【论文推荐】最新八篇行人再识别相关论文—多级高斯模型、密度自适应、注意力感知组成网络、图像-图像域适应、自适应采样
【导读】专知内容组整理了最近八篇行人再识别(Person Re-Identification)相关文章,为大家进行介绍,欢迎查看!
1.A Deep Structure of Person Re-Identification using Multi-Level Gaussian Models(一种使用多级高斯模型的行人再识别的深度结构)
作者:Dinesh Kumar Vishwakarma,Sakshi Upadhyay
摘要:Person re-identification is being widely used in the forensic, and security and surveillance system, but person re-identification is a challenging task in real life scenario. Hence, in this work, a new feature descriptor model has been proposed using a multilayer framework of Gaussian distribution model on pixel features, which include color moments, color space values and Schmid filter responses. An image of a person usually consists of distinct body regions, usually with differentiable clothing followed by local colors and texture patterns. Thus, the image is evaluated locally by dividing the image into overlapping regions. Each region is further fragmented into a set of local Gaussians on small patches. A global Gaussian encodes, these local Gaussians for each region creating a multi-level structure. Hence, the global picture of a person is described by local level information present in it, which is often ignored. Also, we have analyzed the efficiency of earlier metric learning methods on this descriptor. The performance of the descriptor is evaluated on four public available challenging datasets and the highest accuracy achieved on these datasets are compared with similar state-of-the-arts, which demonstrate the superior performance.
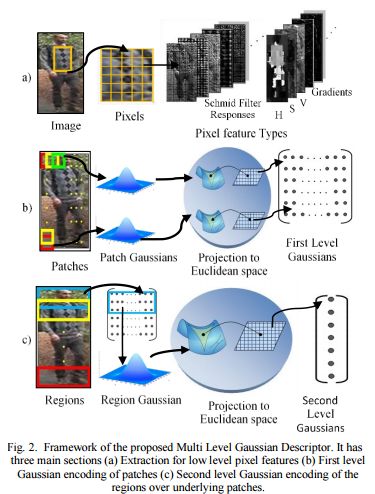
期刊:arXiv, 2018年5月20日
网址:
http://www.zhuanzhi.ai/document/4ab89798127591df6457a63e86c91a3f
2.Density-Adaptive Kernel based Re-Ranking for Person Re-Identification(基于密度自适应核重排序的行人再识别)
作者:Ruo-Pei Guo,Chun-Guang Li,Yonghua Li,Jiaru Lin
This work has been accepted by ICPR 2018
机构:Beijing University of Posts and Telecommunications
摘要:Person Re-Identification (ReID) refers to the task of verifying the identity of a pedestrian observed from non-overlapping surveillance cameras views. Recently, it has been validated that re-ranking could bring extra performance improvements in person ReID. However, the current re-ranking approaches either require feedbacks from users or suffer from burdensome computation cost. In this paper, we propose to exploit a density-adaptive kernel technique to perform efficient and effective re-ranking for person ReID. Specifically, we present two simple yet effective re-ranking methods, termed inverse Density-Adaptive Kernel based Re-ranking (inv-DAKR) and bidirectional Density-Adaptive Kernel based Re-ranking (bi-DAKR), which are based on a smooth kernel function with a density-adaptive parameter. Experiments on six benchmark data sets confirm that our proposals are effective and efficient.
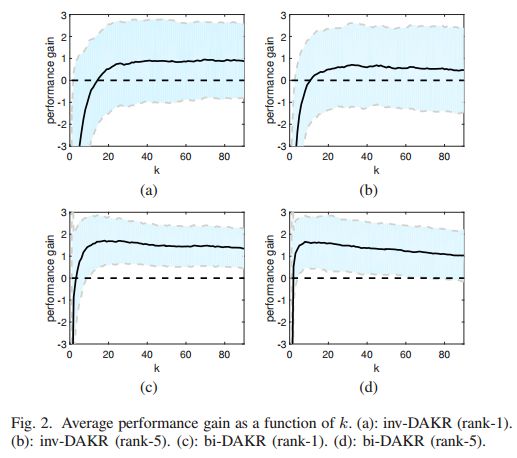
期刊:arXiv, 2018年5月20日
网址:
http://www.zhuanzhi.ai/document/7ea43e5d6de470cf14afb33d309afa70
3.Attention-Aware Compositional Network for Person Re-identification(基于注意力感知组成网络的行人再识别)
作者:Jing Xu,Rui Zhao,Feng Zhu,Huaming Wang,Wanli Ouyang
Accepted at CVPR2018
机构:The University of Sydney
摘要:Person re-identification (ReID) is to identify pedestrians observed from different camera views based on visual appearance. It is a challenging task due to large pose variations, complex background clutters and severe occlusions. Recently, human pose estimation by predicting joint locations was largely improved in accuracy. It is reasonable to use pose estimation results for handling pose variations and background clutters, and such attempts have obtained great improvement in ReID performance. However, we argue that the pose information was not well utilized and hasn't yet been fully exploited for person ReID. In this work, we introduce a novel framework called Attention-Aware Compositional Network (AACN) for person ReID. AACN consists of two main components: Pose-guided Part Attention (PPA) and Attention-aware Feature Composition (AFC). PPA is learned and applied to mask out undesirable background features in pedestrian feature maps. Furthermore, pose-guided visibility scores are estimated for body parts to deal with part occlusion in the proposed AFC module. Extensive experiments with ablation analysis show the effectiveness of our method, and state-of-the-art results are achieved on several public datasets, including Market-1501, CUHK03, CUHK01, SenseReID, CUHK03-NP and DukeMTMC-reID.
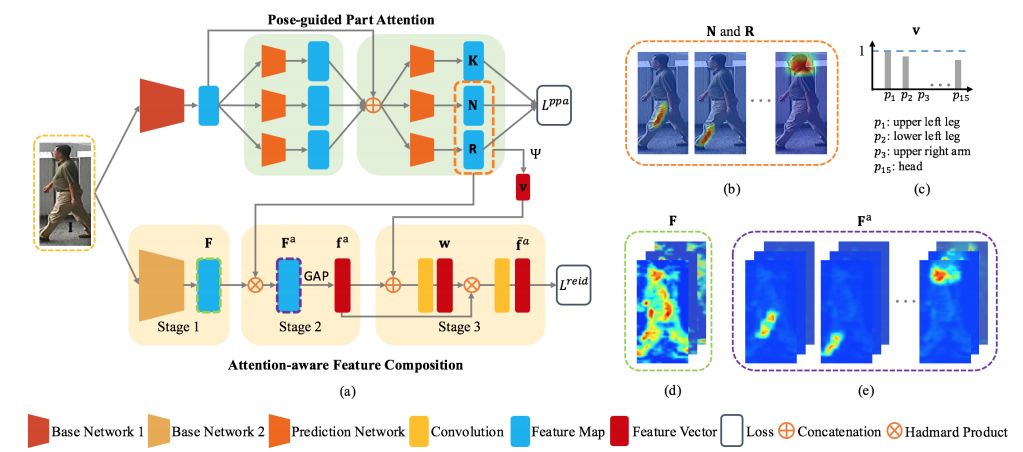
期刊:arXiv, 2018年5月16日
网址:
http://www.zhuanzhi.ai/document/df97e13908e23cc70bdf7ab00f78e032
4.An Evaluation of Deep CNN Baselines for Scene-Independent Person Re-Identification(一个为场景独立的行人再识别深度CNN Baselines的评估)
作者:Paul Marchwica,Michael Jamieson,Parthipan Siva
To be published in 2018 15th Conference on Computer and Robot Vision (CRV)
摘要:In recent years, a variety of proposed methods based on deep convolutional neural networks (CNNs) have improved the state of the art for large-scale person re-identification (ReID). While a large number of optimizations and network improvements have been proposed, there has been relatively little evaluation of the influence of training data and baseline network architecture. In particular, it is usually assumed either that networks are trained on labeled data from the deployment location (scene-dependent), or else adapted with unlabeled data, both of which complicate system deployment. In this paper, we investigate the feasibility of achieving scene-independent person ReID by forming a large composite dataset for training. We present an in-depth comparison of several CNN baseline architectures for both scene-dependent and scene-independent ReID, across a range of training dataset sizes. We show that scene-independent ReID can produce leading-edge results, competitive with unsupervised domain adaption techniques. Finally, we introduce a new dataset for comparing within-camera and across-camera person ReID.
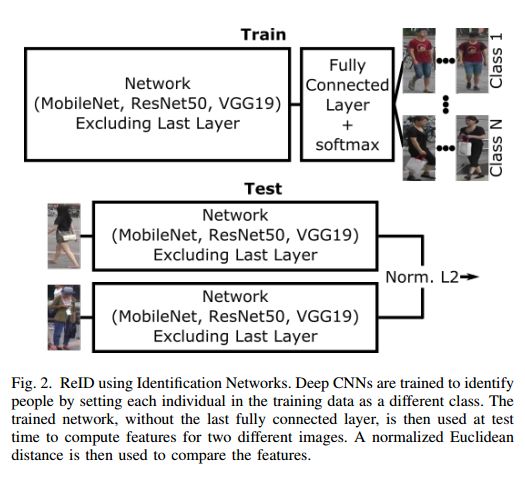
期刊:arXiv, 2018年5月16日
网址:
http://www.zhuanzhi.ai/document/132aec918c3a19e022aaea2bc9b4fc4f
5.Robust and Efficient Graph Correspondence Transfer for Person Re-identification(可靠和有效的图形通信传输以供行人再识别)
作者:Qin Zhou,Heng Fan,Hua Yang,Hang Su,Shibao Zheng,Shuang Wu,Haibin Ling
摘要:Spatial misalignment caused by variations in poses and viewpoints is one of the most critical issues that hinders the performance improvement in existing person re-identification (Re-ID) algorithms. To address this problem, in this paper, we present a robust and efficient graph correspondence transfer (REGCT) approach for explicit spatial alignment in Re-ID. Specifically, we propose to establish the patch-wise correspondences of positive training pairs via graph matching. By exploiting both spatial and visual contexts of human appearance in graph matching, meaningful semantic correspondences can be obtained. To circumvent the cumbersome \emph{on-line} graph matching in testing phase, we propose to transfer the \emph{off-line} learned patch-wise correspondences from the positive training pairs to test pairs. In detail, for each test pair, the training pairs with similar pose-pair configurations are selected as references. The matching patterns (i.e., the correspondences) of the selected references are then utilized to calculate the patch-wise feature distances of this test pair. To enhance the robustness of correspondence transfer, we design a novel pose context descriptor to accurately model human body configurations, and present an approach to measure the similarity between a pair of pose context descriptors. Meanwhile, to improve testing efficiency, we propose a correspondence template ensemble method using the voting mechanism, which significantly reduces the amount of patch-wise matchings involved in distance calculation. With aforementioned strategies, the REGCT model can effectively and efficiently handle the spatial misalignment problem in Re-ID. Extensive experiments on five challenging benchmarks, including VIPeR, Road, PRID450S, 3DPES and CUHK01, evidence the superior performance of REGCT over other state-of-the-art approaches.
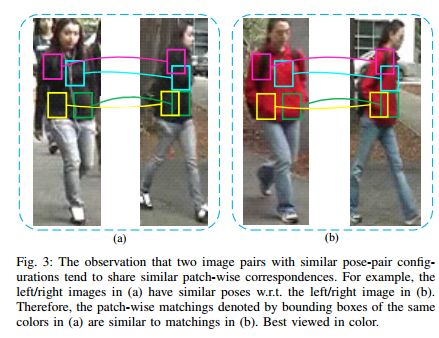
期刊:arXiv, 2018年5月15日
网址:
http://www.zhuanzhi.ai/document/c2dd0a8c2279867f2875b4e47087762f
6.Image-Image Domain Adaptation with Preserved Self-Similarity and Domain-Dissimilarity for Person Re-identification(图像-图像域适应保留自相似性和域差异性的行人再识别)
作者:Weijian Deng,Liang Zheng,Qixiang Ye,Guoliang Kang,Yi Yang,Jianbin Jiao
Accepted in CVPR 2018
机构:University of Technology Sydney,Singapore University of Technology and Design,University of Chinese Academy of Sciences
摘要:Person re-identification (re-ID) models trained on one domain often fail to generalize well to another. In our attempt, we present a "learning via translation" framework. In the baseline, we translate the labeled images from source to target domain in an unsupervised manner. We then train re-ID models with the translated images by supervised methods. Yet, being an essential part of this framework, unsupervised image-image translation suffers from the information loss of source-domain labels during translation. Our motivation is two-fold. First, for each image, the discriminative cues contained in its ID label should be maintained after translation. Second, given the fact that two domains have entirely different persons, a translated image should be dissimilar to any of the target IDs. To this end, we propose to preserve two types of unsupervised similarities, 1) self-similarity of an image before and after translation, and 2) domain-dissimilarity of a translated source image and a target image. Both constraints are implemented in the similarity preserving generative adversarial network (SPGAN) which consists of an Siamese network and a CycleGAN. Through domain adaptation experiment, we show that images generated by SPGAN are more suitable for domain adaptation and yield consistent and competitive re-ID accuracy on two large-scale datasets.
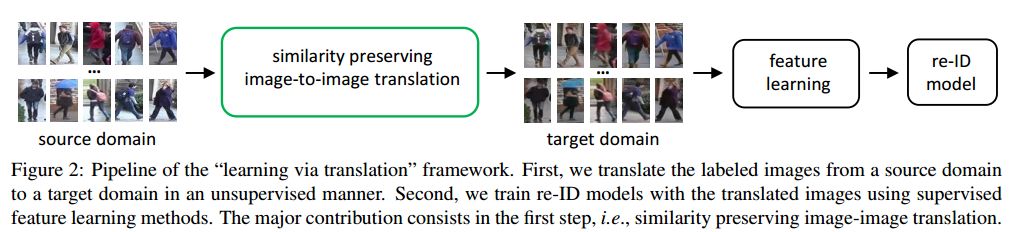
期刊:arXiv, 2018年5月15日
网址:
http://www.zhuanzhi.ai/document/fb974d01e0a9be0b974feb81329d3e27
7.Sharp Attention Network via Adaptive Sampling for Person Re-identification(通过自适应采样进行行人再识别)
作者:Chen Shen,Guo-Jun Qi,Rongxin Jiang,Zhongming Jin,Hongwei Yong,Yaowu Chen,Xian-Sheng Hua
摘要:In this paper, we present novel sharp attention networks by adaptively sampling feature maps from convolutional neural networks (CNNs) for person re-identification (re-ID) problem. Due to the introduction of sampling-based attention models, the proposed approach can adaptively generate sharper attention-aware feature masks. This greatly differs from the gating-based attention mechanism that relies soft gating functions to select the relevant features for person re-ID. In contrast, the proposed sampling-based attention mechanism allows us to effectively trim irrelevant features by enforcing the resultant feature masks to focus on the most discriminative features. It can produce sharper attentions that are more assertive in localizing subtle features relevant to re-identifying people across cameras. For this purpose, a differentiable Gumbel-Softmax sampler is employed to approximate the Bernoulli sampling to train the sharp attention networks. Extensive experimental evaluations demonstrate the superiority of this new sharp attention model for person re-ID over the other state-of-the-art methods on three challenging benchmarks including CUHK03, Market-1501, and DukeMTMC-reID.
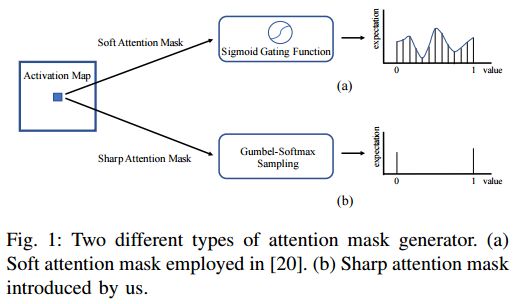
期刊:arXiv, 2018年5月7日
网址:
http://www.zhuanzhi.ai/document/4883f96bead03bad3376e4ea6c788938
8.Human-In-The-Loop Person Re-Identification(人在回路中的行人再识别)
作者:Hanxiao Wang,Shaogang Gong,Xiatian Zhu,Tao Xiang
摘要:Current person re-identification (re-id) methods assume that (1) pre-labelled training data are available for every camera pair, (2) the gallery size for re-identification is moderate. Both assumptions scale poorly to real-world applications when camera network size increases and gallery size becomes large. Human verification of automatic model ranked re-id results becomes inevitable. In this work, a novel human-in-the-loop re-id model based on Human Verification Incremental Learning (HVIL) is formulated which does not require any pre-labelled training data to learn a model, therefore readily scalable to new camera pairs. This HVIL model learns cumulatively from human feedback to provide instant improvement to re-id ranking of each probe on-the-fly enabling the model scalable to large gallery sizes. We further formulate a Regularised Metric Ensemble Learning (RMEL) model to combine a series of incrementally learned HVIL models into a single ensemble model to be used when human feedback becomes unavailable.
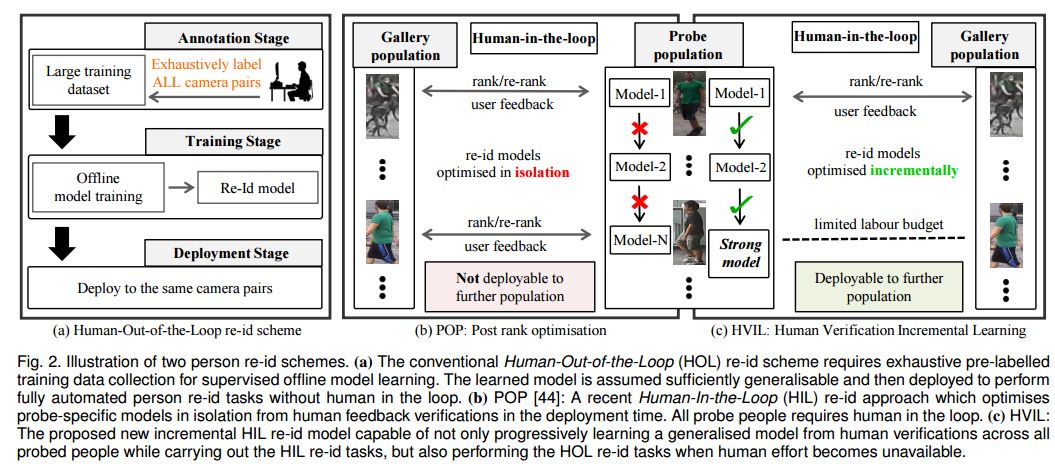
期刊:arXiv, 2018年5月5日
网址:
http://www.zhuanzhi.ai/document/eb5b99c07da9b2fdd1caaa423fa2eda1
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取。欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



