【ICCV2017视觉盛宴概况】何恺明博士包揽最佳论文和最佳学生论文奖!Facebook成大赢家!
点击上方“专知”关注获取更多AI知识!
【导读】当地时间 10月 22 日到10月29日,两年一度的计算机视觉国际顶级会议 International Conference on Computer Vision(ICCV 2017)正在意大利威尼斯开幕,来自世界各地的计算机视觉专家聚集在威尼斯介绍计算机视觉和相关领域的最新进展。大会公布了各奖项包括最佳论文奖(Marr Prize)、最佳学生论文奖、Honorable mentions、Azriel Rosenfeld lifetime achievement award、Distinguished researcher award 、Everingham prize 、Helmholtz prize. Facebook成为最大赢家,其中Facebook 人工智能实验室研究科学家何恺明包揽最佳论文奖(Marr Prize)和最佳学生论文奖。贾扬清Caffe团队获得Everingham prize等。

ICCV 2017 概况
国际计算机视觉会议ICCV和计算机视觉与模式识别会议(CVPR),以及欧洲计算机视觉会议(ECCV)并称计算机视觉领域的三大顶级会议。本次会议涵盖三维立体视觉、医学图像分析、人脸与姿态学习、底层视觉与图像、运动与跟踪、目标检测与识别、优化方法、图像的分割与边缘提取、统计方法与学习、视频事件检测与行为识别等领域。该会自1987年创办以来,每两年召开一次,有着在世界各大洲轮换举办的惯例。各领域专家和工业界人士积极参与,推动了计算机视觉技术从萌芽到发展,从实验室原型到实际应用的进程。
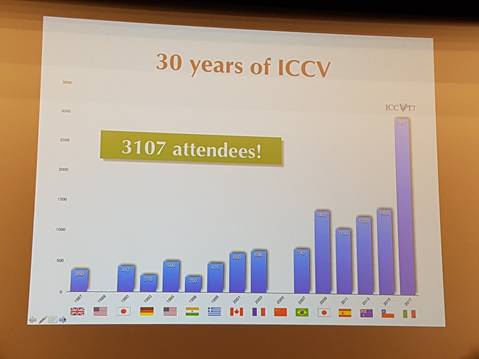
在参会人数方面,今年的参会人数为3107人,突破3000大关,是上一届ICCV 2015人数的两倍多,可以看出计算机视觉这个领域这几年有多么火热。

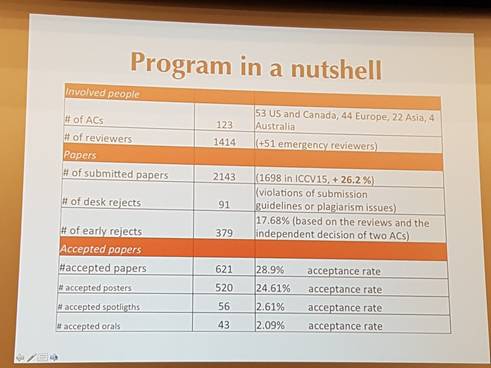
论文方面,录取论文数目历史最多。本届会议收到来自世界各地的论文投稿2143篇,录取621篇,其中口头报告43篇,海报论文520篇,录取率分别是2.09%和28.9%,可见竞争之激烈。
ICCV 2017 各大奖项

最佳论文奖 (Marr Prize)
· 论文:《Mask R-CNN》
作者:Kaiming He, Georgia Gkioxari, Piotr Dollár, Ross Girshick
论文地址:https://research.fb.com/publications/mask-r-cnn/
Arxiv:https://arxiv.org/abs/1703.06870
这篇论文提出了一个小巧、灵活的通用对象实例分割框架(object instance segmentation)。Mask R-CNN不仅可对图像中的目标进行检测,还可以对每一个目标给出一个高质量的分割结果。其在Faster R-CNN基础之上进行扩展,并行地在bounding box recognition分支上添加一个用于预测目标掩模(objectmask)的新分支。该网络还很容易扩展到其他任务中,比如估计人的姿势,也就是关键点识别(person keypoint detection)。该框架在COCO的一些列挑战任务重都取得了最好的结果,包括实例分割(instance segmentation)、候选框目标检测(bounding-box object detection)和人关键点检测(personkeypoint detection)。

最佳学生论文奖
· 论文:《Focal Loss for Dense Object Detection》
作者:Tsung-Yi Lin, Priya Goyal, Ross Girshick,Kaiming He, Piotr Dollár
论文地址:https://arxiv.org/abs/1708.02002
现有的基于深度学习的物体检测方法主要分为两大类,一类是两步法(two-stage,以Faster-RCNN为代表),一类是一步法(one-stage,以YOLO,SSD为代表)。目前one-stage的方法相比two-stage的方法具有速度快且模型简单的优势,但精度低于two-stage的方法。这篇文章中,作者发现造成这种现象的主要原因是正负样本比例的极度不平衡。这篇文章构造了一个新的损失函数,可以动态的调整交叉熵,通过难易样本对损失值的影响来解决样本不平衡问题,实现简单且实验效果显著由于先前的在线难例挖掘(OHEM)之类的方法,可以大幅度提升one-stage物体检测方法的性能。
其他奖项:

N Rhinehart , KM Kitani
First-Person Forecasting with Online Inverse Reinforcement Learning

Tomaso Poggio
主页:https://mcgovern.mit.edu/principal-investigators/tomaso-poggio
Tomaso Poggio,现年67岁,麻省理工学院人工智能实验室脑与认知科学系的尤金•麦克德莫特讲座教授,同时也是该院生物和计算机学习中心的联席主任。Poggio于1981年开始在麻省理工学院任教,此前他曾在德国图宾根马克思普朗克研究所的生物控制论研究室工作过十年时间。1970年,他获得热那亚大学的博士学位。Poggio是意大利科学院的外籍院士,也是美国艺术与科学研究院的研究员。

Luc Van Gool
主页:
https://www.vision.ee.ethz.ch/en/members/get_member.cgi?id=1
比利时鲁汶大学教授,图像识别公司Kooab联合创始人并担任首席技术顾问,后公司被高通收购。Prof. Dr. Gool同时也是eSaturnus, Eyetronics, GeoAutomation and Procedural Inc的联合创始人。他同时担任 Journal Foundations & Trends in Computer Graphics and ComputerVision总编辑. 他在瑞士苏黎世联邦理工大学领导计算机视觉实验室同时在比利时鲁汶大学任教授. 他的主要研究方向是3D重建和建模,目标识别,视觉跟踪以及机器人控制。
Richard Szeliski
主页:
http://szeliski.org/RichardSzeliski.htm
Richard Szeliski博士计算机视觉领域的大师级人物。Szeliski博士在计算机视觉研究方面有25年以上的丰富经验,先后任职干DEC和微软研究院。1996年,他在微软研究院任职期间,提出一种基于运动的全景图像拼接模型,采用L-M算法,通过求图像间的几何变换关系来进行图像匹配。此方法是图像拼接领域的经典算法,RichardSzeliski也因此成为图像拼接领域的奠基人。

Yangqing Jia (贾扬清) http://daggerfs.com/

何恺明大神
除了本次ICCV2017,何恺明博士获得最佳论文奖与最佳学生论文奖,Facebook 上,Cool!

个人学术主页:http://kaiminghe.com/
此外,他已经在CVPR 2016、2009两次获得CVPR最佳论文奖。来回顾下:

CVPR2016 最佳论文奖
论文: 《Deep Residual Learning for Image Recognition》
作者:Kaiming He, XiangyuZhang, Shaoqing Ren, Jian Sun
论文地址:https://arxiv.org/abs/1512.03385
这篇文章提出了一个残差学习的框架,以减轻网络的训练负担,这是个比以往的网络要深的多的网络,并且明确地将层作为输入学习残差函数,而不是学习未知的函数,以应对更深的神经网络往往更难以训练的情况。文章提供了非常全面的实验数据来证明,残差网络更容易被优化,并且可以在深度增加的情况下让精度也增加。在ImageNet的数据集上评测了一个深度152层(是VGG的8倍)的残差网络,但依旧拥有比VGG更低的复杂度。残差网络整体达成了3.57%的错误率,这个结果获得了ILSVRC2015的分类任务第一名,还用CIFAR-10数据集分析了100层和1000层的网络。此网络在深度残差网络的基础上做了提交的版本参加ILSVRC和COCO2015的比赛,获得了ImageNet对象检测,Imagenet对象定位,COCO对象检测和COCO图像分割的第一名。
CVPR2009 最佳论文奖

论文: 《Single Image Haze RemovalUsing Dark Channel Prior》
作者:Kaiming He, Jian Sun,Xiaoou Tang
论文地址:http://ieeexplore.ieee.org/document/5206515
这篇论文研究的问题是图像的去雾技术,它可以还原图像的颜色和能见度,同时也能利用雾的浓度来估计物体的距离,这些在计算机视觉上都有重要应用(例如三维重建,物体识别)。但是之前人们还没找到简单有效的方法来达到这个目的。在这篇论文里,文章找到了一个非常简单的,甚至说令人惊讶统计规律,并提出了有效的去雾方法。与之前的方法不同,本文把注意力放到了无雾图像的统计特征上,并且发现,在无雾图像中,每一个局部区域都很有可能会有阴影,或者是纯颜色的东西,又或者是黑色的东西。因此,每一个局部区域都很有可能有至少一个颜色通道会有很低的值。把这个统计规律叫做Dark Channel Prior。直观来说,Dark Channel Prior认为每一个局部区域都总有一些很暗的东西。这个规律很简单,但在我们研究的去雾问题上却是本质的基本规律。提出的Dark Channel Prior能很有效地去除雾的影响,同时利用物的浓度来估算物体的距离。
何恺明博士简介:
何恺明博士,2007年清华大学毕业之后开始在微软亚洲研究院(MSRA)实习,2011年香港中文大学博士毕业后正式加入MSRA,目前在Facebook人工智能实验室(FAIR)实验室担任研究科学家。何恺明博士最让人印象深刻的是曾两次以第一作者身份摘得CVPR最佳论文奖(2009和2016),其中2016年CVPR最佳论文为图像识别中的深度残差学习(Deep Residual Learning for Image Recognition),就是举世闻名的152层深度残差网络ResNet-152。
更多延伸阅读:
曾为状元郎,靠去雾霾算法名震世界,已是计算机视觉领域年轻的翘楚——何恺明
知乎:https://zhuanlan.zhihu.com/p/22887026
特注:
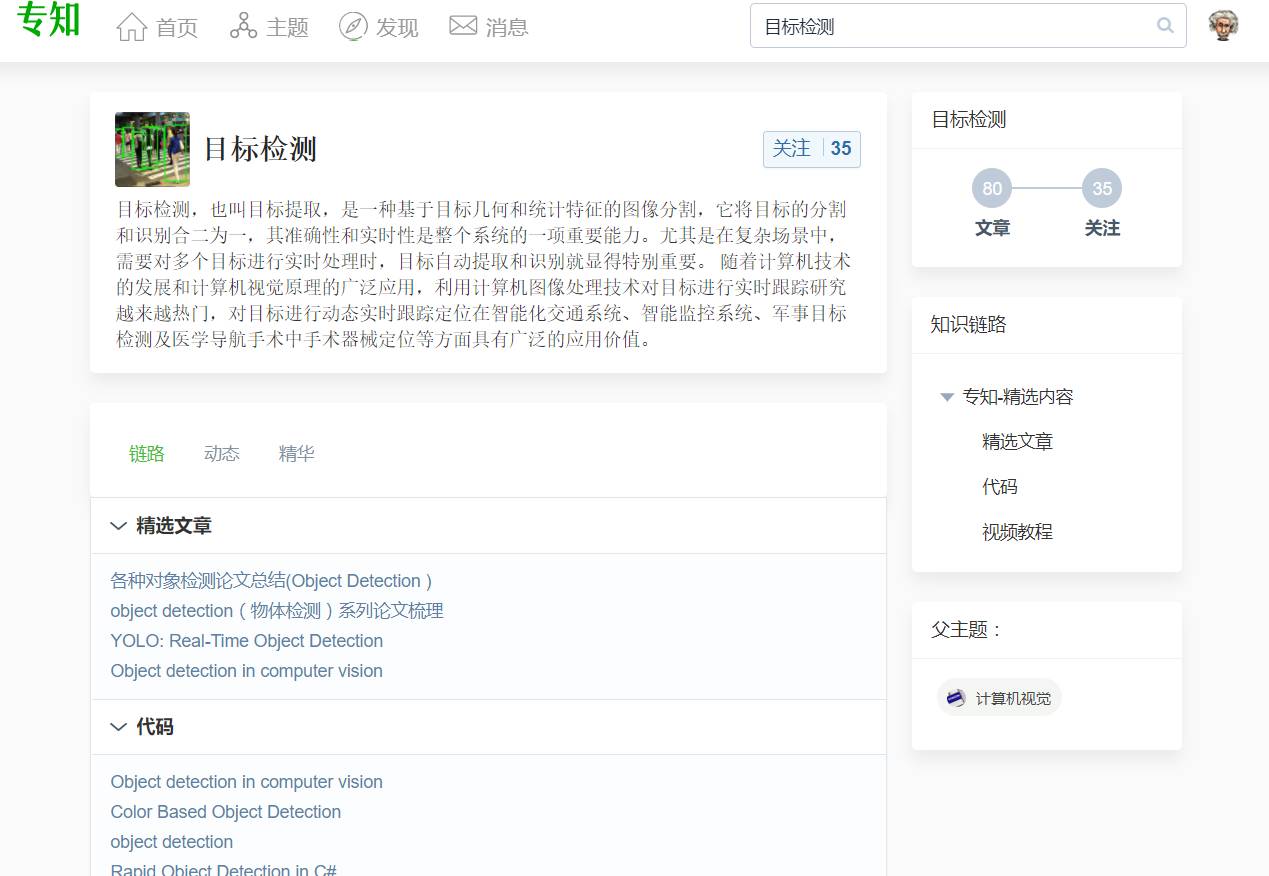
针对ICCV2017获奖最佳论文Mask R-CNN,我们专知整理了相关资料。请登录www.zhuanzhi.ai或者点击阅读原文,顶端搜索“目标检测” 主题,直接获取查看获得全网收录资源进行查看, 涵盖论文等资源下载链接,并获取更多与视觉识别的知识资料!如下图所示。
此外,请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),后台回复“目标检测” 就可以获取专知内容组整理的知识资料pdf文档!
欢迎转发到你的微信群和朋友圈,分享专业AI知识!
获取更多关于机器学习以及人工智能知识资料,请访问www.zhuanzhi.ai, 或者点击阅读原文,即可得到!
-END-
欢迎使用专知
专知,一个新的认知方式!目前聚焦在人工智能领域为AI从业者提供专业可信的知识分发服务, 包括主题定制、主题链路、搜索发现等服务,帮你又好又快找到所需知识。
使用方法>>访问www.zhuanzhi.ai, 或点击文章下方“阅读原文”即可访问专知
中国科学院自动化研究所专知团队
@2017 专知
专 · 知
关注我们的公众号,获取最新关于专知以及人工智能的资讯、技术、算法、深度干货等内容。扫一扫下方关注我们的微信公众号。


点击“阅读原文”,使用专知!
展开全文



