【伯克利博士论文】如何让机器人多技能?通过最大熵强化学习(107页pdf)
【导读】作者Tuomas Haarnoja是伯克利人工智能研究实验室(BAIR)的博士生,由Pieter Abbeel和Sergey Levine指导,他研究兴趣是建立对深度强化学习算法更好的理解,并开发新的解决方案,以启发现实机器人应用,需要良好的样本复杂性和安全的探索。他最出名的工作是最大熵强化学习,它为学习样本高效可靠的随机策略提供了一个理论基础框架,并将其应用于机器人操纵和运动。

作者主页:
https://people.eecs.berkeley.edu/~haarnoja/
他的毕业博士论文使用最大熵强化学习使机器人具备多样技能《Acquiring Diverse Robot Skills via Maximum Entropy Deep Reinforcement Learning》,是最大熵强化学习在机器人应用方面的综述性文章,非常值得参阅。


Pieter Abbeel也做了重点推荐和祝贺!

博士论文下载:
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“MEDRL” 就可以获取笔记博士论文下载链接~
博士论文《Acquiring Diverse Robot Skills via Maximum Entropy Deep Reinforcement Learning》

论文题目:
Acquiring Diverse Robot Skills via Maximum Entropy Deep Reinforcement Learning
作者:
Tuomas Haarnoja
导师:Pieter Abbeel and Sergey Levine
网址:
https://www2.eecs.berkeley.edu/Pubs/TechRpts/2018/EECS-2018-176.html
论文摘要:
在本文中,我们研究了最大熵框架如何提供有效的深度强化学习(deep reinforcement learning, deep RL)算法,以连贯性地解决任务并有效地进行样本抽取。这个框架有几个有趣的特性。首先,最优策略是随机的,改进了搜索,防止了收敛到局部最优,特别是当目标是多模态的时候。其次,熵项提供了正则化,与确定性方法相比,具有更强的一致性和鲁棒性。第三,最大熵策略是可组合的,即可以组合两个或两个以上的策略,并且所得到的策略对于组成任务奖励的总和是近似最优的。第四,最大熵RL作为概率推理的观点为构建能够解决复杂和稀疏奖励任务的分层策略提供了基础。在第一部分中,我们将在此基础上设计新的算法框架,从soft Q学习的学习表现力好的能量策略、对于 sodt actor-critic提供简单和方便的方法,到温度自动调整策略, 几乎不需要hyperparameter调优,这是最重要的一个实际应用的调优hyperparameters可以非常昂贵。在第二部分中,我们将讨论由最大熵策略固有的随机特性所支持的扩展,包括组合性和层次学习。我们将演示所提出的算法在模拟和现实机器人操作和移动任务中的有效性。
论文结构:


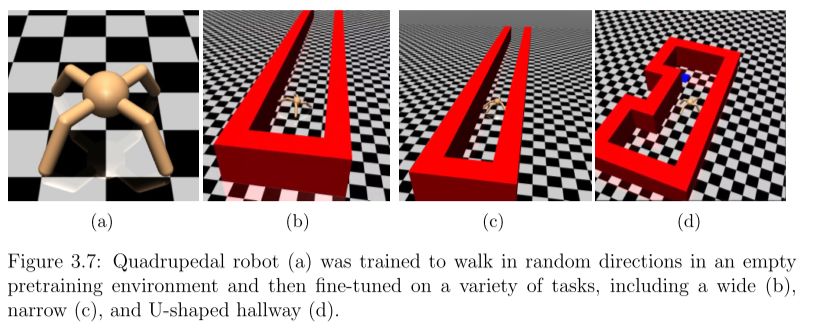
模拟四足机器人在多种环境中行走:
机械臂拼乐高

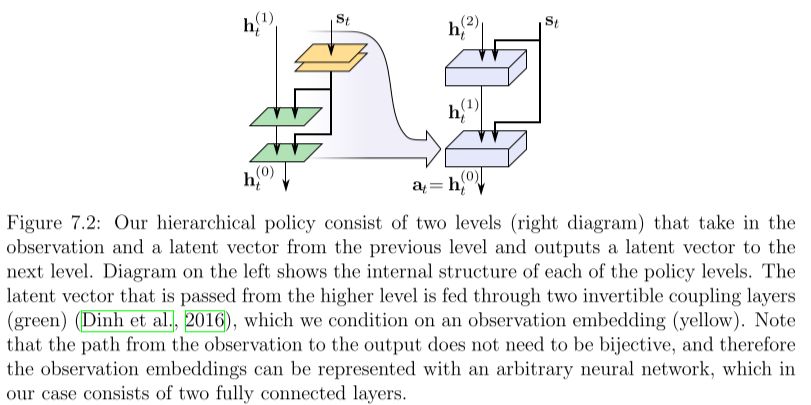
层次最大熵强化学习模型
-END-
专 · 知
专知开课啦!《深度学习: 算法到实战》, 中科院博士为你讲授!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群, 咨询《深度学习:算法到实战》等~

欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



