To tackle this problem, many Active Learning (AL) methods have been developed. However, these methods mainly define their sample selection criteria within a single image context, leading to the suboptimal robustness and impractical solution for large-scale object detection. In this paper, aiming to remedy the drawbacks of existing AL methods, we present a principled Self-supervised Sample Mining (SSM) process accounting for the real challenges in object detection. Specifically, our SSM process concentrates on automatically discovering and pseudo-labeling reliable region proposals for enhancing the object detector via the introduced cross image validation, i.e., pasting these proposals into different labeled images to comprehensively measure their values under different image contexts. By resorting to the SSM process, we propose a new AL framework for gradually incorporating unlabeled or partially labeled data into the model learning while minimizing the annotating effort of users. Extensive experiments on two public benchmarks clearly demonstrate our proposed framework can achieve the comparable performance to the state-of-the-art methods with significantly fewer annotations.
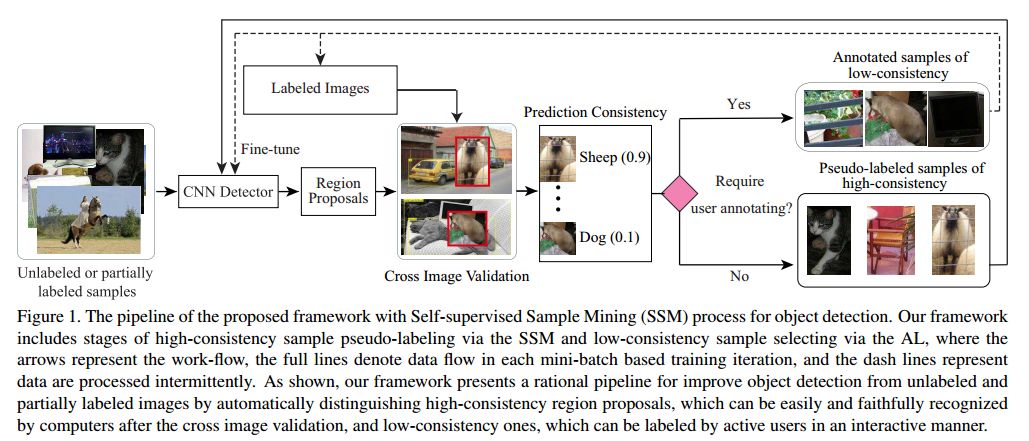
期刊:arXiv, 2018年3月27日
网址:
http://www.zhuanzhi.ai/document/bd34499b88e0aa916d815125d587d7a3
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
点击“阅读原文”,使用专知!
展开全文



