【干货】30+深度学习最佳实践经验:从数据、算法、训练到网络结构
【导读】Nishant Gaurav分享了他的一些深度学习最佳实践经验,如何准备数据集,如何设置和调整学习率,以及如何训练模型,和针对不同场景和问题设置不同的网络结构等等,这些都是在深度学习实践中非常重要的经验,这篇文章带你了解其中的部分细节,希望大家关注和收藏。后续专知小组准备开设专栏手把手指导大家搭建深度学习模型以及框架实践,敬请关注。
编译 | 专知
参与 | Yukun, Huaiwen
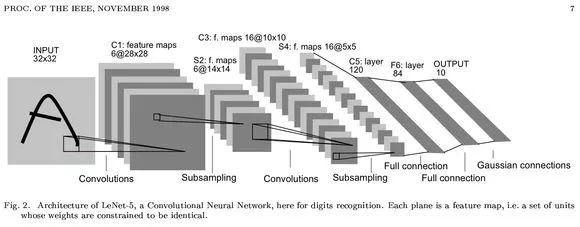
数据集篇(Data Set)
1. 物尽其用,哪怕再小的数据集都包含知识,见https://youtu.be/Th_ckFbc6bI?t=3503
2. 某些比赛的排行榜并不能真实反应模型的性能,见https://youtu.be/sHcLkfRrgoQ?t=2739
3. 深入理解数据集。如果你不能保证你能很好的处理异常值,那就把它删了。 见https://youtu.be/sHcLkfRrgoQ?t=2898
4. 跟进训练步骤:仔细分析不正确的分类样例,你会发现你的训练步骤中出现的问题,比如数据集的裁剪导致图像大部分被错误分类。见:https://youtu.be/IPBSB1HLNLo?t=1674
5. 数据增广:我们可以使用数据增广来扩大数据集,但是增广的多了也不是好事,需要有个度,见https://youtu.be/9C06ZPF8Uuc?t=1408
6. 测试时间增广(TTA):增加准确度https://youtu.be/JNxcznsrRb8?t=3669
7. 数据集里的缺失值有时候非常影响结果,所以思考如何处理它们总是很重要。
学习率篇(Learning Rate)
1. 使用学习率查找器来找学习率,选择能令损失函数陡峭收敛的学习率,而不是能使收敛概率最大的学习率见https://youtu.be/JNxcznsrRb8?t=1320
2. 在某些数据集(如imagenet)上使用预训练模型时,如果将该模型用于任何新数据集,则需要使用不同的学习率。初始层需要较小的学习率,而较深层需要相对较大的学习率。当新数据集与原始数据集相似时(例如,猫vs狗类似于imagenet),权重的比率可以适当调高. 见https://youtu.be/9C06ZPF8Uuc?t=5858
3. 余弦退火(Cosine annealing),现在Pytorch中默认支持见https://youtu.be/JNxcznsrRb8?t=2291
4. SGD重启
5. 为了解决梯度爆炸,可以用单位矩阵来初始化,这样也允许采用更高的学习率。见
https://youtu.be/sHcLkfRrgoQ?t=7780
训练篇(Training)
1. 让你使用很深的网络的预训练模型,如Resnet50的pre-train, 而你的数据集和Resnet50的数据集很相似,那么你可以考虑将部分预训练参数冻结起来,不再更新,PyTorch里的bn_freeze能提供很好的帮助,见https://youtu.be/9C06ZPF8Uuc?t=1109
2. 如果你的数据集和Pre-trainmodel的数据集不相似时,可以先冻结全部参数,然后从较小尺寸,比如64x64开始慢慢解冻和训练,然后扩大到更大的尺度比如128x128和256x256,见https://youtu.be/9C06ZPF8Uuc?t=5898
3. Kaiming He初始化,何凯明提出的一种初始化方法,Pytorch默认实现了这个功能。https://youtu.be/J99NV9Cr75I?t=2844
4. Adam Optimizer有一个更好的版本叫做AdamW
激活函数篇(Activation functions)
1. 理论上softmax和logoftmax是相互缩放的版本,根据经验来看logoftmax更好。
2. 多标签分类应该用sigmoid而不是softmax。
3. 当你知道输出的最小值和最大值时,应用sigmoid可以降低神经网络参数,并且训练速度更快,见https://youtu.be/J99NV9Cr75I?t=4101,就像你知道输出是概率然后使用softmax一样,见https://youtu.be/9C06ZPF8Uuc?t=4498。
4. 在隐层之间的权重矩阵激活函数建议使用tanh, 见https://youtu.be/sHcLkfRrgoQ?t=6237。
网络结构篇(Architectures)
1. 对于NLP任务,必须在Adam Optimizer中使用稍微不同的beta参数。见1. https://youtu.be/gbceqO8PpBg?t=7175。
2. 对于NLP任务,我们在某些LSTM模型中使用了不同的dropout。这些dropout必须具有一定的比例。见https://youtu.be/gbceqO8PpBg?t=7206。
3. 对于NLP任务,我们也可以使用梯度阶段。见https://youtu.be/gbceqO8PpBg?t=7316。
4. 所有的NLP模型都需要正则化,见https://youtu.be/gbceqO8PpBg?t=7262。
5. 对于梯度爆炸,可以使用GRU 替代原本的RNN cell。
6. 在情绪分析中,迁移学习的表现优于状态分析模型。https://youtu.be/gbceqO8PpBg?t=77387.
7. Stride 2卷积与Max Pool具有相同的效果。
8. Batch normalization使我们能够设计更具弹性的深层网络,并且学习率可以提高。它类似于dropout,用法上也和dropout一样,只在训练环境下使用。见https://youtu.be/H3g26EVADgY?t=5732
9. 在relU之后做Batch normalization效果最好。
10. Adaptive Average pooling和Adaptive Max Pooling的连接起来效果会更好。见https://youtu.be/H3g26EVADgY?t=7611。
原文链接:
http://forums.fast.ai/t/30-best-practices/12344
更多教程资料请访问:人工智能知识资料全集
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



