Nature机器智能子刊3月新论文《强化学习在人工生物系统中的应用》
【导读】Nature 机器智能(Machine Intelligence子刊)最新3月刊登了美国国家精神卫生研究所神经心理学实验室的科研工作者关于强化学习在人工及生物系统中应用的论文,详细描述了描述了强化学习在生物和人工智能体方面的最新研究进展。

论文链接:https://www.nature.com/articles/s42256-019-0025-4
论文内容
摘要:在生物系统和人工系统的学习研究之间,一直存在着大量富有成果的概念和思想。为人工系统开发强化学习(RL)算法的许多早期工作,都受到了Bush和Mosteller、Rescorla和Wagner在生物学中首次开发的学习规则的启发。最近,人工智能中用于学习的时间差分RL为解释多巴胺神经元的活动提供了一个基础框架。在这篇综述中,我们描述了RL在生物和人工智能体方面的最新研究进展。我们关注这些学科之间的接触点,并确定未来的研究可以从这些领域之间的信息流中受益的领域。生物系统中的大多数工作都集中在简单的学习问题上,这些问题通常嵌入动态环境中,其中灵活性和在线学习非常重要,类似于生物系统所面临的实际学习问题。相比之下,人工智能领域的大多数工作都专注于在静态环境中学习单个复杂问题。更进一步,每个领域的工作都将受益于代表每个学科优势的思想。
生物及人工智能体必须达到生存和有用的目标。这种目标导向也是强化学习(RL)的基础。
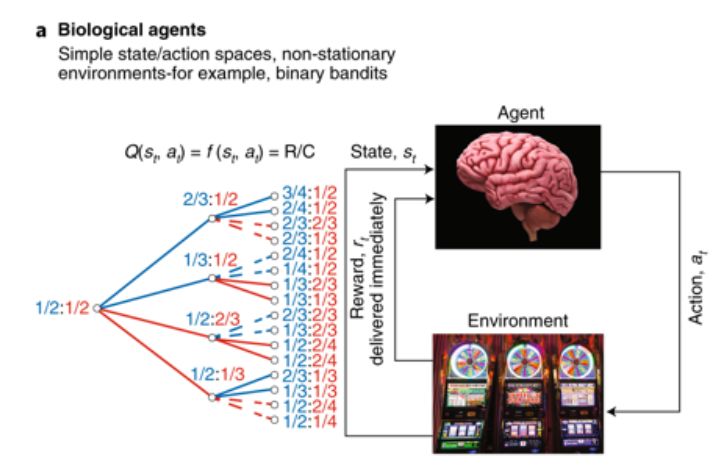
A. RL是基于一个代理与其环境之间的交互。代理选择动作(at)导致状态(st)更改和环境返回的奖励(rt)。代理的目标是在规定的时间范围内最大化回报。在生物学中用于研究RL的实验中,动作值Q(st, at)通常是选择和奖励频率的简单函数(即奖励的数量R除以强盗任务中少数选择的数量C)。
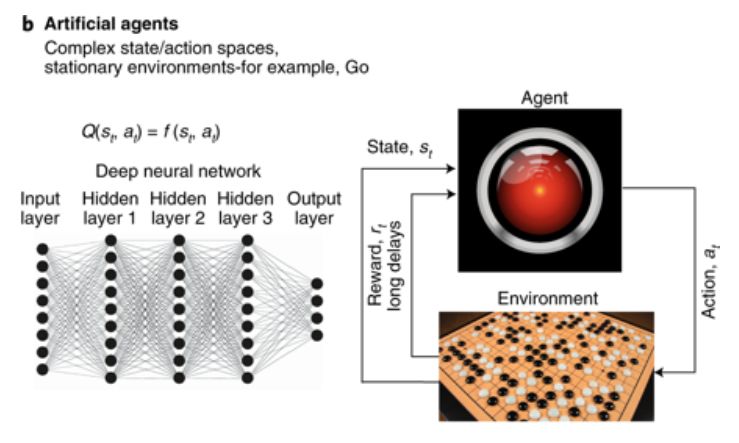
B. 同样的主体-环境的区别在人工系统中也很重要。在最先进的人工RL系统中,通过训练深度网络来估计动作值。它们通常是感官输入的复杂功能。
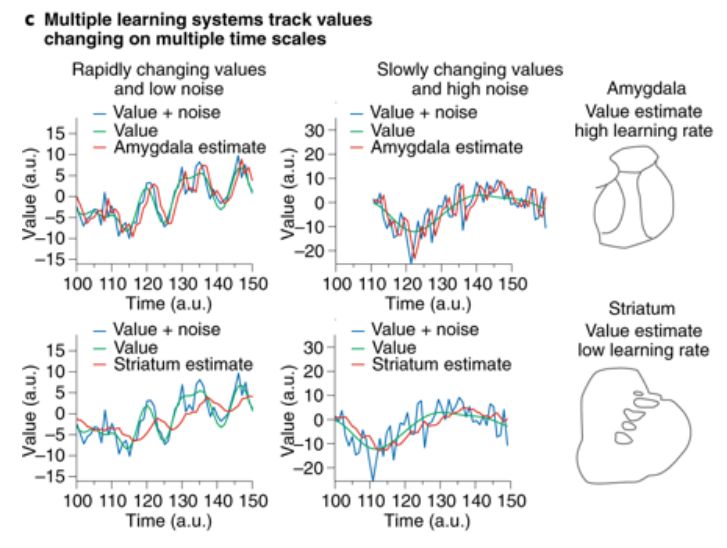
C. 生物智能体(例如大脑)使用多种学习系统,以不同的速度学习。杏仁核和纹状体是大脑中支持RL学习的两个核。杏仁核(也见图3)的学习速度很快,因此可以跟踪环境的快速变化,但代价是对噪音的敏感性。另一方面,纹状体的学习速度较慢。虽然它不能跟踪环境价值的快速变化,但它对噪音的抵抗力更强。
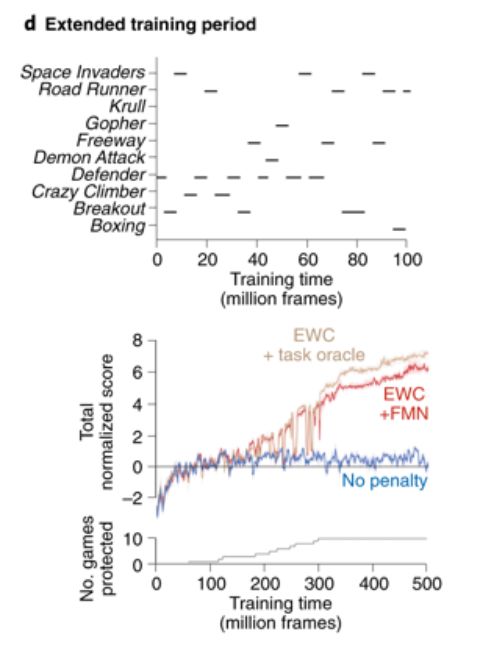
D. 人工智能通常针对复杂的、统计上稳定的问题进行训练。培训试验的数量是巨大的,因此这些系统不能迅速适应环境的变化。人工智能体通常只接受单一任务的训练,无法在连续的多任务设置中学习。分级RL、结构塑性和固结可以使人工智能体在多个时间尺度上学习。
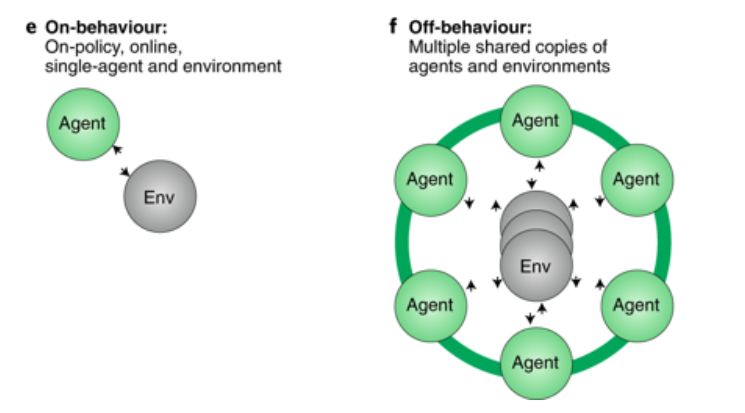
E. 生物智能体以一种“行为”的方式与环境互动,也就是说,学习是在线的,环境只有一个副本。
F. 虽然许多用于人工代理的RL方法都遵循这些原则,但是最近最成功的策略包括一种代理并行的形式,其中代理在环境的副本上学习达到稳定学习。海马体或更多互补学习系统激发的经验回放可以为行为主体提供必要的属性,从而形成人工和生物RL之间的接触点。
【论文下载】
请关注专知公众号(点击上方蓝色专知关注)
后台回复“RLB” 就可以获取最新论文《强化学习在人工生物系统中的应用》的下载链接~
-END-
专 · 知
专知《深度学习:算法到实战》课程全部完成!500+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询《深度学习:算法到实战》课程,咨询技术商务合作~

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



