数据少,就享受不到深度学习的红利了么?总是有办法的!
【导读】深度学习,有太多令人惊叹的能力!从12年的图像识别开始,深度学习的一个个突破,让人们一次又一次的刷新对它的认知。然而,应用深度学习,一直有一个巨大的前提:大量标注数据。但是难道数据少,就享受不到深度学习带来的红利了么?近日来自卡内基梅隆大学、亚马逊研究院、加州理工学院的研究员,在人工智能顶级会议 UAI 上阐述了多种方法,尝试缓解甚至解决数据稀疏对深度学习的影响。
作者 | Anima Anandkumar & Zachary Lipton
编译 | 专知
整理 | huaiwen
作者简介
【Zachary Lipton】博士 毕业于 加州大学圣迭戈分校人工智能组,现已加入卡内基梅隆大学任助理教授。他的研究兴趣比较广泛,主要包括:增强学习在对话系统中的应用、GAN、NLP 的深度主动学习、噪声单标签数据学习等。文章多见于ICML, ICLR, NIPS。个人主页:http://zacklipton.com/
【Anima Anandkumar】是加州理工学院的教授,她的研究方向是大型机器学习、非凸优化和高维统计。特别是,她一直引领和发展用于机器学习的张量算法,张量是矩阵的多维扩展,可以在数据中编码高阶关系。为亚马逊网络服务公司(Amazon Web Services),构建人工智能服务。参与构建了 Spectral LDA on Spark, MXNet, Gluon 等大型机器学习框架。个人主页:http://tensorlab.cms.caltech.edu/users/anima/
主要方法

为了解决深度学习数据少,和数据稀疏, 目前业界的主流方法有一下5种:
数据增广
半监督学习
迁移学习
领域自适应
主动学习
下面,我们对这5种方式进行一个简单的介绍,详细的介绍,可以在本文末尾,根据指示,获取原文观看。
数据增广

数据增广,主要是想,对现有的数据,添加噪声等各种其他变换,从而产生一些有意义的数据,是的数据集增加,从而解决数据稀疏的问题,提升模型性能。 特别的,如图所示,Zachary Lipton 介绍了近期他的一个工作:利用 GAN来做图像数据增广。
半监督学习

半监督学习的情形是指:我们拥有少量的标注样本(图中橘色部分)以及大量的未标注样本(图中蓝色部分)。
半监督学习,一般的思路是:在全部数据上去学习数据表示,在有标签的样本上去学习模型,用所有数据去加正则。
迁移学习
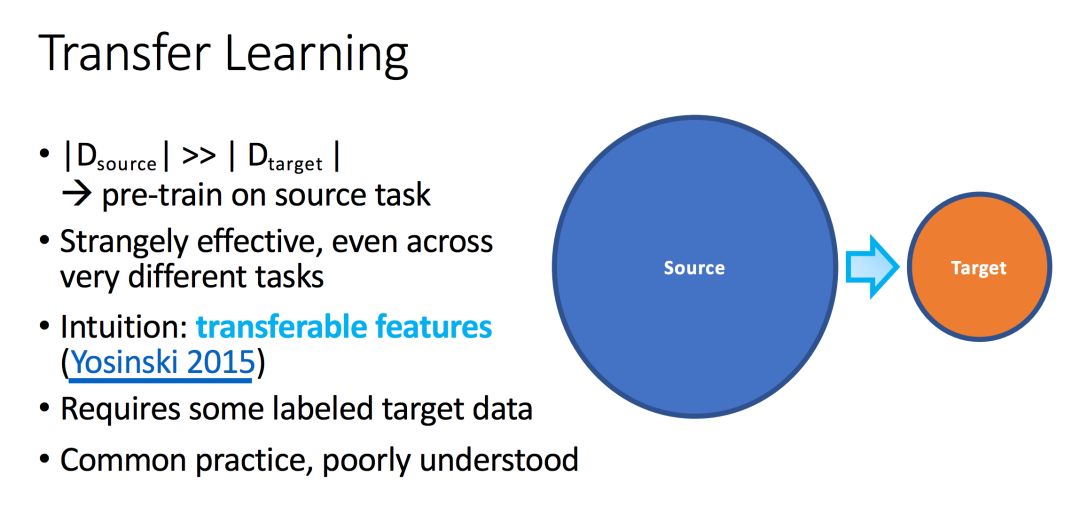
迁移学习,主要是想,在一个拥有大量样本的数据(图中蓝色部分)上去学习模型,在改动较少的情况下,将学习到的模型迁移到类似的目标数据(图中橘色部分)和任务上。
领域自适应

领域自适应,主要是想,在已有的标注数据p(x,y)上学习模型, 然后尝试在另一个分布上q(x,y)上去做应用。
主动学习
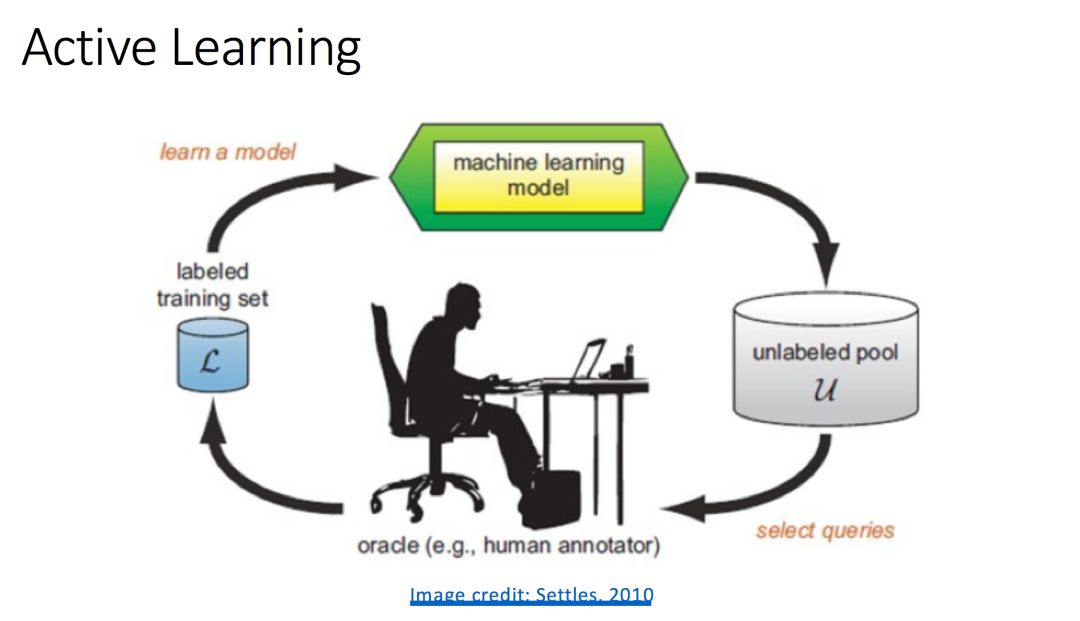
主动学习,维护了两个部分:学习引擎和选择引擎。学习引擎维护一个基准分类器,并使用监督学习算法对系统提供的已标注样例进行学习从而使该分类器的性能提高,而选择引擎负责运行样例选择算法选择一个未标注的样例并将其交由人类专家进行标注,再将标注后的样例加入到已标注样例集中。学习引擎和选择引擎交替工作,经过多次循环,基准分类器的性能逐渐提高,当满足预设条件时,过程终止。
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“UAI” 就可以获取“深度学习数据稀疏解决方案”的PPT 下载链接~
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

AI 项目技术 & 商务合作:bd@zhuanzhi.ai, 或扫描上面二维码联系!
请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



