一个实例读懂监督学习:Python监督学习实战
【导读】1月28日,Vihar Kurama和Sai Tejaswie撰写了一篇机器学习技术博文,为读者介绍了如何用python进行监督学习。作者首先解释什么是监督学习,并讲解了监督学习中的两个任务:分类和回归,并列举了其中的关键算法,如KNN,支持向量机以及线性回归、逻辑回归等。并使用scikit-learn实现一个KNN分类例子,辅助大家理解。在文末给出了文章中实例代码链接,感兴趣的读者不放自己跑一下。专知内容组编辑整理。
Supervised Learning with Python
python监督学习实战
▌为什么需要人工智能和机器学习呢?
地球的未来是人工智能/机器学习。不懂的人很快就会发现自己落后了。在这个充满创新的世界里,感觉生活越来越像魔术。有多种方法用人工智能和机器学习来解决现实问题,其中监督学习是最常用的方法之一。
人工智能的核心一直是表示(representation)——Jeff Hawkins
“The key to artificial intelligence has always been the representation.” — Jeff Hawkins
▌什么是有监督学习?
在监督学习中,我们从导入包含训练属性和标签的数据集开始。监督学习算法将学习训练样本与目标变量之间的关系,并应用所学的关系对新输入的数据进行分类(没有标签)。
为了说明监督学习是如何工作的,让我们来举个例子:根据学生的学习时间来预测学生成绩。
数学表达如下:
Y = f(X)+ C
在这里,
F将是学生考试的分数和时间的关系。
X是输入(他睡眠的小时数)。
Y是输出(学生在考试中得分)。
C是随机误差。
监督学习算法的最终目标是用给定的新输入X预测Y的最大精度。有几种方法可以实现监督学习;我们将探讨一些最常用的方法。
基于给定的数据集,机器学习问题分为两类:分类和回归。如果给定的数据同时具有输入(训练)值和输出(目标)值,那么它就是一个分类问题。如果数据集具有连续的属性数值,而没有任何标签信息,那么就是回归问题。
Classification: Has the output label. Is it a Cat or Dog?
Regression: How much will the house sell for?
▌分类:
医学研究人员的例子为例,他们希望分析乳腺癌的数据,来预测病人应该接受三种治疗方案中的哪一种。这个数据分析任务被称为分类,在这个分类任务中,构造的模型或分类器用来预测类别标签呢:例如“治疗a”、“治疗B”或“治疗c”。
分类是一种预测问题,它预测离散和无序的类标签。这个过程分为两步,包括学习步骤和分类步骤。
下面选出了最好的分类方法
一些最常用的分类算法:
1、k近邻算法
2、决策树
3、朴素贝叶斯
4、支持向量机
在学习步骤中,分类模型通过对训练集的分析,建立分类器。在分类步骤中,预测给定数据的类标签。将数据集及其类标签划分为训练集和测试集。构成训练集的单个元组或样本(tuples)是从数据集中随机抽取的。剩下的样本构成测试集,并且独立于训练元组,它们不会被用于构建分类器。
测试集用于估计分类器的预测精度。分类器的精度是被分类器正确分类的测试样本所占的百分比。为了达到更高的精度,最好的方法是测试不同的算法,并在每个算法中尝试不同的参数。最好的方法是利用交叉验证。
为了使算法更好,当针对不同的算法时,必须考虑精度、训练时间、线性关系(linearity)、参数个数和特殊情况等因素。
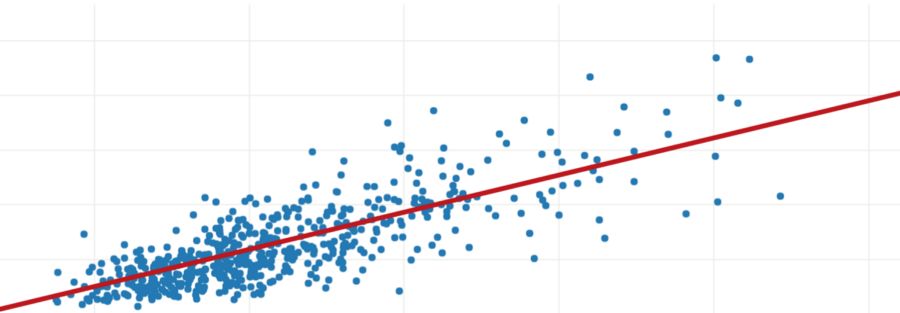
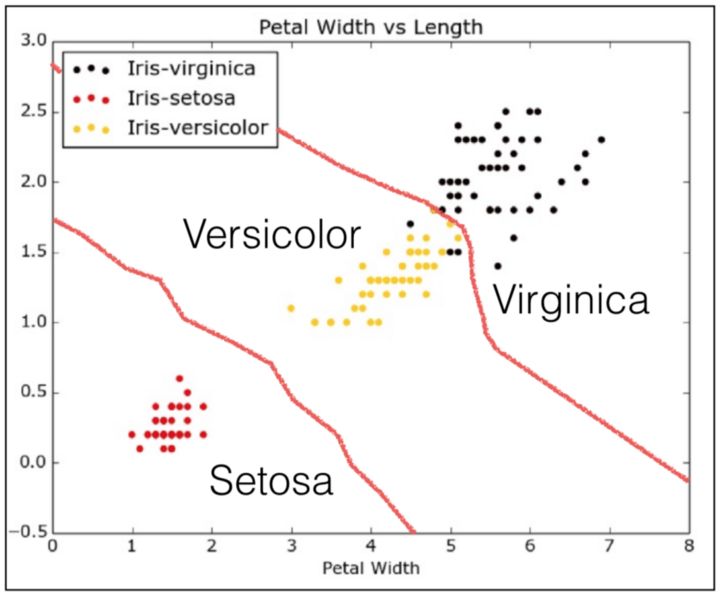
使用Scikit-Learn包的KNN算法并应用在IRIS数据集上,根据给定的输入对花的类型进行分类。
第一步,为了应用我们的机器学习算法,我们需要了解和探索给定的数据集。 在这个例子中,我们使用从scikit-learn包导入的IRIS数据集。 现在我们进入代码并探索IRIS数据集。
确保你的机器上安装了Python。 另外,使用PIP安装以下软件包
pip install pandas
pip install matplotlib
pip install scikit-learn
在下面这段代码中,我们使用pandas的几种方法了解了IRIS数据集的属性。
from sklearn import datasets
import pandas as pd
import matplotlib.pyplot as plt
# Loading IRIS dataset from scikit-learn object into iris variable.
iris = datasets.load_iris()
# Prints the type/type object of iris
print(type(iris))
# <class 'sklearn.datasets.base.Bunch'>
# prints the dictionary keys of iris data
print(iris.keys())
# prints the type/type object of given attributes
print(type(iris.data), type(iris.target))
# prints the no of rows and columns in the dataset
print(iris.data.shape)
# prints the target set of the data
print(iris.target_names)
# Load iris training dataset
X = iris.data
# Load iris target set
Y = iris.target
# Convert datasets' type into dataframe
df = pd.DataFrame(X, columns=iris.feature_names)
# Print the first five tuples of dataframe.
print(df.head())
输出:
<class ‘sklearn.datasets.base.Bunch’>
dict_keys([‘data’, ‘target’, ‘target_names’, ‘DESCR’, ‘feature_names’])]
<class ‘numpy.ndarray’> <class ‘numpy.ndarray’>
(150, 4)
[‘setosa’ ‘versicolor’ ‘virginica’]
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
▌在scikit-learn上应用KNN算法
如果一个算法只是简单地存储训练集样本并且一直等待给定测试集,那么这个算法就被认为是一个懒惰学习器。只有在它看到测试样本的时候,才会根据样本与存储的训练样本的相似性对样本进行分类。
k近邻分类器是一个懒惰的学习器。( lazy learner)
KNN是通过类比的方式来进行学习,即比较给定的测试元组与训练元组是否相似。训练元组由n个属性描述。 每个元组代表n维空间中的一个点。这样,所有训练元组都存储在n维空间中。当给定新的样本时,k近邻分类器在n维空间中搜索最接近未知元组的k个训练元组(样本)。这k个训练元组是新样本的k个“最近邻”点。
用距离(如欧式距离)的大小定义“亲密度”。 K的值是通过实验确定的。
在下面的代码中,我们从sklearn中导入KNN分类器,并将其应用到我们的输入数据,然后对花进行分类。
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
# Load iris dataset from sklearn
iris = datasets.load_iris()
# Declare an of the KNN classifier class with the value with neighbors.
knn = KNeighborsClassifier(n_neighbors=6)
# Fit the model with training data and target values
knn.fit(iris['data'], iris['target'])
# Provide data whose class labels are to be predicted
X = [
[5.9, 1.0, 5.1, 1.8],
[3.4, 2.0, 1.1, 4.8],
]
# Prints the data provided
print(X)
# Store predicted class labels of X
prediction = knn.predict(X)
# Prints the predicted class labels of X
print(prediction)
输出:
[1 1]
这里,
0对应于Versicolor
1对应Virginic
2对应Setosa
基于给定的输入,使用KNN预测的两个花是Versicolor。
KNN在IRIS数据集分类的可视化展示
▌回归(Regression)
回归通常被定义为确定两个或多个变量之间的关系。例如,你必须根据给定的输入数据X来预测一个人的收入。
在这里,目标变量是指我们需要预测的未知变量,而连续(continuous)的意思是说Y的值是不间断的。
预测收入是一个典型的回归问题。 您的输入数据应该包含所有可以预测收入的信息(称为特征),例如他的工作时间,教育经历,职位,他住的地方。
回归模型
一些常用的回归模型是:
线性回归
Logistic回归
多项式回归
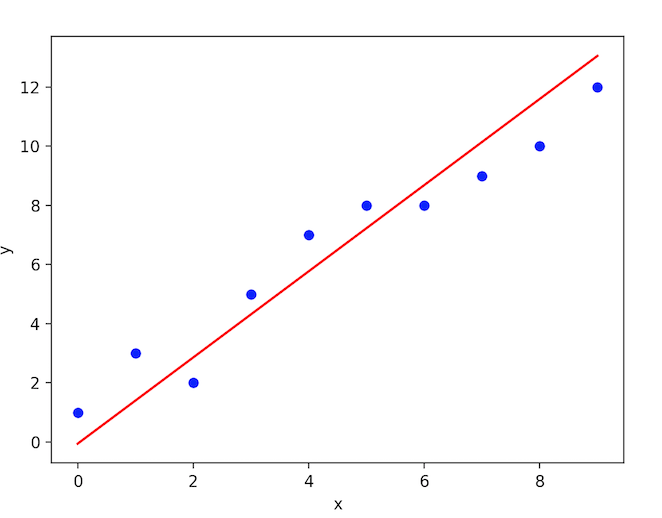
线性回归使用一条最佳的直线(也称为回归线)去拟合因变量(Y)和一个或多个自变量(X)之间的关系。
在数学上,
h(xi) = βo + β1 * xi + e
其中βo是截距,β1是线的斜率,e是误差项。
在图形上,
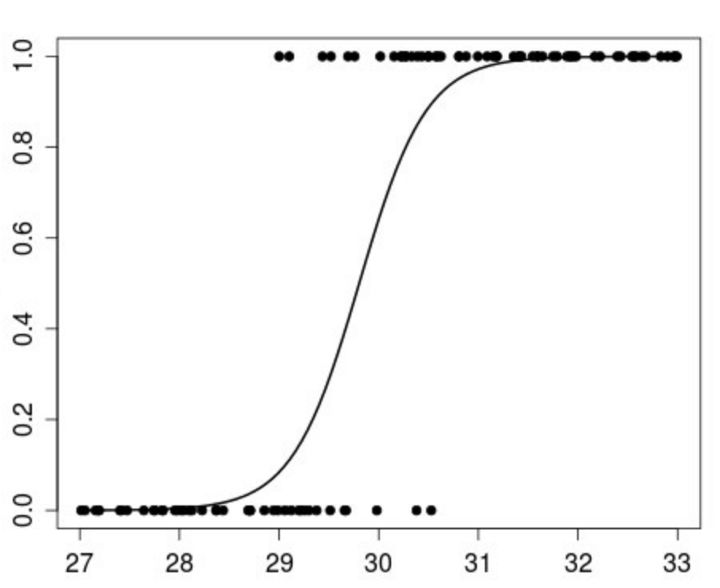
Logistic回归是一种衡量变量所属的类别的算法。Logistic回归的思想是找出特征与输出的概率之间的关系。
在数学上,
p(X) = βo + β1 * X
其中
p(x) = p(y = 1 | x)
在图形上,
多项式回归是一种回归分析形式,其中自变量x和因变量y之间的关系被建模为x的一个n次多项式。
线性回归问题求解
我们有数据集X和相应的目标值Y,并使用最小二乘法来学习一个线性模型,利用这个模型,对于给定一个之前没有出现的x,我们可以预测一个y,使误差尽可能小。
给定的数据被分成一个训练数据集和一个测试数据集。 训练集具有特征标签,所以算法可以从这些有标签的例子中学习。测试集没有任何标签,也就是说,你不知道预测的结果是什么。
我们将用一个特征来进行训练,并利用线性回归方法来拟合训练数据,然后使用测试数据集预测输出。
线性回归在scikit-learn中的实现
from sklearn import datasets, linear_model
import matplotlib.pyplot as plt
import numpy as np
# Load the diabetes dataset
diabetes = datasets.load_diabetes()
# Use only one feature for training
diabetes_X = diabetes.data[:, np.newaxis, 2]
# Split the data into training/testing sets
diabetes_X_train = diabetes_X[:-20]
diabetes_X_test = diabetes_X[-20:]
# Split the targets into training/testing sets
diabetes_y_train = diabetes.target[:-20]
diabetes_y_test = diabetes.target[-20:]
# Create linear regression object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(diabetes_X_train, diabetes_y_train)
# Input data
print('Input Values')
print(diabetes_X_test)
# Make predictions using the testing set
diabetes_y_pred = regr.predict(diabetes_X_test)
# Predicted Data
print("Predicted Output Values")
print(diabetes_y_pred)
# Plot outputs
plt.scatter(diabetes_X_test, diabetes_y_test, color='black')
plt.plot(diabetes_X_test, diabetes_y_pred, color='red', linewidth=1)
plt.show()
输出:
Input Values
[
[ 0.07786339] [-0.03961813] [ 0.01103904] [-0.04069594] [-0.03422907] [ 0.00564998] [ 0.08864151] [-0.03315126] [-0.05686312] [-0.03099563] [ 0.05522933] [-0.06009656]
[ 0.00133873] [-0.02345095] [-0.07410811] [ 0.01966154][-0.01590626] [-0.01590626] [ 0.03906215] [-0.0730303 ]
]
Predicted Output Values
[
225.9732401 115.74763374 163.27610621 114.73638965 120.80385422 158.21988574 236.08568105 121.81509832
99.56772822 123.83758651 204.73711411 96.53399594
154.17490936 130.91629517 83.3878227 171.36605897
137.99500384 137.99500384 189.56845268 84.3990668
]
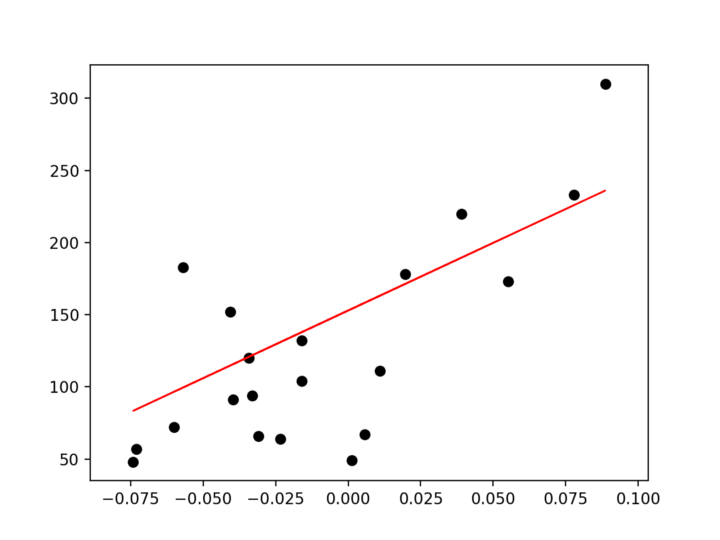
(diabetes_X_test, diabetes_y_pred)的图(测试数据与预测之间的图)在线性方程上将是连续的。
▌结束语
用于监督机器学习的其他Python包。
Scikit-Learn, Tensorflow, Pytorch.
▌重要链接
https://towardsdatascience.com/introduction-to-machine-learning-db7c668822c4
https://towardsdatascience.com/python-programming-in-15-min-part-1-3ad2d773834c
由Vihar Kurama和Sai Tejaswie撰写。
请继续关注机器学习的更多文章。
这篇文章的代码可以在这里找到:
https://github.com/vihar/supervised-learning-with-python
谢谢阅读。 如果你发现这篇文章有帮助,请点击并分享。
原文链接:
https://towardsdatascience.com/supervised-learning-with-python-cf2c1ae543c1
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知
展开全文



