DeepMind最新Nature论文:基于元强化学习的神经科学新理论
【导读】近日,DeepMind 在 Nature 上发表的一篇论文引起人工智能和神经科学领域的极大震撼:DeepMind利用元强化学习来解释人类大脑的快速学习原理。过去二十多年基于多巴胺的反馈奖励机制成为神经科学的理论技术,而deepmind的新理论继续人工智能提出了一种新的奖励学习理论,它认为多巴胺实际通过训练前额皮质层来建立自己的学习系统。 这一新发现有望颠覆传统的神经科学研究方法,给以后的研究提供了一个全新的视角。

编译 | 专知
参与 | Mandy, Sanglei
Prefrontal cortex as a meta-reinforcement learning system
前额皮质层作为元强化学习系统
近年来,人工智能系统已经可以学习并攻陷相当一部分的游戏,比如Atari系列经典的Breakout和Pong游戏。尽管AI的表现很出色,但是要想达到并超越人类玩家的表现但是,它仍旧需要依赖于数千小时的游戏对战训练。相比之下,我们人类通常可以在几分钟内就掌握之前从未玩过的游戏的基础操作。
为什么大脑能够用这么少的东西做这么多的事情呢?这个问题催生了元学习(meta-learning)理论,或者说“learning to learn”。人们认为,我们在两个时间尺度上学习,分别是短期和长期学习。在短期内,我们专注于学习具体的单个游戏样例,而在更长的时间尺度上,我们学习完成一项任务所需的抽象技能或规则。正是这样的长短期组合被认为可以帮助我们进行高效地学习,并将这些知识快速灵活地应用于新任务。在AI系统中重建这种元学习结构(被称为元强化学习,meta-reinforcement learning),这种方法在促进我们agents的fast,one-shot learning方面被证明是非常有成效的(详见我们的论文【1】以及与OpenAI密切相关的工作【2】)。但是,这个过程在大脑中发生的具体机制在神经科学中仍未得到解释。
在我们在Nature Neuroscience上发表的新论文【3】中,我们使用元强化学习(meta-reinforcement learning)框架来研究多巴胺在大脑中的作用,特别是在帮助人类学习时的作用。多巴胺——通常被称为大脑的愉悦信号,它被认为与增强学习算法中使用的奖励预测误差信号(reward prediction error signal)类似。我们认为,多巴胺的作用不仅仅是利用奖励来学习过去行为的价值,而且它在前额叶皮层区域中扮演着不可或缺的角色,让我们能够高效、快速、灵活地学习新任务。
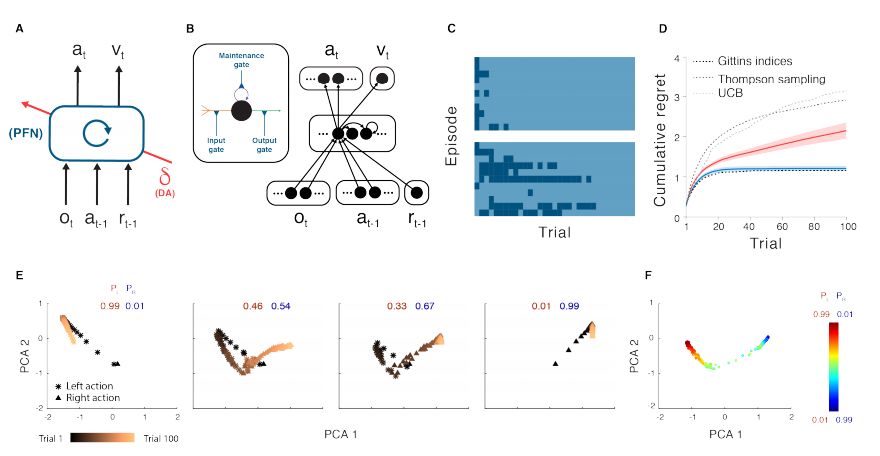
论文配图1. A. Agent 结构。B. 一个更详细的神经网络示意图。
我们通过虚拟重建神经科学领域的六个元学习实验来测试我们的理论,每个实验都需要一个agent来执行相应的任务,这些任务使用相同的基本原则(或一组技能),但在某些维度上有所不同。我们使用标准的深度强化学习技术(代表多巴胺的作用)训练一个递归神经网络(代表前额叶皮层),然后将这个递归神经网络的活动动态与之前在神经科学实验中发现的真实数据进行比较。递归神经网络是一个很好的元学习的agent,因为它能够内化过去的行为和观察,然后在训练各种各样的任务时借鉴这些经验。
在我们重建的众多实验中,其中一个实验叫做Harlow实验,这是一个20世纪40年代的心理学测试,用于探索元学习的概念。在最初的测试中,对于一组猴子,我们展示两个它们不熟悉的物品供它们选择,只有选择其中某一个时会给予它们食物奖励。这两个物品被展示了六次,每次左右放置的位置都是随机的,所以猴子们必须知道选择哪个物品会给予食物奖励。然后他们被展示了两个全新的物品,再次只有选择其中一个物品会获得食物奖励。在训练过程中,猴子们制定了一种策略来选择奖励关联对象:它们学会了第一次随机选择,之后便基于奖励反馈来选择特定对象,而不是左侧或右侧的位置。实验表明,这些猴子可以内化任务的基本原理,并且学习抽象的规则结构。实际上,这就是学会学习(learning to learn)。
当我们使用虚拟计算机屏幕【4】随机选择图像来模拟一个与猴子实验非常相似的测试时,我们发现我们的'meta-reinforcement learning agent'似乎以一种类似于Harlow实验中的动物的方式在学习,甚至在屏幕呈现从未见过的全新图像时也是如此。

事实上,我们发现“'meta-reinforcement learning agent”可以学习如何快速适应不同规则和结构的广泛任务。而且由于网络,它学会了如何适应各种任务,它还学会了进行有效学习的一般原则。
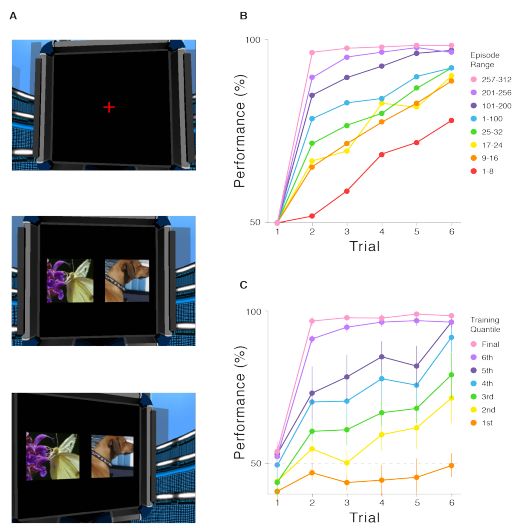
论文配图6.
重要的是,我们发现大部分的学习都发生在递归神经网络中,这一结果支撑了我们的设想,即多巴胺在元学习过程中起着比之前想象的更重要的作用。多巴胺传统上被理解为加强前额系统中的突触联系,从而加强特定的行为。在AI中,这相当于类多巴胺的奖励信号在神经网络中调整人工突触权重,因为它学习了解决任务的正确方法。但是,在我们的实验中,神经网络的权重被冻结,这意味着它们在学习过程中不能被调整。然而,”meta-reinforcement learning agent“仍然能够解决并适应新的任务。这表明,类多巴胺的奖励信号不仅用于调节权重,而且还能传递和编码有关抽象任务和规则结构的重要信息,从而更快适应新任务。
神经科学家长期以来在前额叶皮层观察到了类似的神经激活模式,这种模式能够快速适应新任务并且很灵活,但他们一直在努力寻找充分的理由来解释为什么会这样。前额叶皮层并不依赖于缓慢的突触权重变化来学习规则结构,而是使用抽象的基于模型的信息,直接编码在多巴胺中,这可以成为其具有多功能性的一个理由。
在证明引起meta-reinforcement learning的关键因素(成分)也存在于大脑中时,我们提出了一个理论,该理论不仅与已知的多巴胺和前额叶皮层的知识相符,而且还解释了一系列神经科学家和心理学家的神秘发现。特别是,该理论揭示了大脑中的结构化和基于模型的学习是如何形成的,为什么多巴胺本身含有基于模型的信息,以及前额叶皮质中的神经元如何调整为与学习相关的信号。利用人工智能领域的见解可以解释神经科学和心理学的发现,突出了每个领域可以提供的价值。展望未来,我们预期在逆向方向上可以获得很多益处, 我们期望在设计新的reinforcement learning agent模型时, 可以从脑回路的特定组织中得到指导。
这项工作由Jane X. Wang,Zeb Kurth-Nelson,Dharshan Kumaran,Druruva Tirumala,Hubert Soyer,Joel Z. Leibo,Demis Hassabis和Matthew Botvinick合作完成。
【1】https://arxiv.org/abs/1611.05763
【2】https://arxiv.org/abs/1611.02779
【3】https://www.nature.com/articles/s41593-018-0147-8
【4】https://deepmind.com/blog/open-sourcing-psychlab/
论文题目为:Prefrontal cortex as a meta-reinforcement learning system

链接:
htmlhttps://deepmind.com/blog/prefrontal-cortex-meta-reinforcement-learning-system/
更多教程资料请访问:专知AI会员计划
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



