【观点】漫谈推荐系统及数据库技术(二)——分布式数据库技术
【导读】推荐系统和数据库技术,一个是偏机器学习数据挖掘相关的应用,一个是偏系统存储相关的技术,这两者在实际中有很大的应用。上一次专知推出漫谈推荐系统及数据库技术(一),大家反响热烈,特别是很多工业界的人士点赞支持,今天算法工程师宋强继续漫谈自己一些工作的独到见解,欢迎阅读~
跎岁月,年华易逝。再次闲聊下分布式数据库技术,博各位一阅。
▌分布式数据库
相较于传统的单机数据库,分布式数据库有以下的几个特点:
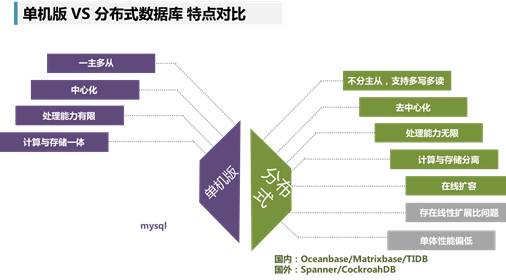
为了更好支撑分布式事务,分布式数据库的研发人员做了很多的方案寻优。
▌概念科普
类似于单机数据库中遇到的高并发业务场景,分布式数据库同样面临着困惑。在并发读写数据库时,读操作可能会不一致的数据(脏读)。为了避免这种情况,需要实现数据库的并发访问控制,最简单的方式就是加锁访问。通俗来说,加锁会将读写操作串行化,所以不会出现不一致的状态。但是,读操作会被写操作阻塞,大幅降低读性能。
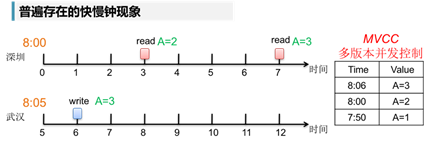
对此,研究人员提出了一种解决方案:MVCC(Multi-Version Concurrent Control),即多版本并发控制。在MVCC协议下,每个读操作会看到一个一致性的snapshot,并且可以实现非阻塞的读。MVCC允许数据具有多个版本,这个版本可以是时间戳或者是全局递增的事务ID,在同一个时间点,不同的事务看到的数据是不同的。当存储的历史版本数据足够多时,可以使用GC(Garbage Collector)对其进行清理。
▌提出问题
在分布式环境中,普遍存在这么一个症结:快慢钟现象。举个例子:张三在武汉时间8:06分给李四汇款,汇款成功后,通知李四去查账。李四在深圳时间8:03分查不到,需要在深圳时间8:07分才查到了帐。这违背了可重复读的原则!(为了方便举例,假设武汉的网络时间比深圳的网络时间快了5s)
▌用💰能解决的方案
原子钟这个概念并不新颖,早在很早以前的航天航空领域,它就已经存在了。火箭卫星之所以能够出色的完成入轨和定点目标,一个重要因素就是它们拥有极致精确的时间。那是一种精度可以达到万分之一秒,几万年都不会出差错的可怕存在。
Spanner是Google的全球级的分布式数据库 (Globally-Distributed Database) 。它的扩展性达到了令人咋舌的全球级,可以扩展到数百万的机器,数已百计的数据中心,上万亿的行。除了夸张的扩展性之外,他还能同时通过同步复制和多版本来满足外部一致性,具备HA高可用性。同时冲破CAP的枷锁,在三者之间达到了完美平衡。就在几个月前,Spanner终于release并支持商用了。
互联网精贵(精英+贵族)如Google,在解决该问题上自然底气实足。他们肯花高额的费用在原子钟上,并不是因为不关心算法,而是明白当前算法本身也存在一定的局限性,也许不能完美的解决问题。一如DeepLearning在手机终端的应用。为了解决存储难题,算法尝试对filter参数量化压缩学习。实际上,硬件上的性能提升较之算法上性能提升,效果更加明显。当然,二者本质上是相辅相成的。
但是,即便诚如原子钟,也会有偏差,只不过这个偏差是可预期的(10ms)。那么,我们不禁会发问,“有些短事务,比如只含有一条SQL指令,它需要的执行时间可能小于10ms,即10ms内还是可能造成快慢钟现象发生,那该怎么办?”
别急,Google的研发人员提供了一个非常简单的解决方案。Spanner规定,一个新事务获取的时间点为X,它真正启动的时间为:X + 10ms。通俗的话说,在本地的新事务启动时,它先获取一下当前本地的时间戳X,再等待10ms,确保其他节点的时间不早于X后,才开始执行。因为原子钟保证了任意两个节点间的网络时钟偏差不超过10ms,所以事务的先后顺序得以保证。
▌靠数学推理解决的方案
下面给大家介绍下HLC混合逻辑时钟
HLC先验概念
作者认为:数据库的事务的执行标准应该是按照时序进行的,而不是单纯的时间。数据库中存在关联的(因果关系的)事务才需要严格区分先后次序。数据库中不存在关联的事务间的执行顺序可以随意。在HLC的观念里,彻底摒弃了时钟的概念,而是以时序代替。
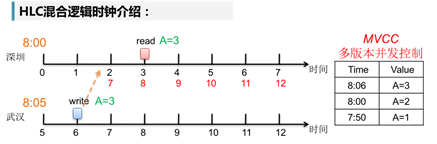
同样是上述的快慢钟问题,HLC对存在关联的事务进行了时序修正。深圳Read事务发生在武汉Write事务之后。按照HLC的观念,原本的慢钟(深圳)的时序点被修正为关联节点(快钟(武汉))的Write事务时序点+1。所以,当李四收到张三汇款成功的消息后,在本地查账即刻能获得最新结果。
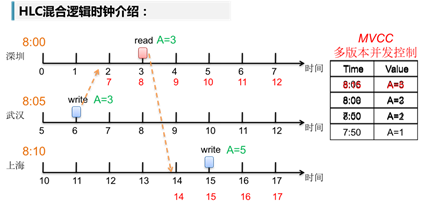
同理,上海与深圳的事务间也存在关联关系,所以上海的时序也需要调整,但是由于上海的时钟本来就快于深圳的时钟,所以调整的结果为E上海=max(E深圳+1,Ep上海+1,T上海)= T上海。(其中,E表示事务发生的时序点,Ep表示该节点此刻记录的最近一次事务发生的时序点(每个节点都会记录最近一次事务发生的时序点),T表示本地的网络时钟)。
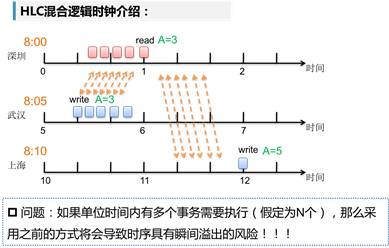
除此之外,该方案还存在一个严重的问题,如上图所述,当两个节点间的关联事务频繁发生时,时序变量将可能溢出。具体而言,假定任意一个单位时间内,允许发生的事务最大个数为K。则根据上述理论,在单位时间内首尾两个事务的时序差<= K。当关联事务频繁发生时,不同单元时间内的时序差将会累加,导致时序变量急剧上涨,溢出风险亟待解决。
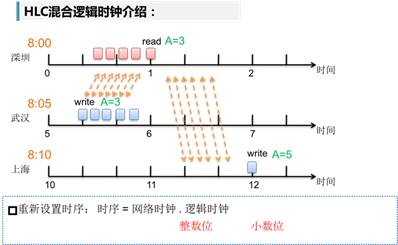
HLC引入了逻辑时钟的概念,将时序设计成网络时钟.逻辑时钟的组合。前者看成是整数位,后者看成是小数位。即E=En+El,其中,En表示整数部分,El表示小数部分。这种方式能有效地解决时序溢出的问题。具体实现方法是:
If (max(En深圳+1,Epn上海+1,T上海)==T上海)
then E上海=T上海.0 //即此刻逻辑时钟归零
else //取En深圳,Epn上海间的较大者,并启用小数位El。
then If (max(En深圳,Epn上海)==En深圳)
then E上海= En深圳+ (El深圳+1个单位El)
else then E上海= Epn上海+ (Epl上海+1个单位El)
end
end
简而言之,就是将单位时间内的关联事务先后次序,通过逻辑时钟来排序;不同单位时间内的关联事务,通过网络时钟约束,避免溢出风险。(具体的数学证明可以详看参考论文~~,笔者从头到尾膜拜地推导了一遍,不过实在懒得敲公式了)
聪明如你,这里也许已经看出点端倪:HLC是基于网络通信质量的算法。
应用实践
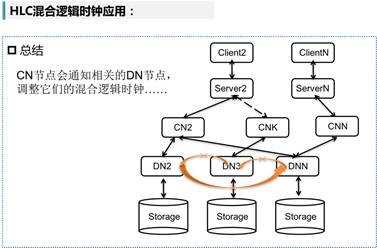
以CocroachDB为例,在分布式数据库中,结构大致如图所示,Server是服务器、CN和DN都属于解析节点、Storage属于底层存储。其中,CN和DN分别表示协调者节点和数据节点,它们往往分布在不同的地方,拥有各自的本地网络时钟。对于一个事务而言,数据库根据一定规则随机选择一个解析节点为CN。(与该事务实际相关的节点为它的DN节点)CN节点在协调过程中时,当收到DN节点传来的事务执行成功消息后,会通知其他相关的DN节点,调整它们的HLC时序。这样,新事务到来时,获取的时间戳就是最新的时序了。
下次如有机会,跟大家分享下:Oceanbase郁白老师的“两阶段提交的工程实践”。
▌参考文献
1.“LogicalPhysical Clocks and Consistent Snapshots in Globally Distributed Databases”
OPODIS 2014: Principlesof Distributed Systems pp 17-32
2. Google Spanner:
http://research.google.com/archive/spanner.html
作者简介:
宋强,本科毕业于中山大学,硕士毕业于中科院自动化所,曾在华为从事分布式数据库研发工作,现在一家金融机构工作。
特注:
本篇由宋强投稿专知发送,欢迎各位行业技术专家投稿专知,分享您的技术与观点!
Email:zhuanzhi2017@outlook.com; 或者扫描以下小助手联系!
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域25个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!

点击“阅读原文”,使用专知!
展开全文



