【论文推荐】最新八篇情感分析相关论文—注意力网络、多模态情感分析、情感分析局限性、跨语言情感分类、多语言情感分析
【导读】专知内容组今天推出最新八篇情感分析(Sentiment Analysis)相关论文,欢迎查看!
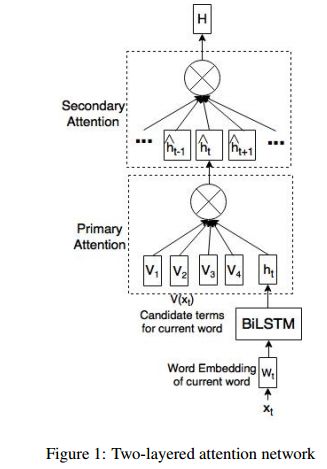
1.Knowledge-enriched Two-layered Attention Network for Sentiment Analysis(基于知识丰富两层注意力网络的情感分析)
作者:Abhishek Kumar,Daisuke Kawahara,Sadao Kurohashi
Accepted to NAACL 2018
机构:Kyoto University
摘要:We propose a novel two-layered attention network based on Bidirectional Long Short-Term Memory for sentiment analysis. The novel two-layered attention network takes advantage of the external knowledge bases to improve the sentiment prediction. It uses the Knowledge Graph Embedding generated using the WordNet. We build our model by combining the two-layered attention network with the supervised model based on Support Vector Regression using a Multilayer Perceptron network for sentiment analysis. We evaluate our model on the benchmark dataset of SemEval 2017 Task 5. Experimental results show that the proposed model surpasses the top system of SemEval 2017 Task 5. The model performs significantly better by improving the state-of-the-art system at SemEval 2017 Task 5 by 1.7 and 3.7 points for sub-tracks 1 and 2 respectively.
期刊:arXiv, 2018年5月25日
网址:
http://www.zhuanzhi.ai/document/ab6bb0e4ef59fe1139d11fff1308567c
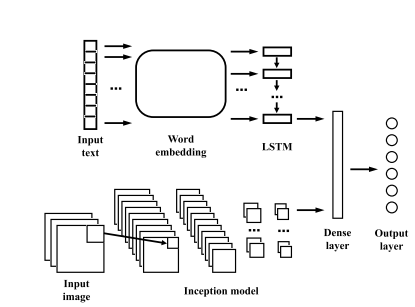
2.Multimodal Sentiment Analysis To Explore the Structure of Emotions(多模态情感分析探讨情感结构)
作者:Anthony Hu,Seth Flaxman
KDD 2018
机构:University of Oxford
摘要:We propose a novel approach to multimodal sentiment analysis using deep neural networks combining visual analysis and natural language processing. Our goal is different than the standard sentiment analysis goal of predicting whether a sentence expresses positive or negative sentiment; instead, we aim to infer the latent emotional state of the user. Thus, we focus on predicting the emotion word tags attached by users to their Tumblr posts, treating these as "self-reported emotions." We demonstrate that our multimodal model combining both text and image features outperforms separate models based solely on either images or text. Our model's results are interpretable, automatically yielding sensible word lists associated with emotions. We explore the structure of emotions implied by our model and compare it to what has been posited in the psychology literature, and validate our model on a set of images that have been used in psychology studies. Finally, our work also provides a useful tool for the growing academic study of images - both photographs and memes - on social networks.
期刊:arXiv, 2018年5月25日
网址:
http://www.zhuanzhi.ai/document/c60e1eb2a5bc56fb8ecba48d0afcb2ad
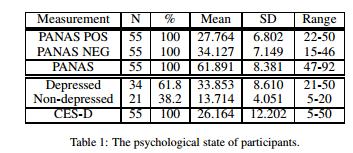
3.Psychological State in Text: A Limitation of Sentiment Analysis(Psychological State in Text:情感分析的局限性)
作者:Hwiyeol Jo,Jeong Ryu
IJCAI-ECAI
机构:Seoul National University,Seokyeong University
摘要:Starting with the idea that sentiment analysis models should be able to predict not only positive or negative but also other psychological states of a person, we implement a sentiment analysis model to investigate the relationship between the model and emotional state. We first examine psychological measurements of 64 participants and ask them to write a book report about a story. After that, we train our sentiment analysis model using crawled movie review data. We finally evaluate participants' writings, using the pretrained model as a concept of transfer learning. The result shows that sentiment analysis model performs good at predicting a score, but the score does not have any correlation with human's self-checked sentiment.
期刊:arXiv, 2018年6月3日
网址:
http://www.zhuanzhi.ai/document/9b98c849fc0ba016afa944a3fe25020d
4.What we really want to find by Sentiment Analysis: The Relationship between Computational Models and Psychological State(我们真正想通过情绪分析找到的是:计算模型与心理状态的关系)
作者:Hwiyeol Jo,Soo-Min Kim,Jeong Ryu
机构:Seoul National University,Chung-Ang University,Yonsei University
摘要:As the first step to model emotional state of a person, we build sentiment analysis models with existing deep neural network algorithms and compare the models with psychological measurements to enlighten the relationship. In the experiments, we first examined psychological state of 64 participants and asked them to summarize the story of a book, Chronicle of a Death Foretold (Marquez, 1981). Secondly, we trained models using crawled 365,802 movie review data; then we evaluated participants' summaries using the pretrained model as a concept of transfer learning. With the background that emotion affects on memories, we investigated the relationship between the evaluation score of the summaries from computational models and the examined psychological measurements. The result shows that although CNN performed the best among other deep neural network algorithms (LSTM, GRU), its results are not related to the psychological state. Rather, GRU shows more explainable results depending on the psychological state. The contribution of this paper can be summarized as follows: (1) we enlighten the relationship between computational models and psychological measurements. (2) we suggest this framework as objective methods to evaluate the emotion; the real sentiment analysis of a person.

期刊:arXiv, 2018年6月3日
网址:
http://www.zhuanzhi.ai/document/a6ab0703558914ebc24b620b12fe1605
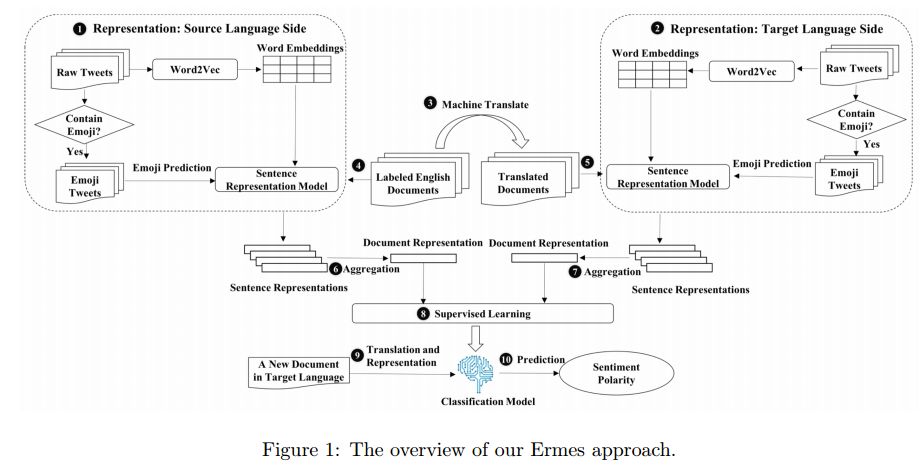
5.Ermes: Emoji-Powered Representation Learning for Cross-Lingual Sentiment Classification(Ermes: 使用表情符号进行跨语言情感分类学习)
作者:Zhenpeng Chen,Sheng Shen,Ziniu Hu,Xuan Lu,Qiaozhu Mei,Xuanzhe Liu
机构:Universidad T´ecnica Federico Santa Mar´ıa
摘要:Most existing sentiment analysis approaches heavily rely on a large amount of labeled data that usually involve time-consuming and error-prone manual annotations. The distribution of this labeled data is significantly imbalanced among languages, e.g., more English texts are labeled than texts in other languages, which presents a major challenge to cross-lingual sentiment analysis. There have been several cross-lingual representation learning techniques that transfer the knowledge learned from a language with abundant labeled examples to another language with much fewer labels. Their performance, however, is usually limited due to the imperfect quality of machine translation and the scarce signal that bridges two languages. In this paper, we employ emojis, a ubiquitous and emotional language, as a new bridge for sentiment analysis across languages. Specifically, we propose a semi-supervised representation learning approach through the task of emoji prediction to learn cross-lingual representations of text that can capture both semantic and sentiment information. The learned representations are then utilized to facilitate cross-lingual sentiment classification. We demonstrate the effectiveness and efficiency of our approach on a representative Amazon review data set that covers three languages and three domains.
期刊:arXiv, 2018年6月7日
网址:
http://www.zhuanzhi.ai/document/d5d5ef87cd39aef16f5a6f946e8928f1
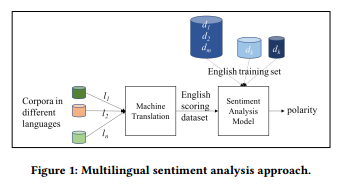
6.Multilingual Sentiment Analysis: An RNN-Based Framework for Limited Data(多语言情感分析:基于rnn框架的有限数据分析)
作者:Ethem F. Can,Aysu Ezen-Can,Fazli Can
ACM SIGIR 2018 Workshop on Learning from Limited or Noisy Data (LND4IR'18)
机构:Bilkent University
摘要:Sentiment analysis is a widely studied NLP task where the goal is to determine opinions, emotions, and evaluations of users towards a product, an entity or a service that they are reviewing. One of the biggest challenges for sentiment analysis is that it is highly language dependent. Word embeddings, sentiment lexicons, and even annotated data are language specific. Further, optimizing models for each language is very time consuming and labor intensive especially for recurrent neural network models. From a resource perspective, it is very challenging to collect data for different languages. In this paper, we look for an answer to the following research question: can a sentiment analysis model trained on a language be reused for sentiment analysis in other languages, Russian, Spanish, Turkish, and Dutch, where the data is more limited? Our goal is to build a single model in the language with the largest dataset available for the task, and reuse it for languages that have limited resources. For this purpose, we train a sentiment analysis model using recurrent neural networks with reviews in English. We then translate reviews in other languages and reuse this model to evaluate the sentiments. Experimental results show that our robust approach of single model trained on English reviews statistically significantly outperforms the baselines in several different languages.
期刊:arXiv, 2018年6月8日
网址:
http://www.zhuanzhi.ai/document/ec9861b3878457398238fa3f9ab6f9d4
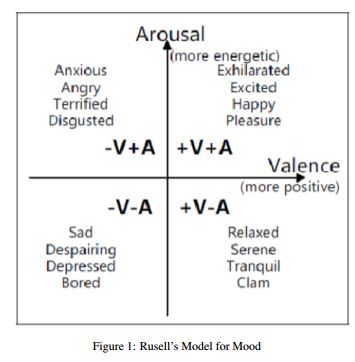
7.Addition of Code Mixed Features to Enhance the Sentiment Prediction of Song Lyrics(通过增加Code 混合特征来增强了歌词的情感性预测)
作者:Gangula Rama Rohit Reddy,Radhika Mamidi
摘要:Sentiment analysis, also called opinion mining, is the field of study that analyzes people's opinions,sentiments, attitudes and emotions. Songs are important to sentiment analysis since the songs and mood are mutually dependent on each other. Based on the selected song it becomes easy to find the mood of the listener, in future it can be used for recommendation. The song lyric is a rich source of datasets containing words that are helpful in analysis and classification of sentiments generated from it. Now a days we observe a lot of inter-sentential and intra-sentential code-mixing in songs which has a varying impact on audience. To study this impact we created a Telugu songs dataset which contained both Telugu-English code-mixed and pure Telugu songs. In this paper, we classify the songs based on its arousal as exciting or non-exciting. We develop a language identification tool and introduce code-mixing features obtained from it as additional features. Our system with these additional features attains 4-5% accuracy greater than traditional approaches on our dataset.
期刊:arXiv, 2018年6月11日
网址:
http://www.zhuanzhi.ai/document/c44e24efdbf6da0efb2eb4c5a080e503
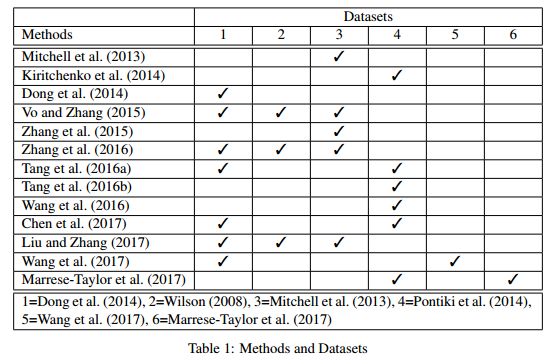
8.Bringing replication and reproduction together with generalisability in NLP: Three reproduction studies for Target Dependent Sentiment Analysis
作者: Moore,Paul Rayson
COLING 2018. Code available at: https://github.com/apmoore1/Bella
机构:Lancaster University
摘要:Lack of repeatability and generalisability are two significant threats to continuing scientific development in Natural Language Processing. Language models and learning methods are so complex that scientific conference papers no longer contain enough space for the technical depth required for replication or reproduction. Taking Target Dependent Sentiment Analysis as a case study, we show how recent work in the field has not consistently released code, or described settings for learning methods in enough detail, and lacks comparability and generalisability in train, test or validation data. To investigate generalisability and to enable state of the art comparative evaluations, we carry out the first reproduction studies of three groups of complementary methods and perform the first large-scale mass evaluation on six different English datasets. Reflecting on our experiences, we recommend that future replication or reproduction experiments should always consider a variety of datasets alongside documenting and releasing their methods and published code in order to minimise the barriers to both repeatability and generalisability. We have released our code with a model zoo on GitHub with Jupyter Notebooks to aid understanding and full documentation, and we recommend that others do the same with their papers at submission time through an anonymised GitHub account.
期刊:arXiv, 2018年6月13日
网址:
http://www.zhuanzhi.ai/document/0ed33ed0c9951b0ef6c3c2dc28bc61c2
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



