【计算机视觉近一年进展综述】《A Year in Computer Vision》by The M Tank
点击上方“专知”关注获取专业AI知识!

【导读】计算机视觉近一年进展综述,本报告仅仅是为了简要的总结下2016近一年在计算机领域的一些重要进展。第一部分:分割/定位,目标检测,目标追踪。第二部分:分割,超分辨率/自动上色,风格迁移,动作识别。第三部分:3D世界理解。第四部分:卷积网络结构,数据集,新兴应用,专知内容组特定整理出来,大家可以查看,基本上把近一年的视觉领域各方面的进展都提及了,内容很全面。

▌引言:
计算机视觉通常是指能赋予机器某种视觉洞察力的研究,比如让机器能够分辨各类颜色,让机器可视化地分析它们周围的环境或者刺激。这个过程通常涉及图像,图像集或视频的处理。英国机器视觉协会(BMVA)将计算机视觉定义为“自动提取,分析和理解来自单个图像或一系列图像集的有用信息。
这个定义中的“理解”特别强调了与机械式的视觉定义的区别,同时也说明了计算机视觉问题的重要性和复制性。但是单纯的视觉表示并不能让我们真正的理解周围的环境。对我们环境的认知不仅仅是通过视觉表示获得的。视觉信号通过视神经元到达主视觉皮层随后再被大脑所解释。 这个被大脑解释的过程来自我们身体自身构造机制和主观经验的感官信息,比如:进化如何使我们生存,以及在我们生活中对整个世界有哪些认知。
在这方面,视觉只涉及为了解释需要的图像传输; 而图像的计算更类似于某种思想或认知,而且会设计多个大脑区域的协作。因此,很多人认为计算机视觉是对视觉环境及其背景的真实了解,由于其具有跨领理解的优势,可以为未来强大的人工智能开拓出新的道路。
所以总得来说我们还是处于这个诱人领域的初始阶段。本报告仅仅是为了简要的总结下2016年在计算机领域的一些重要进展。
尽管我们用尽可能容易理解的方式来写作,但是由于一些领域的特点还是会有一部分读起来可能比较晦涩。我们在整个过程中都提供了基本的定义,但是这些只能作为相关重要的概念的简单理解。 为了将我们的重点放在2016年的工作上,为了简洁起见,经常忽略一些信息。
一个明显的省略涉及卷积神经网络的功能(以下简称CNN或ConvNets),因为它在计算机视觉领域中无处不在。AlexNet是在2012年ImageNet竞赛上提出来基于CNN的结构,它的成功给计算机视觉领域打了一针强心剂,众多的研究人员采用类似的基于神经网络的方法作开始了计算机视觉的新时期。
四年多之后,CNN变体仍然构成了视觉任务新的神经网络架构主要部分,研究人员将它们重新构建成像乐谱一样; 这是对开源信息和深度学习力量的有效证明。然而,对CNN的解释可以很容易地翻阅几个帖子,最好关注那些在这个问题上的资深专家,因为他们的解释使复杂的东西理解起来更容易。
对于那些希望在继续进行之前快速了解的一般读者,推荐下面的前两个资源。 对于那些还想做进一步研究,我们已经整理了下面的资源:
深度神经网络是如何看待你的自拍。Andrej Karpathy 是帮助人们理解产品和应用背后的CNN技术。
Quora问题“什么是卷积神经网络?” - 特别适合那些入门用户
CS231n:斯坦福大学的基于卷积神经网络的计算机视觉课程是一个更有深度的优秀资源。
《Deep Learning》深度学习(Goodfellow,Bengio&Courville,2016)在第9章对CNN特征和功能的解释提供了详细的信息。教科书被作者以HTML格式免费提供。
对于那些希望更多地了解神经网络和深度学习的人一般我们建议:
神经网络和深度学习(Nielsen,2017)是一个免费的在线教科书这为读者提供了对神经网络与深度学习复杂性的直观理解。 即使只是完成第一章应该很大程度上说明了这本书的主题。
总的来说,这篇文章是分裂的,可能也反应了作者想一章一章对任务解释的兴奋之情。
我们希望读者能够从这里收集的信息中受益,无论以往的经验如何,都可以进一步提高自己的知识水平。
来自我们所有的贡献者
主要是分这几部分
第一部分:分割/定位,目标检测,目标追踪
第二部分:分割,超分辨率/自动上色,风格迁移,动作识别
第三部分:3D世界理解
第四部分:卷积网络结构,数据集,新兴应用
Part One: Classification/Localisation, Object Detection, Object Tracking
▌Classification/Localisation
The task of classification, when it relates to images, generally refers to assigning a label to the whole image, e.g. ‘cat’. Assuming this, Localisation may then refer to finding where the object is in said image, usually denoted by the output of some form of bounding box around the object. Current classification/localisation techniques on ImageNet have likely surpassed an ensemble of trained humans. For this reason, we 9 10 place greater emphasis on subsequent sections of the blog
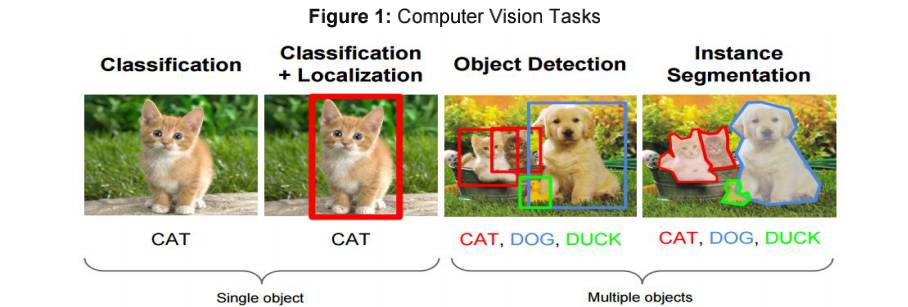
Source: Fei-Fei Li, Andrej Karpathy & Justin Johnson (2016) cs231n, Lecture 8 - Slide 8, Spatial Localization and Detection (01/02/2016). Available:
http://cs231n.stanford.edu/slides/2016/winter1516_lecture8.pdf
However, the introduction of larger datasets with an increased number of classes will likely provide new metrics for progress in the near future. On that point, François Chollet, the creator of Keras, has applied new techniques, including the popular architecture Xception, to an internal google dataset with over 350 million multi-label images containing 17,000 classes.
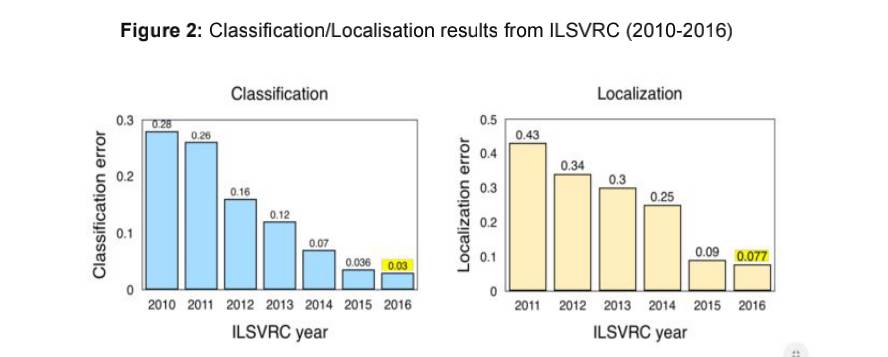
Note: ImageNet Large Scale Visual Recognition Challenge (ILSVRC). The change in results from 2011-2012 resulting from the AlexNet submission. For a review of the challenge requirements relating to Classification and Localization see: http://www.image-net.org/challenges/LSVRC/2016/index#comp
Source: Jia Deng (2016). ILSVRC2016 object localisation: introduction, results. Slide 2. Available:http://image-net.org/challenges/talks/2016/ILSVRC2016_10_09_clsloc.pdf
Interesting takeaways from the ImageNet LSVRC(2016):
● Scene Classification refers to the task of labelling an image with a certain scene class like ‘greenhouse’, ‘stadium’, ‘cathedral’,etc. ImageNet held a Scene Classification challenge last year with a subset of the Places2^15 dataset: 8 million images for training with 365 scene categories.
Hikvision won with a 9% top-5 error with an ensemble of deep Inception-style networks, and not-so-deep residuals networks.
●Trimps-Soushen won the ImageNet Classification task with 2.99% top-5 classification error and 7.71% localisation error. The team employed an ensemble for classification (averaging the results of Inception, Inception-Resnet,ResNet and Wide Residual Networks models ) and Faster R-CNN for localisation based on the labels. The dataset was distributed across 1000 image classes with 1.2 million images provided as training data. The partitioned test data compiled a further 100 thousand unseen images ResNeXt by Facebook came a close second in top-5 classification error with 3.03% by using a new architecture that extends the original ResNet architecture.
▌Object Detection
As one can imagine the process of Object Detection does exactly that, detects objects within images. The definition provided for object detection by the ILSVRC 201620 includes outputting bounding boxes and labels for individual objects. This differs from the classification/localisation task by applying classification and localisation to many objects instead of just a single dominant object.

Note: Picture is an example of face detection, Object Detection of a single class. The authors cite one of the persistent issues in Object Detection to be the detection of small objects. Using small faces as a test class they explore the role of scale invariance, image resolution, and contextual reasoning.
Source: Hu and Ramanan (2016, p. 1)
One of 2016’s major trends in Object Detection was the shift towards a quicker, more efficient detection system. This was visible in approaches like YOLO, SSD and R-FCN as a move towards sharing computation on a whole image. Hence, differentiating themselves from the costly subnetworks associated with Fast/Faster R-CNN techniques. This is typically referred to as ‘end-to-end training/learning’ and features throughout this piece.
The rationale generally is to avoid having separate algorithms focus on their respective subproblems in isolation as this typically increases training time and can lower network accuracy. That being said this end-to-end adaptation of networks typically takes place after initial sub-network solutions and, as such, is a retrospective optimisation. However,Fast/Faster R-CNN techniques remain highly effective and are still used extensively for object detection.
● SSD: Single Shot MultiBox Detector utilises a single Neural Network which encapsulates all the necessary computation and eliminates the costly proposal generation of other methods. It achieves “75.1% mAP, outperforming a comparable state of the art Faster R-CNN model” (Liu et al. 2016).
● One of the most impressive systems we saw in 2016 was from the aptly named“YOLO9000: Better, Faster, Stronger” , which introduces the YOLOv2 and YOLO9000 detection systems. YOLOv2 vastly improves the initial YOLO model from mid-2015, and is able to achieve better results at very high FPS (up to 90 FPS on low resolution images using the original GTX Titan X). In addition tocompletion speed, the system outperforms Faster RCNN with ResNet and SSD on certain object detection datasets.
YOLO9000 implements a joint training method for detection and classification extending its prediction capabilities beyond the labelled detection data available i.e. it is able to detect objects that it has never seen labelled detection data for.The YOLO9000 model provides real-time object detection across 9000+ categories, closing the dataset size gap between classification and detection.Additional details, pre-trained models and a video showing it in action is available here.
● Feature Pyramid Networks for Object Detection comes from FAIR and
capitalises on the “inherent multi-scale, pyramidal hierarchy of deep
convolutional networks to construct feature pyramids with marginal extra cost”,meaning that representations remain powerful without compromising speed or memory. Lin et al. (2016) achieve state-of-the-art (hereafter SOTA) single-model results on COCO . Beating the results achieved by winners in 2016 when combined with a basic Faster R-CNN system.
● R-FCN: Object Detection via Region-based Fully Convolutional Networks:
This is another method that avoids applying a costly per-region subnetwork
hundreds of times over an image by making the region-based detector fully
convolutional and sharing computation on the whole image. “Our result is
achieved at a test-time speed of 170ms per image, 2.5-20x faster than the Faster R-CNN counterpart” (Dai et al., 2016)
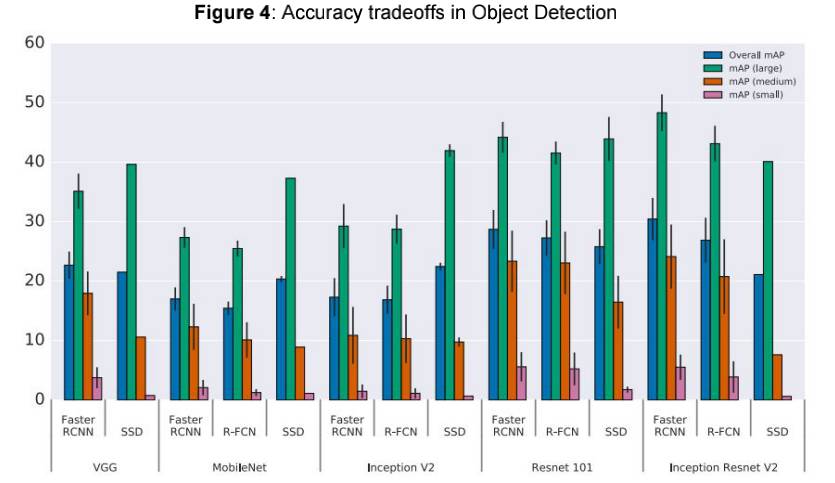
Note: Y-axis displays mAP (mean Average Precision) and the X-axis displays meta-architecture variability across each feature extractor (VGG, MobileNet...Inception ResNet V2). Additionally, mAP small, medium and large describe the average precision for small, medium and large objects, respectively. As such accuracy is “stratified by object size, meta-architecture and feature extractor” and “image resolution is fixed to 300”. While Faster R-CNN performs comparatively well in the above sample, it is worth noting that the meta-architecture is considerably slower than more recent approaches, such as R-FCN.
Source: Huang et al. (2016, p. 9)
Huang et al. (2016) present a paper which provides an in depth performance comparison between R-FCN, SSD and Faster R-CNN. Due to the issues around accurate comparison of Machine Learning (ML) techniques we’d like to point to the merits of producing a standardised approach here. They view these architectures as‘meta-architectures’ since they can be combined with different kinds of feature extractors such as ResNet or Inception.
The authors study the trade-off between accuracy and speed by varying meta-architecture, feature extractor and image resolution. The choice of feature extractor for example produces large variations between meta-architectures.
The trend of making object detection cheap and efficient while still retaining the accuracy required for real-time commercial applications, notably in autonomous driving applications, is also demonstrated by SqueezeDet and PVANet papers. While a Chinese company, DeepGlint, provides a good example of object detection in operation as a CCTV integration, albeit in a vaguely Orwellian manner: Video.
Results from ILSVRC and COCO Detection Challenge
COCO (Common Objects in Context) is another popular image dataset. However, it is comparatively smaller and more curated than alternatives like ImageNet, with a focus on object recognition within the broader context of scene understanding. The organizers host a yearly challenge for Object Detection, segmentation and keypoints. Detection results from both the ILSVRC and the COCO Detection Challenge are;
● ImageNet LSVRC Object Detection from Images (DET): CUImage 66%
meanAP. Won 109 out of 200 object categories.
● ImageNet LSVRC Object Detection from video (VID): NUIST 80.8% mean AP
● ImageNet LSVRC Object Detection from video with tracking: CUvideo 55.8%
mean AP
● COCO 2016 Detection Challenge (bounding boxes): G-RMI (Google) 41.5%
AP (4.2% absolute percentage increase from 2015 winner MSRAVC)
In review of the detection results for 2016, ImageNet stated that the ‘MSRAVC 2015 set a very high bar for performance [introduction of ResNets to competition]. Performance on all classes has improved across entries. Localization improved greatly in both challenges. High relative improvement on small object instances’ (ImageNet, 2016)
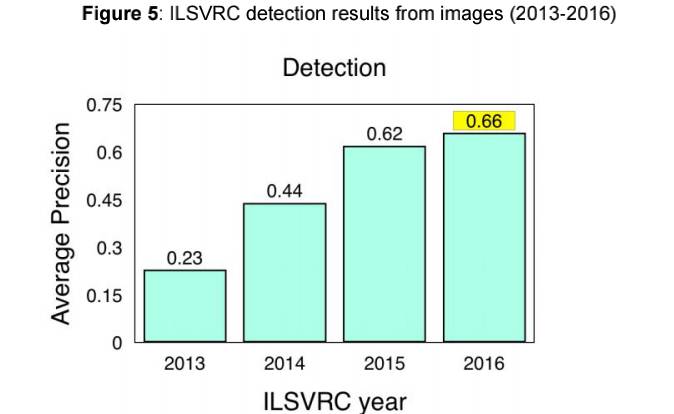
Note: ILSVRC Object Detection results from images (DET) (2013-2016).
Source: ImageNet. 2016. [Online] Workshop Presentation, Slide 2. Available:
http://image-net.org/challenges/talks/2016/ECCV2016_ilsvrc_coco_detection_segmentation.pdf
由于英文内容太多,大家可以下载对应的文章,文末有下载链接。
参考文献:
http://www.themtank.org/a-year-in-computer-vision
特别提示-报告下载:
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“CV2017” 就可以获取报告的pdf下载链接~
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃集合】人工智能领域主题知识资料全集[ 持续更新中](入门/进阶/论文/综述/视频/专家等,附查看)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!
请关注我们的公众号,获取人工智能的专业知识。扫一扫关注我们的微信公众号。

请扫描专知小助手,加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等,或者加小助手咨询入群)交流~


点击“阅读原文”,使用专知!
展开全文



