【论文推荐】最新五篇度量学习相关论文—无标签、三维姿态估计、主动度量学习、深度度量学习、层次度量学习与匹配
【导读】专知内容组整理了最近五篇度量学习(Metric Learning )相关文章,为大家进行介绍,欢迎查看!
1.Mining on Manifolds: Metric Learning without Labels(对流形的挖掘:无标签的度量学习)
作者:Ahmet Iscen,Giorgos Tolias,Yannis Avrithis,Ondrej Chum
摘要:In this work we present a novel unsupervised framework for hard training example mining. The only input to the method is a collection of images relevant to the target application and a meaningful initial representation, provided e.g. by pre-trained CNN. Positive examples are distant points on a single manifold, while negative examples are nearby points on different manifolds. Both types of examples are revealed by disagreements between Euclidean and manifold similarities. The discovered examples can be used in training with any discriminative loss. The method is applied to unsupervised fine-tuning of pre-trained networks for fine-grained classification and particular object retrieval. Our models are on par or are outperforming prior models that are fully or partially supervised.

期刊:arXiv, 2018年3月29日
网址:
http://www.zhuanzhi.ai/document/25946ca9254d8330f059f75123fd100f
2.3D Pose Estimation and 3D Model Retrieval for Objects in the Wild(对自然场景下物体的三维姿态估计和三维模型检索)
作者:Alexander Grabner,Peter M. Roth,Vincent Lepetit
机构:University of Bordeaux
摘要:We propose a scalable, efficient and accurate approach to retrieve 3D models for objects in the wild. Our contribution is twofold. We first present a 3D pose estimation approach for object categories which significantly outperforms the state-of-the-art on Pascal3D+. Second, we use the estimated pose as a prior to retrieve 3D models which accurately represent the geometry of objects in RGB images. For this purpose, we render depth images from 3D models under our predicted pose and match learned image descriptors of RGB images against those of rendered depth images using a CNN-based multi-view metric learning approach. In this way, we are the first to report quantitative results for 3D model retrieval on Pascal3D+, where our method chooses the same models as human annotators for 50% of the validation images on average. In addition, we show that our method, which was trained purely on Pascal3D+, retrieves rich and accurate 3D models from ShapeNet given RGB images of objects in the wild.
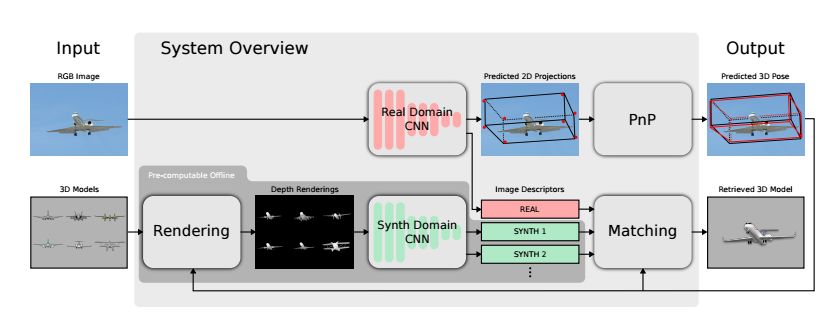
期刊:arXiv, 2018年3月30日
网址:
http://www.zhuanzhi.ai/document/9b1f4cdd2edfcaa33b7528dc7d1fa094
3.Active Metric Learning for Supervised Classification(基于主动度量学习的监督分类)
作者:Krishnan Kumaran,Dimitri Papageorgiou,Yutong Chang,Minhan Li,Martin Takáč
摘要:Clustering and classification critically rely on distance metrics that provide meaningful comparisons between data points. We present mixed-integer optimization approaches to find optimal distance metrics that generalize the Mahalanobis metric extensively studied in the literature. Additionally, we generalize and improve upon leading methods by removing reliance on pre-designated "target neighbors," "triplets," and "similarity pairs." Another salient feature of our method is its ability to enable active learning by recommending precise regions to sample after an optimal metric is computed to improve classification performance. This targeted acquisition can significantly reduce computational burden by ensuring training data completeness, representativeness, and economy. We demonstrate classification and computational performance of the algorithms through several simple and intuitive examples, followed by results on real image and medical datasets.
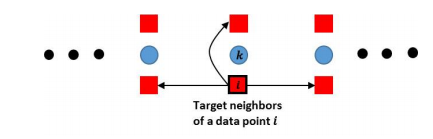
期刊:arXiv, 2018年3月28日
网址:
http://www.zhuanzhi.ai/document/9ba8b6a6fd182e5e787fe7ab69bd5705
4.Directional Statistics-based Deep Metric Learning for Image Classification and Retrieval(基于方向统计的深度度量学习的图像分类和检索)
作者:Xuefei Zhe,Shifeng Chen,Hong Yan
摘要:Deep distance metric learning (DDML), which is proposed to learn image similarity metrics in an end-to-end manner based on the convolution neural network, has achieved encouraging results in many computer vision tasks.$L2$-normalization in the embedding space has been used to improve the performance of several DDML methods. However, the commonly used Euclidean distance is no longer an accurate metric for $L2$-normalized embedding space, i.e., a hyper-sphere. Another challenge of current DDML methods is that their loss functions are usually based on rigid data formats, such as the triplet tuple. Thus, an extra process is needed to prepare data in specific formats. In addition, their losses are obtained from a limited number of samples, which leads to a lack of the global view of the embedding space. In this paper, we replace the Euclidean distance with the cosine similarity to better utilize the $L2$-normalization, which is able to attenuate the curse of dimensionality. More specifically, a novel loss function based on the von Mises-Fisher distribution is proposed to learn a compact hyper-spherical embedding space. Moreover, a new efficient learning algorithm is developed to better capture the global structure of the embedding space. Experiments for both classification and retrieval tasks on several standard datasets show that our method achieves state-of-the-art performance with a simpler training procedure. Furthermore, we demonstrate that, even with a small number of convolutional layers, our model can still obtain significantly better classification performance than the widely used softmax loss.
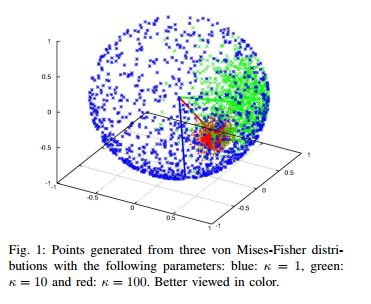
期刊:arXiv, 2018年3月28日
网址:
http://www.zhuanzhi.ai/document/4413c2a473c060dfbf2905ea4c4615d1
5.Hierarchical Metric Learning and Matching for 2D and 3D Geometric Correspondences(基于层次度量学习与匹配的二维和三维几何对应)
作者:Mohammed E. Fathy,Quoc-Huy Tran,M. Zeeshan Zia,Paul Vernaza,Manmohan Chandraker
机构:University of Maryland,University of California
摘要:Interest point descriptors have fueled progress on almost every problem in computer vision. Recent advances in deep neural networks have enabled task-specific learned descriptors that outperform hand-crafted descriptors on many problems. We demonstrate that commonly used metric learning approaches do not optimally leverage the feature hierarchies learned in a Convolutional Neural Network (CNN), especially when applied to the task of geometric feature matching. While a metric loss applied to the deepest layer of a CNN, is often expected to yield ideal features irrespective of the task, in fact the growing receptive field as well as striding effects cause shallower features to be better at high precision matching tasks. We leverage this insight together with explicit supervision at multiple levels of the feature hierarchy for better regularization, to learn more effective descriptors in the context of geometric matching tasks. Further, we propose to use activation maps at different layers of a CNN, as an effective and principled replacement for the multi-resolution image pyramids often used for matching tasks. We propose concrete CNN architectures employing these ideas, and evaluate them on multiple datasets for 2D and 3D geometric matching as well as optical flow, demonstrating state-of-the-art results and generalization across datasets.
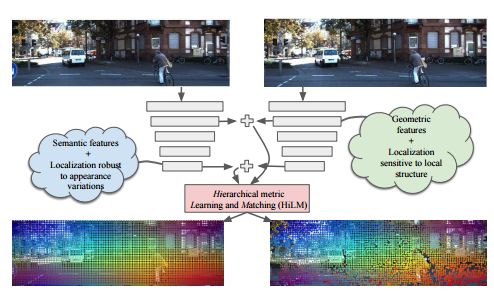
期刊:arXiv, 2018年3月27日
网址:
http://www.zhuanzhi.ai/document/54c5880b9c2b796588fcfda50029d483
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
点击“阅读原文”,使用专知!
展开全文



