【干货】走进神经网络:直观地了解神经网络工作机制
【导读】1月4日,Mateusz Dziubek发布了一篇基础的介绍神经网络的博文,作者用一种直观的方法来解释神经网络以及其学习过程,作者首先探讨了导致神经网络过于复杂的几个因素:大量系数、梯度计算慢、计算复杂。并通过典型的前馈神经网络和简洁的分类示例来逐步揭开神经网络的面纱。如果您没有学习过神经网络或只是简单地使用接口完成过相应的工作,并且想一探神经网络的工作机制,那么本文是一篇不错的资料。专知内容组编辑整理。

Let me introduce you to neural networks
本文使用一些简单的数学公式和术语(大多本科学过),提供了一种直观方法来解释神经网络及其学习过程(反向传播)。作为知识分享的忠实推崇者,我希望能够为那些开始AI/ML学习的人们提供一些帮助或启发,或者为那些盲目使用诸如Keras等高级工具的人澄清一些事情。 使他们无需再费周折…
把神经网络neural network(NN)看作一个数学函数是合理的,由于三个原因使得NN在实践中往往是非常复杂的:
1)它有大量的系数(权重),常常超过几千万,
2)它是一个深度嵌套函数,因此即使是简单的梯度计算(偏导数)也是相对较慢的,
3)大部分的计算都是在多维张量上进行的。
图1包含了一个简单的神经网络的典型结构,它包含三个基本组件:单元(具有值的单个圆,输入x,输出y或偏置1),层(排列成一个垂直组的单元)和权重(单元之间的连接,值w代表其强度)。公式1,2,3,4和5将该图形表示转换为数学公式。
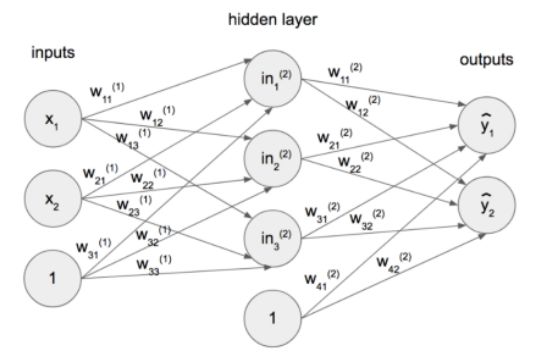
图1:具有一个隐藏层(输入和输出之间的层)的简单神经网络。
“感知器”是神经网络的一个常用名称,输入与输出直接耦合在一起(没有隐藏层,与图1不同)。隐藏(中间)层的存在,阻止了输入和输出之间的直接连接,使得神经网络能够模型高度非线性的数学函数。Norvig和Russell证明了这一点,以XOR gate为例,用以下方式:“[...]线性分类器[...]可以表示输入空间中的线性决策边界。对于进位函数,这是正确的,这是一个逻辑AND[...]。然而,求和函数是两个输入的XOR(异或)。这个函数不是线性可分的,所以感知器不能学习它。线性可分的函数只是所有布尔函数的一小部分。“(P. Norvig and S. J. Russell, Artificial Intelligence: A Modern Approach, Prentice Hall, 2010)。
在深入研究神经网络(NNs)的学习过程之前,对之前的模型做两个补充是很重要的:
1)误差函数(也称为成本函数),
2)激活函数。
补充1. 表示预测的最可靠方法是通过概率向量进行预测。我们考虑一个基于标签图像的啤酒名称预测的例子。图2显示了一个分类器的概率输出(注意所有的值总和为1),与期望输出作比较。在本节中引入的一个成本函数,称为分类交叉熵(方程6),简单地衡量这两个概率分布(预测和期望)之间的相关性。注意,通过一个one-hot编码示例的乘法,强制函数只比较期望分布的非零元素,并将分类器输出的值从1被惩罚到接近于1的值(由于对数的性质)。
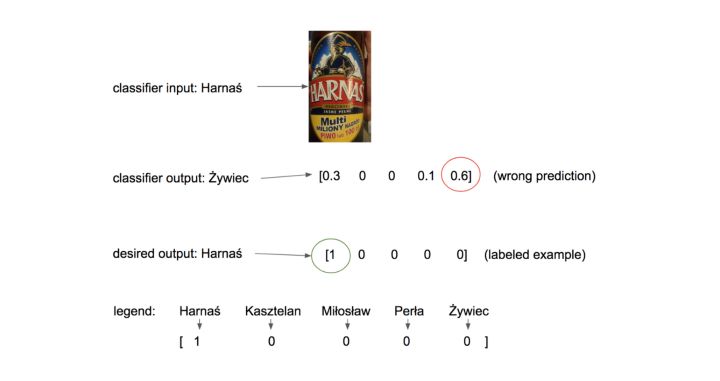
图2:分类器输入、分类器输出和期望的(one-hot编码)输出的图例。
d_i是one-hot编码(期望的)概率向量d的第i个元素,
p_i是分类器预测的概率向量p的第i个元素。
补充2. 单元(Units)的值很少被显式传播到下一层。所谓的激活函数是被用来代替的。这一节中介绍的函数是Sigmoid(公式7)。图1中简单的神经网络的更新模型如图3所示。值得指出的一点是sigmoid和softmax函数(公式8)之间的区别,它们都是在人工神经网络中使用的。sigmoid输入单个值并输出归一化的标量,但softmax输入一个值列表并输出一个向量(范围是[0,1]的实数且和为1),因此可以将其解释为概率分布。Sigmoid用于隐藏单位,而softmax通常应用于最后一个输出层。这两个函数都可以归类为逻辑函数。
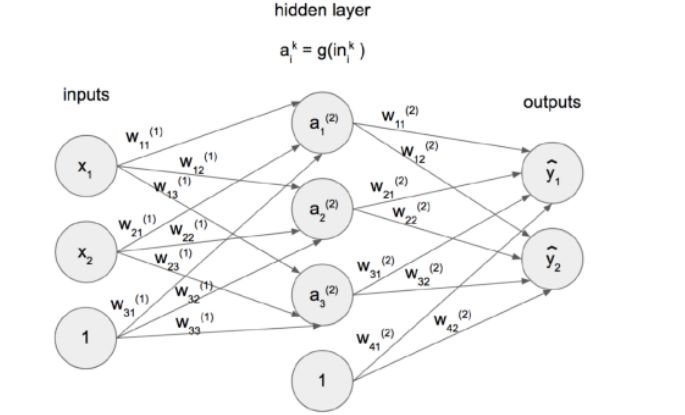
图3:图1中简单神经网络的更新模型。g是sigmoid激活函数。输出通常使用softmax进行正则化。

Softmax函数s(z)_j将K维向量z压缩成K维概率分布,其中j = 1,...,K。
神经网络学习过程的目标是找到正确的权值,即权重,将产生一个数学模型,其中输入的差异清楚地表示在输出向量中,这是分析和预测的基础。例如,在一个经过训练的犬种分类器中,德国牧羊犬图像的输出向量明显不同于约克犬。这可以很容易地进行解释,并产生正确的人类可读的品种预测。目前,最著名的训练网络的方法是通过反向传播算法。该方法的主要思想是计算相对于每个权重的成本函数E(例如分类交叉熵)的梯度,对每一个权值进行计算,然后根据公式9中所示的一些梯度来进行更新。

alpha是一个学习率(指应该使用哪一部分的梯度)。
我们来考虑图4中的神经网络,它具有三个神经元,一个隐层和sigmoid激活函数。 在进行反向传播之前,执行所谓的正向传递,它仅仅是一个给定输入的数学推断(等式10)。
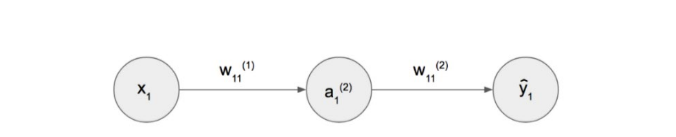
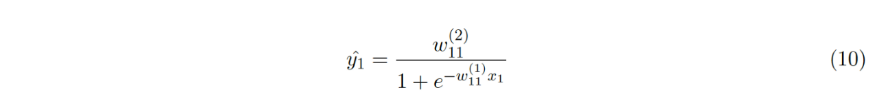
图4:一个简单的带有sigmod激活函数的神经网络
如前所述,NN的学习算法基于计算每个权重的偏导数。 函数的深层嵌套(即更复杂的网络)鼓励利用链式规则。图5概括了使用分类交叉熵误差函数E的反向传播的单独步骤。公式11和公式12表示学习过程发生所必需的符号梯度计算。在这里,可以使用一个简单的sigmoid函数的衍生物。
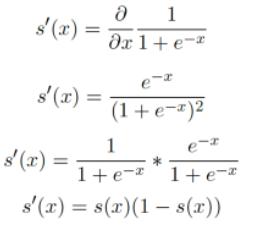
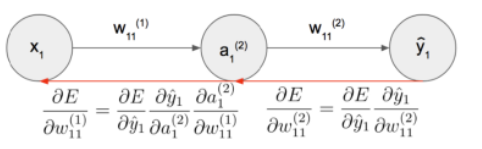
图5 链式规则反向传播过程中的描述
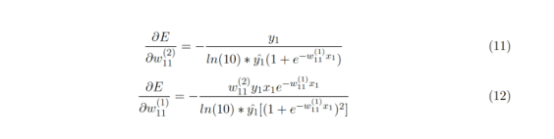
在后面的符号计算中,考虑图5中神经网络的以下输入:
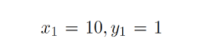
1)训练的例子。 当输入等于10时,NN应力争返回1
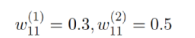
2)第一次正向通过使用的随机初始化权重(等式10)。
给定随机初始化权重和输入,学习过程的主要步骤是进行推断。 产生的结果如下:
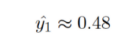
这与期望值相差太远。向后传播允许计算每个权重的梯度,即:
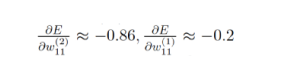
在应用来自等式9的更新规则之后,在学习率α= 0.5的情况下,新的权重是:
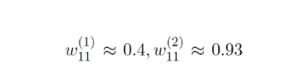
并产生结果:
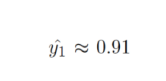
这个结果更接近所需的1! 由于提出的算法是迭代的。 随着上述步骤重复数量的增加和例子数量的增加,它应该收敛到最佳的权重(全局或局部)。
原文链接:
https://towardsdatascience.com/let-me-introduce-you-to-neural-networks-fedf4253106a
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!

点击“阅读原文”,使用专知!
展开全文



