【推荐系统论文笔记】DKN: 基于深度知识感知的新闻推荐网络(WWW2018 )
【导读】传统的新闻推荐算法仅仅从语义层对新闻进行表示学习,而忽略了新闻本身包含的知识层面的信息。本文将知识图谱实体嵌入与神经网络相结合,将新闻的语义表示和知识表示融合形成新的embedding表示,以此来进行用户新闻推荐。这种方法考虑了不同层面上的信息,实验证明比传统的方法效果好。
专知成员Xiaowen关于推荐系统相关论文笔记如下:
【AAAI2018】基于注意力机制的交易上下文感知推荐,悉尼科技大学和电子科技大学最新工作
【RecSys2017】基于“翻译”的推荐系统方案,加州大学圣地亚哥分校最新工作(附代码)
【论文】DKN: Deep Knowledge-Aware Network for News Recommendation

论文链接:https://arxiv.org/pdf/1801.08284.pdf
▌摘要
网络新闻推荐系统旨在解决新闻信息爆炸的问题,为用户提供个性化的推荐服务。一般来说,新闻语言是高度浓缩的,包含了很多知识实体和常识。然而,现有的方法很少利用这些外部知识,通常仅从语义层面(semantic level)进行表示学习,无法充分发现新闻之间潜在的知识层面(knowledge level)的联系。因此,对用户的推荐结果仅限于简单的模式,不能合理地扩展。为了解决上述问题,本文提出了一种将知识图谱表示引入到新闻推荐中的深度知识感知网络(deep knowledge-aware network ,DKN)中。
DKN是一个基于内容的深度推荐框架,用于点击率预测。DKN的关键部分是一个多通道和单词-实体对齐的知识感知卷积神经网络(KCNN),它融合了新闻的语义层面和知识层面的表示。KCNN将单词和实体视为多个通道,并在卷积过程中显式地保持它们之间的对齐关系。此外,为了解决用户不同兴趣的问题,作者还在DKN中设计了一个注意力模块,以便动态地聚合当前候选对象的用户历史记录。通过在一个真实的在线新闻平台上进行大量的实验,结果表示,DKN模型在F1-score,AUC等指标上超过了现有的state-of-art模型。
▌简介
各类新闻平台都存在信息过载的问题,为了减轻信息过载的影响,关键是要帮助用户确定他们的阅读兴趣,并提出个性化推荐。
但如今新闻推荐面临三个重要挑战:
1)与电影、餐厅推荐不同,新闻文章具有高度的时效性,相关性在短时间内很快就会失效。过时的新闻经常被更新的新闻所取代,这使得传统的基于ID的方法,比如协同过滤(CF)会因此失效。
2)人们在新闻阅读中对话题敏感,因为他们通常对多个特定的新闻类别感兴趣。如何根据当前候选新闻多样化的阅读历史动态测量用户的兴趣,是新闻推荐系统的关键。
3)新闻语言通常是高度浓缩的,由大量的知识实体和共识组成。例如,如图1所示,一位用户点击一条标题为“Boris Johnson Has Warned Donald Trump To Stick To The Iran Nuclear Deal”的新闻,该新闻包含四个知识实体:“Boris Johnson”, “Donald Trump”, “Iran” 和 “Nuclear”。 事实上,用户也可能对另一条标题为“North Korean EMP Atack Would Cause Mass U.S. Starvation, Says Congressional Report”的新闻感兴趣,因为它与以往的语境知识在常识推理方面有着紧密的联系。然而,传统的语义模型或主题模型只能根据词的共现或聚类结构来判断它们之间的关联性,而很难发现它们之间潜在的知识层次的联系。因此,用户的阅读模式将被缩小到一个有限的范围,不能在现有推荐方法的基础上进行合理的扩展。
为了解决上述问题,作者将知识图谱引入新闻推荐系统中,提出了DKN模型。DKN是一种基于内容的点击率预测模型,它以一条候选新闻和一个用户的点击历史为输入,输出用户点击新闻的概率。具体而言,对于输入新闻,作者通过将新闻内容中的每一个词与知识图中的相关实体相关联来丰富其信息,还搜索并使用每个实体的上下文实体集(即知识图中的近邻)来提供更多的互补和可区分的信息。然后,作者设计了DKN中的一个关键部分,即知识感知卷积神经网络(KCNN),将新闻的词级表示和知识级表示融合起来,生成一个知识感知嵌入向量。与现有工作不同的之处在于:
1)多通道。将新闻的词嵌入、实体嵌入和上下文实体嵌入视为像彩色图像一样的多层通道;
2)单词-实体对齐。因为它将一个词及其相关实体在多个通道中对齐,并应用一个转换函数来消除单词嵌入和实体嵌入空间的异构性。
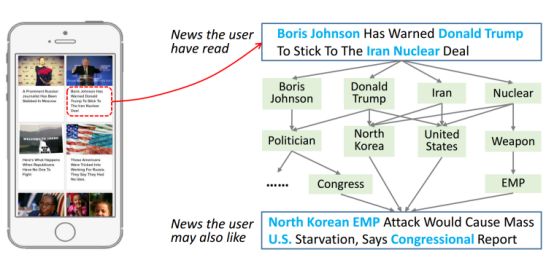
图1. 通过知识实体连接的两条新闻图解
▌准备工作
知识图谱嵌入
一个典型的知识图谱由数以百万计的实体-关系-实体三元组(h,r,t)组成,其中h、r和t分别表示三元组的头、关系和尾。给定知识图谱中的所有三元组,知识图谱嵌入的目标是学习每个实体和关系的低维表示向量,以保存原始知识图的结构信息。近年来,基于翻译的知识图嵌入方法以其简洁的模型和优越的性能受到了广泛的关注。简要回顾几种方法:
1)TransE:
假设h, r, t分别是head, relation, tail对应的向量,优化的目标是使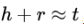
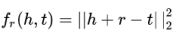
2)TransH
评分函数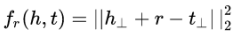
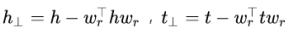
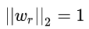
3)TransR
使用一个映射矩阵,把不同的实体向量映射到相同的向量空间中,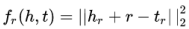
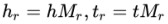
4)TransD
将transr中的投影矩阵替换为实体关系对的两个投影向量的乘积。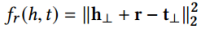
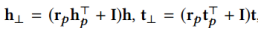
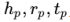
CNN句子特征提取
一种更有效的建模句子的方法是将给定语料库中的每个句子表示为分布式低维向量。本文所用于提取句子特征的CNN源自于Kim CNN,用句子所包含词的词向量组成的二维矩阵,经过一层卷积操作之后再做一次max-over-time的pooling操作得到句子向量,另外在本文中还使用了不同大小的卷积核得到多组不同的向量。
▌方法
一、问题定义
给定用户i,其历史行为是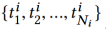
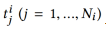
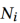
二、知识感知的深度神经网络
DKN的框架如图2所示,DKN以一条候选新闻和一条用户点击的新闻作为输入,每条新闻都使用一个专门设计的KNCC来处理其标题并生成嵌入向量。通过KNCC,我们得到了一组用户点击历史的嵌入向量,为了得到用户关于当前候选新闻的嵌入,作者使用一种基于注意力的方法,自动地将候选新闻匹配到其点击新闻的每一段,并用不同的权重来聚合用户的历史兴趣。
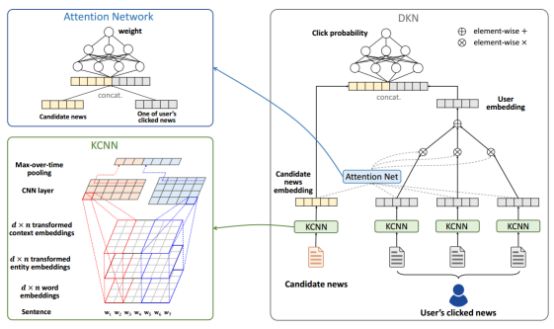
图2. DKN算法框架
知识提取(Knowledge Distillation)
图2说明了知识提取的过程,该过程由四个步骤组成:
1)识别出文本中的知识实体并利用实体链接技术消除歧义;
2)利用新闻文本中的实体与关系就构成了一个原来知识图谱的一个子图,本文把所有与文中的实体的链接在一个step之内的所有实体都扩展到该子图中来;
3)构建好知识子图以后,利用知识图谱嵌入技术得到每个实体的向量;
4)根据实体向量得到对应单词的词向量;
虽然最目前的知识图谱嵌入方法一般可以保留原图中的结构信息,但是在后续的推荐中使用单个实体的学习嵌入信息仍然是有限的。为了帮助识别实体在知识图中的位置,作者为每个实体提取额外的上下文信息。在知识图中,实体e的“上下文”被看作是其近邻的集合:

G是构建的知识图谱子图。上下文表示是上下文实体的embedding的平均值:
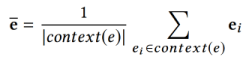
新闻特征提取KCNN
获得了标题中单词和对应实体的向量之后,将单词和相关实体组合起来的一个简单方法是将这些实体视为“伪词”,并将它们连接到单词序列中。比如:
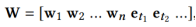
但是,作者认为这种简单的连接策略有以下的局限性:1)连接策略破坏了词和关联实体之间的联系,并且不知道它们之间的一致性。2)不同的方法学习词嵌入和实体嵌入,这意味着不适合在单个向量空间中将它们融合在一起。3)级联策略隐式地强制词嵌入和实体嵌入具有相同的维数,这在实际设置中可能不是最优的,因为词嵌入和实体嵌入的最优维度可能会相互影响。考虑到以上的局限性,作者提出了一个多通道和词-实体对齐的KCNN,用于将单词语义和知识信息结合起来。具体做法是先把实体的向量,和实体上下文向量映射到一个空间里: 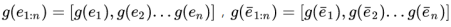
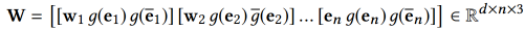
获得了多通道的词表示之后,再用CNN进行处理获取新闻标题的表示: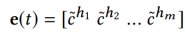
基于注意力的用户兴趣预测
注意网络如图2左上部分所示。具体地,对于用户i点击的新闻ti和候选新闻tj,作者先将它们的嵌入连接起来,然后用一个DNNH作为注意网络和Softmax函数来计算归一化的影响力权重:
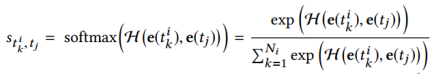
用户i对候选新闻k的表示: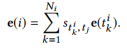
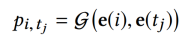
▌实验
数据集
本文的数据集来自Bing新闻的服务器日志。每一段日志主要包含时间戳、用户id、新闻url、新闻标题和单击计数(0表示不点击,1表示单击)。作者收集了一个随机抽样平衡数据集,从2016年10月16日到2017年6月11日作为训练集,从2017年6月12-8月11作为测试集。使用的知识图谱数据是Microsoft Satori。新闻数据集和提取的知识图的基本统计和分布分别见表1和图3。
表1. 新闻数据集的基本统计及提取的知识图谱
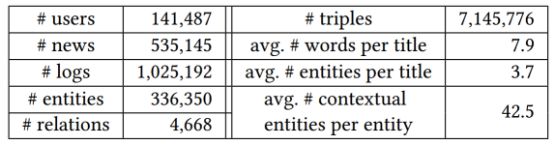
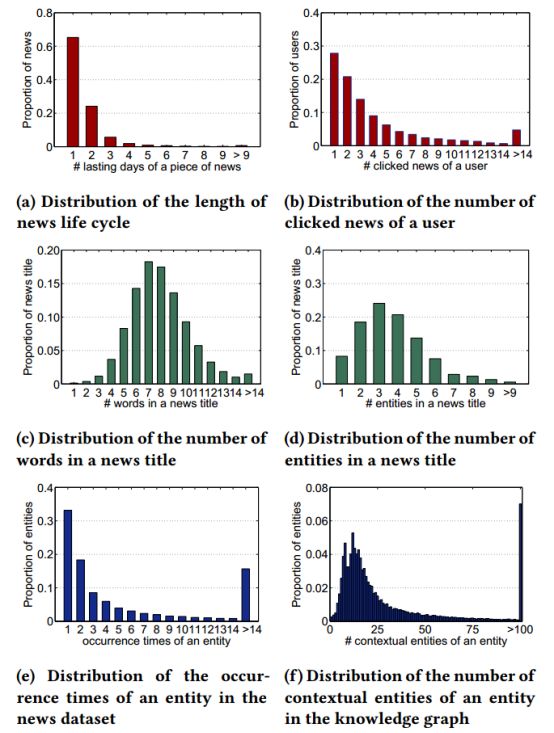
图3. 新闻数据集中统计分布的图解和知识图谱的提取。
Baseline方法
1. LibFM
2. KPCNN
3. DSSM
4. DeepWide
5. DeepFM
6. YouTubeNet
7. DMF
评价指标
1. ROC曲线下面积(AUC)
2. F1-score
实验结果
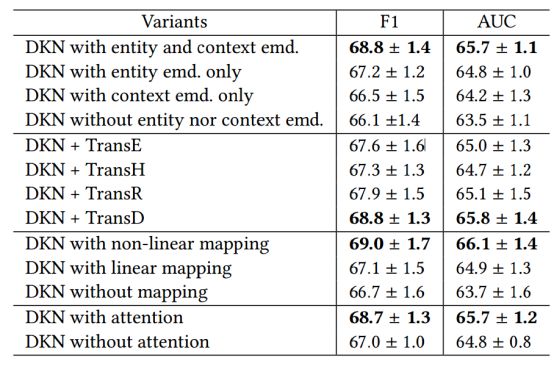
不同模型的实验结果对比如表2所示,从表中可以看出,DKN在F1-score和AUC两个指标上,都超过了作为baseline的LibFM,DeepFM,DSSM等模型。另外,针对DKN不同的配置,作者也做了对比实验,见表3。
表2. 不同模型对比
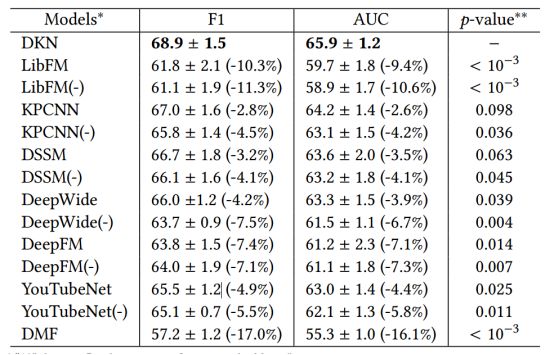
表3. DKN变体的比较
▌实例分析
为了直观地展示知识图和注意力网络的使用效果,作者随机抽取了一个用户,并从训练集和测试集中提取他的所有日志(为了简单起见,省略了标签为0的训练日志)。如表4所示,点击后的新闻清楚地显示了他的兴趣点:1号-3号涉及汽车,第4-6号涉及政治(类别不包含在原始数据集中,是由作者手工标记)。
表4. 随机抽样用户的培训和测试日志(省略标签为0的培训日志)

作者使用全部的训练数据来训练DKN的全特征和没有实体或上下文嵌入的DKN,然后将该用户的每一对可能的训练日志和测试日志提供给这两个经过训练的模型,并获得它们的注意网络的输出值。结果如图4所示,较深的蓝色表示更大的注意力值。从图8(a)中可以观察到,测试日志中的第一个标题与训练日志中的“Cars”有很高的注意力值,因为它们有相同的单词“Tesla”,但是第二个标题的结果不太令人满意,因为第二个标题与训练集中的任何标题,包括第1-3号,没有明确的词汇相似性。在测试日志的第三个标题中,情况类似。相比之下,在图8b中,我们看到注意网络精确地捕捉了两个类别“Cars”和“Politics”之间的关联性。这是因为在知识图谱中,“General Motors”和“Ford Inc.”与“Tesla Inc.”和“Elon Musk”分享了大量的上下文。
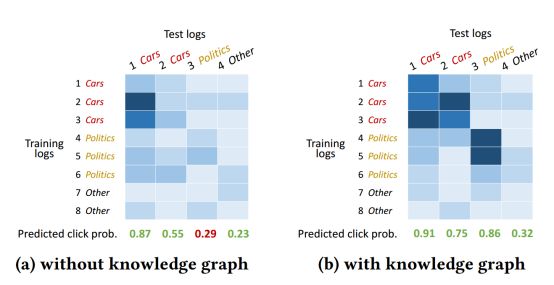
图4. 随机抽样用户训练日志和测试日志的注意力可视化
▌总结
本文针对新闻文本时效性强,包含很多单词实体的特点,提出了DKN模型。DKN是一种content-based的模型,非常适合用来做新闻点击率预测。其特点是融合了知识图谱与深度学习,从语义层面和知识两个层面对新闻进行表示,实体和单词的对齐机制更是融合了异构的信息源,能更好地捕捉新闻之间的隐含关系。对于不同的候选新闻,DKN使用attention机制来动态地学习用户历史点击的表示。实验结果表示,加入的实体表示的DKN模型对baseline模型体现了显著的优越性,相信以后怎样更充分地利用知识提升深度神经网络的效果是一个重要的研究方向,值得人们探究。
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
点击“阅读原文”,使用专知!
展开全文



