【导读】关于利用卷积神经网络作为视觉系统的模型是否有生物学理论支持,目前仍然存在许多质疑之声。本文作者通过多年在计算神经领域的经验,以问答的形式详细阐述了CNN与神经科学的种种关联。
作者 | Grace Lindsay
编译 | 专知
参与 | Mandy, Yingying, Xiaowen
Deep Convolutional Neural Networks as Models of the Visual System: Q&A
就像我最近写的博客一样,我之所以会写这篇文章,是因为最近在twitter上的一个讨论【1】,特别是关于如何将深度卷积神经网络(CNN)的组件与大脑关联起来。然而,这里的大多数想法都是我一直在思考并谈论的东西。作为一个使用CNNs作为视觉系统模型的人,我经常(在研究会谈和其他对话中)必须为这个选择列出动机和支持。这在一定程度上是因为它们(在某些方面)是神经科学的新事物,同时也是因为人们对它们持怀疑的态度。在神经科学中,计算模型通常会出现松弛,这在很大程度上(但不完全)来自于那些不使用(或不构建)它们的人;计算模型经常被描绘成太不切实际或不实用。在这种氛围中,你会对深度学习/人工智能的过度炒作(以及它所获得的金钱利益)产生一种普遍的厌恶感,你会得到一个一些人非常讨厌的模型。
所以我在这里要做的是使用简单的问答(Q&A)的形式来尽可能合理和准确地解释使用卷积神经网络(CNNs)来建模生物视觉的图片。这个子领域还处于发展阶段,所以没有太多的确凿事实,但是我尽可能地列举一些东西。此外,这些显然是我个人对这些问题的回答(以及我的一些疑问),所以请酌情考虑它的价值。
我选择将CNNs作为视觉系统的模型,而不是更大的问题“深度学习能帮助我们理解大脑吗?”——因为我相信这是比较合理和卓有成效的领域(同时这也是我所从事的领域)。但是,没有理由证明这个一般的程序(指通过生物学和相关数据的训练来说明一个架构)不能用来帮助理解和复制其他的大脑区域和功能。当然,关于这个更大的问题可以在相关文章中找到【2,3】。
1. 什么是卷积神经网络(CNNs)?
卷积神经网络是一类人工神经网络。因此,它们由称为神经元的单元组成,它们接受输入的加权总和并由一个激活层输出。激活层输入的始终是非线性函数,通常会使用“ReLu”作为激活函数,保留所有正数的输入,而对于所有非正数输入则变为0。
CNNs的特殊之处在于神经元之间的连接方式。在前馈神经网络中,单元被组织成层,而给定层的单元只能从下面层的单元中得到输入(即不会出现来自同一层的其他单元的输入)。CNN是前馈网络。然而,与标准的vanilla前馈网络不同,CNN的单位有空间布局。在每一层,单元被组织成二维网格,称为feature maps(特征图)。每个特征映射都是在下面的层上执行一个卷积(convolution)的结果。这意味着在下面的层中的每个位置应用相同的卷积过滤器 (一组权重)。因此,在二维网格上的特定位置上的单元只能接收下面一层中相同位置的单元输入。此外,附加到输入的权重对于特征映射中的每个单元是相同的(并且不同的特征映射不同)。
在卷积(和非线性)之后,通常会做一些其他的计算。一种可能的计算方法(虽然在现代高性能的CNNs中不再流行)是交叉特征归一化(cross-feature normalization)。在这里,在某一个feature map中的某个特定空间位置的激活值,被其他feature map中相同位置的激活值除。一个更常见的操作是池化(pooling)。在这里,每个二维特征图网格的一个小空间区域的最大活动被用来表示该区域,这缩小了特征映射的大小。这组操作(convolution+nonlin[—->normalization]—>pooling)被统称为一个“层(layer)”。网络的体系结构是由层的数量和与之相关的各种参数的选择(例如,卷积滤波器的大小等)来定义的。
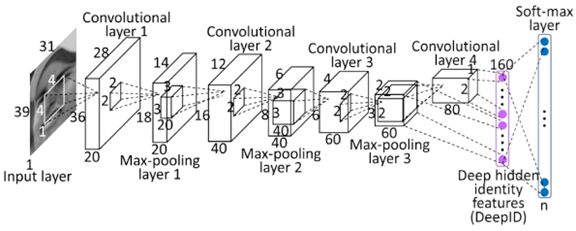
大多数现代的CNNs都有多个层(至少5个),最后进入一个全连接层(a fully-connected layer)。全连接层就像是标准的前馈网络,因为它们没有空间布局或连接受限制。经常使用2-3个全连接层,网络的最后一层执行分类操作。例如,如果网络正在执行一个10个对象分类,那么最后一层将有10个单元并且进行一个softmax操作以产生与每个类别相关的概率。
这些网络主要通过监督式学习和反向传播进行训练。在这里,图像对和它们相关的类别标签被输入进网络。图像像素值输入到网络的第一层,网络的最后一层产生预测类别。如果这个预测类别与实际类别不匹配,则通过计算梯度来确定权重(即卷积滤波器中的值)是否应该改变以使得分类正确。这样不断进行,做很多次(大多数情况下,这些网络都是在ImageNet数据库上训练的,它包含了1000个对象类别的100多万张图片),这些模型可以在测试图像上有很高的精确度。CNNs的变体现在可以达到4.94%的错误率【4】(或更低),好于人类的表现。许多训练“技巧”通常都是为了让这一工作顺利进行,比如学习率的选择和权重正则化(主要是通过dropout,在每个训练阶段,随机的一半的权重会被关闭)。
历史上,无监督预训练用于初始化权重,然后通过监督学习进行优化。但是,这对于已经具备良好性能的模型不再是必需的。
对于深入的神经科学家友好的CNNs的介绍, 请查阅论文: Deep Neural Networks: A New Framework for Modeling BiologicalVision and Brain Information Processing (2015)【5】
2.CNN是否是受视觉系统的启发?
是的。首先,作为整体的人工神经网络受到20世纪中期正在兴起的神经元新兴生物学的启发(正如其名称所示)。人造神经元被设计【6】用来模仿真正神经元的一些基本特征,比如它们是如何接收和转换信息的。
其次,卷积网络的主要特征和所做的计算直接受到视觉系统的一些早期发现的启发。 1962年,Hubel和Wiesel发现,初级视觉皮层中的神经元对视觉环境中特定的简单特征(特别是定向边缘)有反应。此外,他们注意到两种不同类型的细胞【7】:简单的细胞(它们只在非常特定的空间位置对它们的优选取方向作出最强烈的反应)和复杂的细胞(它们的反应具有更多的空间不变性)。他们得出结论:复杂的细胞通过汇集来自多个简单细胞的输入来实现这种不变性,每个简单细胞具有不同的首选位置。这两个特征(对特定特征的选择性和通过前馈连接增加空间不变性)构成了像CNNs这样的人工视觉系统的基础。
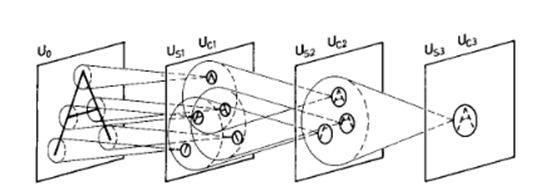
这一发现可以直接追溯到CNN的发展,通过一个称为Neocognitron的模型【8】(如下图)。这个模型由Kunihiko Fukushima在1980年开发,综合了目前关于生物视觉的知识,试图构建一个功能性的人造视觉系统。neocognitron由“S-cells”和“C-cells”组成,并通过无监督学习来学习识别简单图像。最初开发CNNs的人工智能研究员Yann LeCun明确表示【9】,他们是基于neocognitron展开研究的。
3.CNN从什么时候开始广受欢迎 ?
纵观计算机视觉的历史,许多工作都集中在手动设计图像中要检测的特征上,这些特征的选择是基于对信息最有价值的信念。在基于这些手工特性进行过滤之后,学习只在最后阶段完成,以便将这些特性映射到对象类。CNNs通过监督学习进行端到端的训练,因此提供了一种自动生成特征的方式,这种方法最适合于该任务。
第一个主要的例子是1989年,当LeCun et al.训练了一个小型CNN【10】,使用backprop进行手写数字识别。在1999年,随着MNIST数据集的引入,CNN的能力得到进一步发展和证明。尽管取得了这些成功,但由于训练过程被认为是困难的,并且非神经网络方法(如支持向量机support vector machines)变得风靡,使得这些方法逐渐从研究界消失。
下一个重大事件发生在2012年,当时CNN通过监督方法进行充分地训练,赢得了一年一度的ImageNet竞赛。那个时候,1000类对象分类的错误率为25%,但AlexNet【11】实现了16%的错误,这是一个巨大的改进。 ImageNet竞赛先前的赢家依赖于较老的技术,如浅层网络和支持向量机(SVMs)。随着CNNs的发展,使用了一些新技术,例如使用ReLu(代替sigmoid或双曲正切非线性函数),将网络分配给两个GPU,以及使用dropout正则化。早在2006年就可以看到神经网络的复苏,但是当时这些网络大多使用无监督的预训练(pre-training)。这个2012年的进展无疑是现代深度学习爆炸的一个重要时刻。
参考资料:DeepConvolutional Neural Networks for Image Classification: A Comprehensive Review(2017)【12】
4. CNNs和视觉系统相关联是什么时候开始的 ?
现如今的神经科学中关于神经网络的许多研究都来自于在2014年发表的一些研究。这些研究明确地比较了当不同的系统显示相同图像时,人类和猕猴的神经元活动与在CNNs中所记录的人工神经元的活动。
第一个是Yamins et al. (2014)【13】。这项研究探索了许多不同的CNN架构,以确定是什么导致了预测猴子IT细胞反应的良好表现。对于一个给定的网络,数据的一个子集用于训练线性回归模型,该模型将人工网络中的活动映射到单个IT细胞活动。对数据的预测能力被用来评估模型。
还使用了第二种方法,表征相似性分析【14】(representational similarityanalysis)。这种方法不涉及对神经活动的直接预测,而是问两个系统是否以同样的方式表示信息。这是通过为每个系统构建一个矩阵来完成的,矩阵中的值表示对两个不同输入的响应的相似程度。如果这些矩阵在不同的系统中看起来相同,那么它们表示的信息也是相似的。如下图所示:
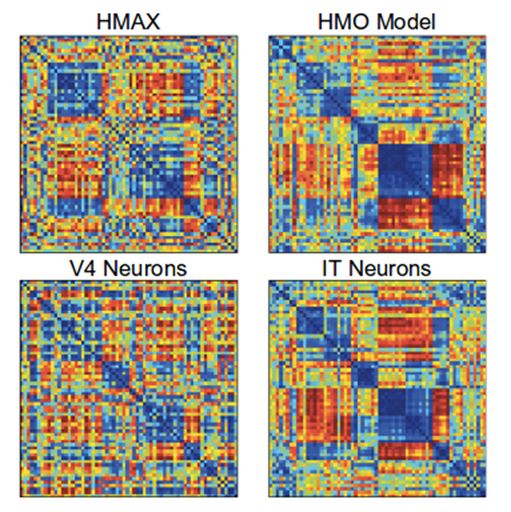
通过这两种方法,在对象识别,CNNs的优化优于其他模型。此外,第三层的网络更好地预测了V4细胞的活动,而第四层(和最终的)层更好地预测了IT细胞。这表明了模型层和大脑区域之间的一种对应关系。
另一个发现是,在对象识别上表现更好的网络在捕获IT细胞活动方面表现更好,而无需直接对IT数据进行优化。这一趋势在更大和更好的网络中大体上也是成立的【15】,达到了一定的限度(见Q11)。
另一篇论文,Khaligh-Razavi and Kriegeskorte(2014)【16】,也使用了表征相似性分析,将37种不同的模型与人类和猴子IT细胞进行比较。他们也发现在对象识别方面表现好的模型会更好地匹配IT表示。此外,通过监督式学习(“AlexNet”)训练的深度CNN是表现最好和最佳的匹配,网络中后面的层表现比以前更好(如下图所示)。
5. 神经科学家之前是否使用过任何类似CNNs的东西 ?
是的!第二个问题中提到的neocognitron模型灵感来自于Hubel和Wiesel的发现, 并进而启发了现代cnn, 但它也催生了视觉神经科学研究的一个分支, 这其中最突出的可能是TomasoPoggio【17】, Thomas Serre【18】, Maximilian Riesenhuber【19】以及 Jim DiCarlo【20】的实验室。Models basedon stacks of convolutions and max-pooling【21】被用来解释视觉系统的各种特性。这些模型倾向于使用与当前的CNN不同的非线性特性和无监督的特征训练(当时机器学习中也很流行),并且它们没有达到现代CNN的规模。
视觉神经学家和计算机视觉研究人员所走的道路,随着他们追求各自独立又相互关联的目标,有了不同的融合和分化。但总的来说,CNN可以被视为视觉神经科学家所设定的建模轨迹的延续。深度学习领域的贡献与计算能力和训练方法(以及数据)有关,这些方法使得这些模型最终能够发挥作用。
6. 我们有什么证据可以表明CNNs“像大脑一样工作(work like thebrain)”?
卷积神经网络有三个主要特征,可以支持它们作为生物视觉模型:(1)它们可以在接近人类水平的层面上执行视觉任务,(2)他们通过一个体系结构来复制已知的关于视觉系统的基本特征,(3)它们产生的活动直接关系到视觉系统中不同区域的活动。
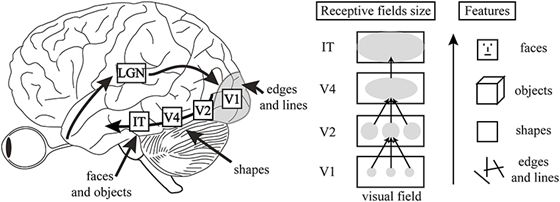
图:视觉层次结构的特征
首先,根据其本质和体系结构,它们具有视觉层次结构的两个重要组成部分。第一,随着我们在从V1到IT的进步中,随着我们在网络层面的进展,个体单元(units)的接受字段规模不断增长。第二,当我们在各个层上进行调整时,神经元会对越来越复杂的图像特征做出反应,就像从V1的简单线条到IT的对象部分一样。这种功能复杂性的增加可以直接通过CNN中可用的可视化技术【22】来看到。
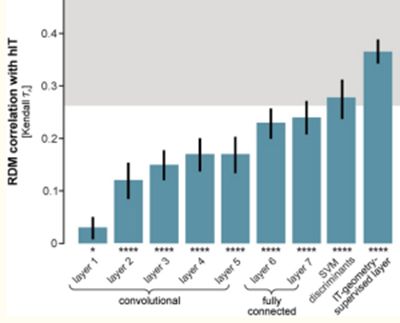
更深入研究(3),在2014年原始工作(Q4)之后的许多研究进一步确立了CNN中的活动与视觉系统之间的关系。这些都表现出相同的一般性发现:人造网络的活动可能与视觉系统的活动有关,当两者显示相同的图像时。此外,网络中后面的层对应于腹侧视觉流的后期区域(或者当响应诸如MEG的方法时后续的时间点)。

图:网络在不同层次上学习的特性的可视化
许多不同的方法和数据集被用来制造这些点,我们可以在如下的研究中看到: Seibertet al. (2016),Cadenaet al. (2017),Cichyet al. (2016), Wen et al. (2018),Eickenberget al. (2017), Güçlüand van Gerven (2015), and Seeliger et al. (2017).
这些研究的重点一般是对简要呈现的各种对象类别的自然图像的初步神经反应。因此,这些CNNs捕获了被称为“核心对象识别”【23】的东西,或者“即使是在保护身份的转换(位置、大小、视点和视觉环境)的情况下,也能快速区分给定的可视对象。”
由视觉系统产生的一系列神经表示可以被CNNs复制,这表明他们正在进行相同的“untangling”【24】过程。也就是说,两个系统都接受不同对象类别的表示,它们在图像/视网膜层次上是不可分割的,并且创建了允许线性可分性的表示。
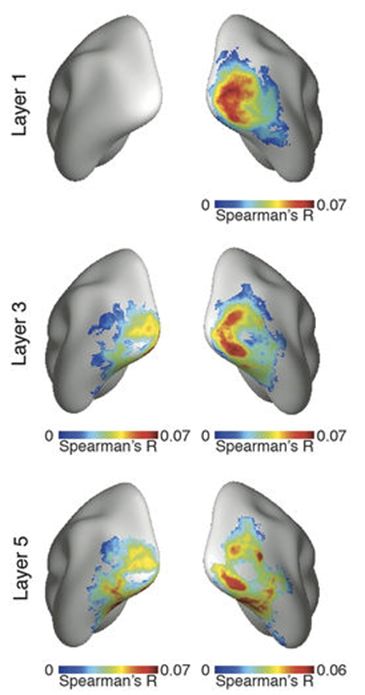
图:不同CNN层和脑区域的表示之间的相关性,from Cichy et al.
除了比较活动之外,我们还可以深入研究(1),即网络的性能。将这些网络与人类和动物的行为进行详细的比较,可以进一步验证它们作为模型的用途,并确定仍需要进展的领域。这类工作的发现表明,这些网络能够比先前模型在多个领域更好地捕捉人类分类行为的模式(甚至可以预测/操纵它),但在某些细节方面却存在不足,例如性能如何随着噪声而下降,或者当图像的变化很小时会如何。
这类行为效应在如下的论文中已经被研究了:Rajalinghamet al. (2018), Kheradpisheshet al. (2015), Elsayed etal. (2018), Jozwiket al. (2017), Kubilius et al. (2016), Dodge and Karam (2017), Berardino etal. (2017), and Geirhos et al. (2017).
是否所有这些都符合一个良好的人脑模型的规范,最好的方法都是通过观察视觉系统中人们对视觉系统模型的看法: “理解大脑对物体识别的解决方案需要我们构建人工识别系统,最终旨在模拟我们自己的视觉能力,通常是通过生物灵感(例如[2-6])。
这样的计算方法非常重要,因为它们可以提供实验性的可测试假设,并且由于工作识别系统的实例化是理解对象识别成功的特别有效的度量。“– Pintoet al., 2007
从这个角度来看, 很明显, CNNs并不代表视觉科学中目标的移动, 而是更多地涉及到它。
7. 其他模型能否更好地预测视觉领域的活动?
一般来说,没有。一些研究直接比较了CNNs和以前的视觉系统模型(如HMAX【25】)捕捉神经活动的能力。CNN排在第一位。这些研究包括:Yamins et al. (2014), Cichy et al. (2017), and Cadieu et al. (2014).
8.CNNs是关于视觉系统的机械性模型还是描述性模型?
机械模型的一个合理定义是模型的内部部分可以映射到感兴趣系统的内部部分。另一方面,描述性模型只与它们的总体输入-输出关系相匹配。因此,视觉系统的描述性模型可以是一个可以接受图像并输出与人类标签相对应的对象标签的方法,但是这样做的方式与大脑没有明显的关系。然而,如上所述,CNN的层可以被映射到大脑的区域。因此,CNNs是由腹侧系统所进行的表征转换的机械模型,因为它能够识别物体。
对于CNN来说,作为一个整体,机械模型并不要求我们接受所有的子组件都是机械的。以此为例,在传统的脑电路模型中使用基于速率的神经元。基于速率的神经模型只是一个将输入强度映射到输出firing rate的函数。因此,这些是神经元的描述性模型:模型的内部组件与导致firing rate的神经过程相关(详细的生物物理模型,例如Hodgkin-Huxley神经元是机械的)。然而,我们仍然可以使用基于速率的神经元来构建电路的机械模型(我喜欢的一个例子【26】)。所有的机械模型都依赖于描述性模型作为其基本单位(否则我们都需要去通过量子力学来构建模型)。
那么CNN的组成部分(即由卷积,非线性,可能归一化和池化组成的层)是大脑区域的机械性模型还是描述性模型呢?这个问题更难回答。虽然这些层由人造神经元组成,而这些人造神经元似乎可以被映射到(一组)真实的神经元,但是许多计算的实现不是生物学的。例如,正则化(在使用它的网络中)是用高度参数化的分裂方程实现的。我们相信这些计算可以用现实的神经机制来实现(参见上面引用的示例网络),但这些并不是目前在这些模型中使用的(尽管我和其他人正在研究它...参见Q12)。
9. 我们应该如何解释CNN中的不同部分与大脑的关系?
神经学家过去在细胞层面上处理事情,像CNNs这样的模型他们可能会觉得抽象,超出了实用性的意义(认知科学家已经从事抽象多区域建模一段时间,所以他们可能更熟悉)。
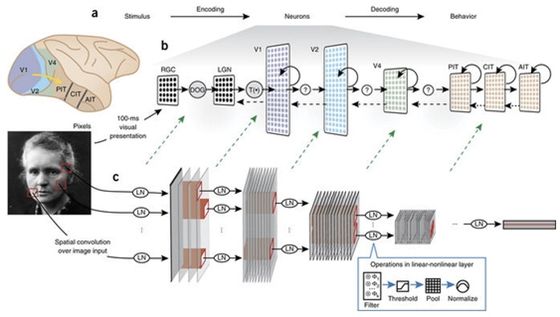
图:将CNN与大脑区域和处理相关联
但是,即使没有精确的生物学细节,我们仍然可以将CNN的组件映射到视觉系统的组件。首先,CNN的输入通常是3-D (RGB)像素值,它们在某种程度上被归一化,大致对应于由视网膜和外侧膝状核的计算。卷积的过程创建了具有空间布局的特征映射,就像视觉区域中的视网膜结构,这意味着每个人造神经元都有一个空间受限的接受域。与每个特征映射关联的卷积滤波器决定了该特征映射中的神经元的特征调整。单个的人工神经元并不意味着直接映射到单个的真实神经元;把单个单位看成是皮质柱(cortical columns)可能更合理。
CNN的哪些层对应于哪些脑区域呢?早期的工作使用的模型只包含少量的层,这为单层到大脑区域映射提供了支持。例如,在Yamins et al. (2014)中,最终的卷积层能够最好地预测IT细胞活动,其次是V4细胞的活动。然而,确切的关系将取决于所使用的模型(更深层的模型允许每个大脑区域有更多的层)。
卷积网络末端的全连接层具有更复杂的解释。它们与通过分类器之后的最终输出之间的密切关系以及它们不再具有视网膜视觉的事实使他们像前额皮质(prefrontal cortex-like)一样。但是他们在预测IT细胞活动时也可能会表现良好。
10.什么是视觉系统有的但CNN没有的?
有很多。尖刺,扫视,区分兴奋和抑制细胞,反馈连接,前馈连接,振荡,树突,皮质层,神经调质,不同的视觉细胞,适应性,也许是你最感兴趣的大脑细节。
当然,这些是目前标准的CNN没有的。但是其中很多已经被纳入了更新的CNN模型,例如:反馈连接,横向连接等【27-32】。
显然,CNN不是灵长类视觉的直接复制品。但我们知道,这并不代表CNN是不合格的。没有模型会(或应该是)某个系统的完整复制品。我们的目标是捕捉必要的特征来解释我们想知道的关于视觉的内容。不同的研究人员会想知道关于视觉系统的不同方面,因此缺少某个特定特征对不同人的意义都不一样。例如,为了预测IT神经元在第一100ms图像呈现中的平均响应,需要哪些特征?这是一个经验问题。我们不能先说需要所有的生物特征,或者模型没有它是不好的。
我们可以说没有细节的模型比如E-I 比具有细节的模型更抽象。但抽象并没有错。这仅仅意味着我们愿意将问题分解成一个层次结构并独立处理它们。有一天,我们应该能够拼凑出不同层次的解释,并且有一个模式可以在大而精的范围内复制大脑。
11.CNN做了什么视觉系统没做的事?
对我而言,这是更相关的问题。使用某种非生物魔法来解决棘手问题的模型比那些缺乏某些生物特征的模型更成问题。
第一个问题:卷积权重可以为正或为负。这意味着前馈连接有兴奋性的,也有抑制性的(而在大脑区域之间的连接大部分是兴奋性的)。我们可以简单地用权重表示它对网络的影响,这实际上可以通过与抑制性细胞的前馈兴奋性连接来执行,但这不是问题最大的地方。
接下来:权重是共享的。这意味着在同一特征图中,所有位置都是由同一权重通过不同的输入得到的。虽然在V1的视网膜视图中表现出类似于方向调谐的情况,但我们并不认为在视觉空间的不同神经元具有相同的权重。在视觉系统中,并没有一个机制可以确保所有的权重得到协调和共享。因此,当前使用权重共享来帮助训练这些网络应该能够被更具有生物学意义的方式所取代。
第三:最大池化是怎么回事?在神经科学术语中,最大池化操作类似于神经元的放电率等于其最高放电输入的放电率。由于这一点需要许多神经元的信息,很难设计一个可以直接做到这一点的神经元。但池化操作的灵感来自复杂细胞的发现,一开始使用的是平均池化,这是神经元可以轻易实现的。然而,最大池化【33】在物体识别性能和拟合生物数据方面已经被证明是更成功的【34】,并且现在被广泛使用。
机器学习研究人员对CNN的进一步改进使它与视觉系统越来越不一样(因为机器学习研究人员的目标仅仅是模型的表现)。一些表现最好的CNN现在具有许多从生物学角度看起来很奇怪的特征。此外,这些较新模型(50层)的深度使得它们的活动与视觉系统的关系更小【35】。
当然,这些网络是如何训练的(通过反向传播)的问题。这将在问题13中解决。
12.CNN能变得更像大脑吗?
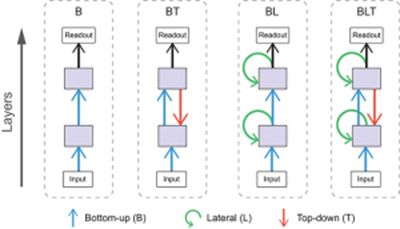
我成为一个计算神经科学家的主要原因之一是因为,我们可以做我们想做的任何事情。所以,是的!受生物特征的启发,我们可以让标准的CNN具有更多的功能。让我们看看到目前为止已经做了些什么:
如上面在Q10中所提到的,许多元素已被添加到CNN的不同变体中,这使得它们更接近一个真实的视觉系统。此外,为了增加学习过程的合理性已经做了工作(见Q13)。
除了这些努力之外,一些更具体的复制生物细节的工作包括:
Spoerer et al.(2017),受生物学启发,展示了如何增加横向和反馈连接,使模型更好地识别闭塞和嘈杂的物体。
Costa et al.(2017)实施了使用生物激励组件的长短期记忆网络。当人工神经网络中加入递归时,经常使用LSTM,因此确定它们的功能如何在生物学上实现是非常有用的。
13.CNN使用反向传播来学习他们的权重的意义?
反向传播涉及网络中任何位置的权重应该如何改变来减少最终的误差。这意味着,第一层的神经元会有一些信息,说明在顶层发生了什么问题。。然而,真正的神经元倾向于依赖于局部学习规则,权重的变化主要由与之相关的神经元决定,但不会受太远的神经元的影响。因此,反向传播并没有真正反映生物学的现象。
这并不需要影响我们把训练好的CNN模型作为视觉系统的解释。计算模型中的参数通常使用的技术并不打算与大脑学习方式有任何相似之处(例如贝叶斯推理以获得功能连通性)。然而,这并不会使得出的电路模型无法解释。那么,在极端的情况下,我们可以将反向传播看作仅仅是参数拟合工具。事实上,Yamins et al (2014)确实使用了不同的参数拟合技术(而不是反向传播)。
然而,采取这种观点确实意味着该模型的某些方面不适合解释。例如,我们不希望学习曲线(即模型学习时误差如何变化)与人类或动物学习时产生的错误相关。
尽管当前使用反向传播在生物学上并不合理,但它可以被解释为大脑实际正在做的事情的抽象版本。研究者们正在进行各种努力,实现学习过程的生物合理性。这将对学习过程以更好地进行生物学解释。使用更合理的生物学习程序是否会导致与数据更匹配的神经活动是尚未解答的经验问题。
另一方面,无监督学习是大脑最有可能的机制,因为它不需要关于标签的明确反馈,而是利用自然环境来生成表示。到目前为止,无监督学习还没有达到监督学习的性能。但是,无监督学习方法的进步可能催生更好的视觉系统模型。
14.我们如何用CNN学习视觉系统?
孤立地从CNN中学不到任何东西。所有的见解和发展都需要通过在实验数据基础上进行验证。也就是说,CNN有三种方式可以帮助我们理解视觉系统。
首先是验证我们的直觉。费曼的解释是“我们不明白我们无法建立的东西。”对于所有收集的数据和有关视觉系统的理论,为什么神经科学家不能制作一个功能正常的视觉系统呢?这应该是令人震惊的,因为它意味着我们错过了一些至关重要的东西。现在我们可以说我们对视觉系统的直觉大致是正确的,我们只是缺少计算能力和训练数据。
其次是考虑到理想化的实验测试场地。这是科学中机械模型的常见用法。我们使用现有的数据来建立一个模型。然后我们对模型进行各种各样的调节,来实现我们真正需要的功能。这可以作为未来实验的假设生成和/或解释以前未用于构建模型的数据的方法。
第三种方法是通过数学分析。与计算建模一样,将我们关于视觉系统如何工作的信念纳入具体的数学术语。虽然对模型进行分析通常需要进一步简化,但它仍然可以提供有关模型行为的一般趋势和局限性的有用见解。一些机器学习研究人员也对用数学解剖这些模型感兴趣。
15.我们用CNN建模视觉系统学到了什么?
首先,我们验证了我们的直觉,表明CNN实际上可以建立一个有效的视觉系统。此外,这种方法帮助我们定义了计算和算法级别的视觉系统。训练捕捉神经和行为数据的能力是视觉系统进行物体识别的核心。卷积和和池化是实现它的算法的一部分。
我相信,这些网络的成功也有助于改变我们队视觉神经科学研究的认知。许多视觉神经科学一直研究以个体细胞为主。而对视觉系统进行抽象建模之后,并没有对某一个特定神经元进行限制,而是将重点放在群体编码上。试图理解单个神经元有可能会产生相同的结果,但用上更多的神经元的方法似乎更有效。
此外,将视觉系统视为整个系统而不是孤立的区域,可以帮助我们更好地理解视觉系统。已经有大量的工作研究V4,例如试图用文字或简单的数学来描述导致该区域的细胞作出反应的原因。当V4被视为物体识别路径上的中间一部分时,它就不应该孤立地被描述和解释。从这个评论:“对一个单元的解释,例如,作为一个眼睛或面部检测器,可能有助于我们直观的理解和捕捉重要的东西。然而,这样的解释可能夸大了分类和本地化的程度,并且低估了这些表述的统计和分布性质。“事实上,对训练过的网络的分析表明,单个单位的可解释的调整与好的表现并不相关,而历史上很多人被误导了。
探索不同的架构会有更多的具体进展。通过查看捕获哪些元素的神经和行为响应需要哪些细节,我们可以在结构和功能之间建立直接联系。在这项研究中,加入网络的横向连接更有助于解释背侧流响应的时间过程,而不是腹侧流的时间过程。其他研究表明,反馈连接对于捕获腹侧流动力学非常重要。神经反应的某些组成部分可以在具有随机权重的模型中被捕获,这表明单独的分层体系结构可以解释它们。而其他组件则需要对自然和有效的图像类别进行训练。
此外,观察某些性能良好的CNN(参见Q11)不能准确预测神经活动,因为它表明并非所有做视觉的模型都是对大脑的好的建模。这证实了我们所看到的架构可以很好地预测神经活动(脑区和层之间的对应关系),因为它们确实捕获了大脑所做的转换。
因为CNN提供了“计算图像”的方法来生成真实的神经元反应,它们也可以关联较少的信号与视觉处理。
使用CNN作为视觉系统的模型,作者的工作【36】集中在证明特征相似性增益模型(描述注意力机制对神经元的影响)可以解释注意力的有益表现效应。
最后,一些研究记录了CNNs未捕捉到的神经或行为元素(见Q6)。这些有助于确定需要进一步实验和计算探索的领域。
总而言之,我会说不是一个不错的数字,因为从2014年左右开始,这其中的大部分事情才真正开始。
https://twitter.com/dlevenstein/status/994716148578037760
https://neuroecology.wordpress.com/2018/05/12/what-hasnt-deep-learning-replicated-from-the-brain/
https://www.frontiersin.org/articles/10.3389/fncom.2016.00094/full
https://arxiv.org/abs/1502.01852
https://www.annualreviews.org/doi/10.1146/annurev-vision-082114-035447
http://www.cse.chalmers.se/~coquand/AUTOMATA/mcp.pdf
http://fourier.eng.hmc.edu/e180/lectures/v1/node7.html
https://www.rctn.org/bruno/public/papers/Fukushima1980.pdf
https://www.cs.toronto.edu/~hinton/absps/NatureDeepReview.pdf
https://ieeexplore.ieee.org/document/6795724/
https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
https://www.mitpressjournals.org/doi/abs/10.1162/neco_a_00990
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4060707/
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2605405/
https://arxiv.org/pdf/1609.03529.pdf
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4222664/
http://cbcl.mit.edu/people/poggio/poggio-new.htm
http://serre-lab.clps.brown.edu/
http://maxlab.neuro.georgetown.edu/index.html
http://dicarlolab.mit.edu/
http://www.pnas.org/content/104/15/6424.long
https://distill.pub/2017/feature-visualization/
https://www.cell.com/neuron/fulltext/S0896-6273(12)00092-X
http://dicarlolab.mit.edu/sites/dicarlolab.mit.edu/files/pubs/dicarlo%20and%20cox%202007.pdf
http://maxlab.neuro.georgetown.edu/hmax.html
https://www.ncbi.nlm.nih.gov/pubmed/25611511
https://arxiv.org/pdf/1608.06993.pdf
http://papers.nips.cc/paper/5276-deep-networks-with-internal-selective-attention-through-feedback-connections.pdf
http://proceedings.mlr.press/v37/xuc15.pdf
https://arxiv.org/pdf/1804.08150.pdf
https://www.cv-foundation.org/openaccess/content_cvpr_2015/app/2B_004.pdf
http://vislab.isr.ist.utl.pt/wp-content/uploads/2017/11/aalmeida-robot2017.pdf
http://yann.lecun.com/exdb/publis/pdf/boureau-icml-10.pdf
https://www.cell.com/neuron/fulltext/S0896-6273(11)00876-2
https://www2.securecms.com/CCNeuro/docs-0/5928796768ed3f664d8a2560.pdf
https://www.biorxiv.org/content/biorxiv/early/2017/12/20/233338.full.pdf
原文链接:
https://neurdiness.wordpress.com/2018/05/17/deep-convolutional-neural-networks-as-models-of-the-visual-system-qa/
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



