如何用机器学习处理二元分类任务?

图像是猫还是狗?情感是正还是负?贷还是不贷?这些问题,该如何使用合适的机器学习模型来解决呢?
问题
暑假后,又有一批研究生要开题了。这几天陆续收到他们发来的研究计划大纲。
其中好几个,打算使用机器学习做分类。
但是,从他们的文字描述来看,不少人对机器学习进行分类的方法,还是一知半解。
考虑到之前分享机器学习处理分类问题的文章,往往针对具体的任务案例。似乎对分类问题的整体步骤与注意事项,还没有详细论述过。于是我决定写这篇文章,帮他们梳理一下。
他们和你一样,也是我专栏的读者。
如果你对机器学习感兴趣,并且实际遇到了分类任务,那我解答他们遇到的一些疑问,可能对于你同样有用。
所以,我把这篇文章也分享给你。希望能有一些帮助。
监督
监督式机器学习任务很常见。主要模型,是分类与回归。
就分类问题而言,二元分类是典型应用。
例如决策辅助,你利用结构化数据,判定可否贷款给某个客户;
例如情感分析,你需要通过一段文字,来区分情感的正负极性;
例如图像识别,你得识别出图片是猫,还是狗。
今天咱们就先介绍一下,二元分类,这个最为简单和常见的机器学习应用场景。
注意要做分类,你首先得有合适的数据。
什么是合适的数据呢?
这得回到我们对机器学习的大类划分。
分类任务,属于监督式学习。
监督式学习的特点,是要有标记。
例如给你1000张猫的图片,1000张狗的图片,扔在一起,没有打标记。这样你是做不了分类的。
虽然你可以让机器学习不同图片的特征,让它把图片区分开。
但是这叫做聚类,属于非监督学习。
天知道,机器是根据什么特征把图片分开的。
你想得到的结果,是猫放在一类,狗放在另一类。
但是机器抓取特征的时候,也许更喜欢按照颜色区分。
结果白猫白狗放在了一个类别,黄猫黄狗放在了另一个类别。跟你想要的结果大相径庭。
如果你对非监督学习感兴趣,可以参考《如何用Python从海量文本抽取主题?》一文。
所以,要做分类,就必须有标记才行。
但是标记不是天上掉下来的。
大部分情况下,都是人打上去的。
标记
打标记(Labeling),是个专业化而繁复的劳动。
你可以自己打,可以找人帮忙,也可以利用众包的力量。
例如亚马逊的“土耳其机器人”(Amazon Mechanical Turk)项目。
别被名字唬住,这不是什么人工智能项目,而是普通人可以利用业余时间赚外快的机会。
你可以帮别人做任务拿佣金。任务中很重要的一部分,就是人工分类,打标记。

因此如果你有原始数据,但是没有标记,就可以把数据扔上去。
说明需求,花钱找人帮你标记。
类似的服务,国内也有很多。
建议找知名度比较高的平台来做,这样标记的质量会比较靠谱。
如果你还是在校学生,可能会觉得这样的服务价格太贵,个人难以负担。
没关系。假如你的研究是有基金资助项目的一部分,可以正大光明地找导师申请数据采集费用。
但若你的研究属于个人行为,就得另想办法了。
不少学生选择的办法,是依靠团队支持。
例如找低年级的研究生帮忙标记。
人家帮了忙,让你发表了论文,顺利毕业。你总得请大家吃一顿好吃的,是吧?
学习
有了标记以后,你就能够实施监督学习,做分类了。
这里我们顺带说一下,什么叫做“机器学习”。
这个名字很时髦。
其实它做的事情,叫做“基于统计的信息表征”。
先说信息表征(representation)。
你的输入,可能是结构化的数据,例如某个人的各项生理指标;可能是非结构化数据,例如文本、声音甚至是图像,但是最终机器学习模型看到的东西,都是一系列的数字。
这些数字,以某种形式排布。
可能是零维的,叫做标量(scalar);
可能是一维的,叫做向量(vector);
可能是二维的,叫做矩阵(Matrice);
可能是高维的,叫做张量(Tensor)。

但是,不论输入的数据,究竟有多少维度,如果你的目标是做二元分类,那么经过一个或简单、或复杂的模型,最后的输出,一定是个标量数字。
你的模型,会设置一个阈值。例如0.5。
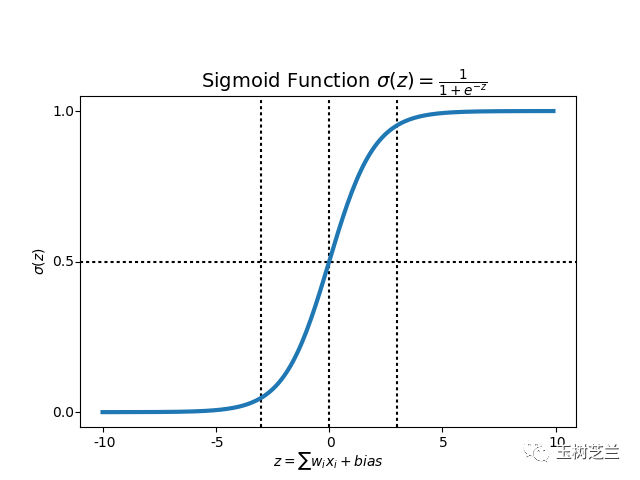
超出这个数字的,被分类到一处。
反之,被分类到另一处。
任务完成。
那么模型究竟在做什么呢?
它的任务,就是把输入的数据,表征成最终的这个标量。
打个不恰当的比方,就如同高考。
每一个考生,其实都是独特的。
每个人都有自己的家庭,自己的梦想,自己的经历,自己的故事。
但是高考这个模型,不可能完整准确表征上述全部细节。
它简单地以考生们的试卷答题纸作为输入,以一个最终的总成绩作为输出。
然后,划定一个叫做录取分数线的东西,作为阈值(判定标准)。
达到或超出了,录取。
否则,不录取。
这个分数,就是高考模型对每个考生的信息表征。
所谓分类模型的优劣,其实就是看模型是否真的达到了预期的分类效果。
什么是好的分类效果?
大学想招收的人,录取了(True Positive, TP);
大学不想招收的人,没被录取(True Negative, TN)。
什么是不好的分类效果?
大学想招收的人,没能被录取(False Negative, FN);
大学不想招收的人,被录取了(False Positive, FP)。
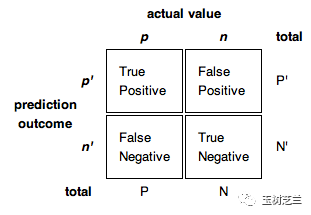
好的模型,需要尽力增大 TP 和 TN 的比例,降低 FN 和 FP 的比例。
评判的标准,视你的类别数据平衡而定。
数据平衡,例如1000张猫照片,1000张狗照片,可以使用 ROC AUC。
数据不平衡,例如有1000张猫的照片,却只有100张狗的照片,可以使用 Precision 和 Recall ,或者二者相结合的 F1 score。
因为有这样明确的评估标准,所以二元分类模型不能满足于“分了类”,而需要向着“更好的分类结果”前进。
办法就是利用统计结果,不断改进模型的表征方法。
所以,模型的参数需要不断迭代。
恢复高考后的40年,高考的形式、科目、分值、大纲……包括加分政策等,一直都在变化。这也可以看作是一种模型的迭代。
“表征”+“统计”+“迭代”,这基本上就是所谓的“学习”。
结构化
看到这里,希望你的头脑里已经有了机器学习做二元分类问题的技术路线概貌。
下面咱们针对不同的数据类型,说说具体的操作形式和注意事项。
先说最简单的结构化数据。
例如《贷还是不贷:如何用Python和机器学习帮你决策?》一文中,我们见到过的客户信息。
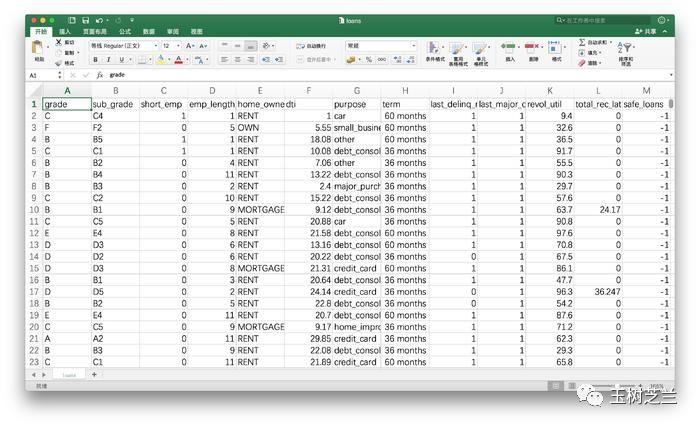
处理这样的数据,你首先需要关注数据的规模。
如果数据量大,你可以使用复杂的模型。
如果数据量小,你就得使用简单的模型。
为什么呢?
因为越复杂的模型,表征的信息就越多。
表征的信息多,未必是好事。
因为你抓住的,既有可能是信号,也有可能是噪声。
如果表征信息多,可是学习过的数据不多,它可能就会对不该记住的信息,形成记忆。
在机器学习领域,这是最恐怖的结果——过拟合(overfitting)。
翻译成人话,就是见过的数据,分类效果极好;没见过的数据,表现很糟糕。
举一个我自己的例子。
我上学前班后没多久,我妈就被请了家长。
因为我汉语拼音默写,得了0分。
老师嘴上说,是怀疑我不认真完成功课;心里想的,八成是这孩子智商余额不足。
其实我挺努力的。
每天老师让回家默写的内容,都默了。
但是我默写的时候,是严格按照“a o e i u ……”的顺序默的。
因为每天都这样默写,所以我记住的东西,不是每个读音对应的符号,而是它们出现的顺序。
结果上课的时候,老师是这样念的“a b c d e ……”
我毫无悬念没跟下来。
我的悲剧,源于自己的心智模型,实际上只反复学习了一条数据“a o e i u ……”。每天重复,导致过拟合,符号出现在顺序中,才能辨识和记忆。
因此,见到了新的组合方式,就无能为力了。
看,过拟合很糟糕吧。
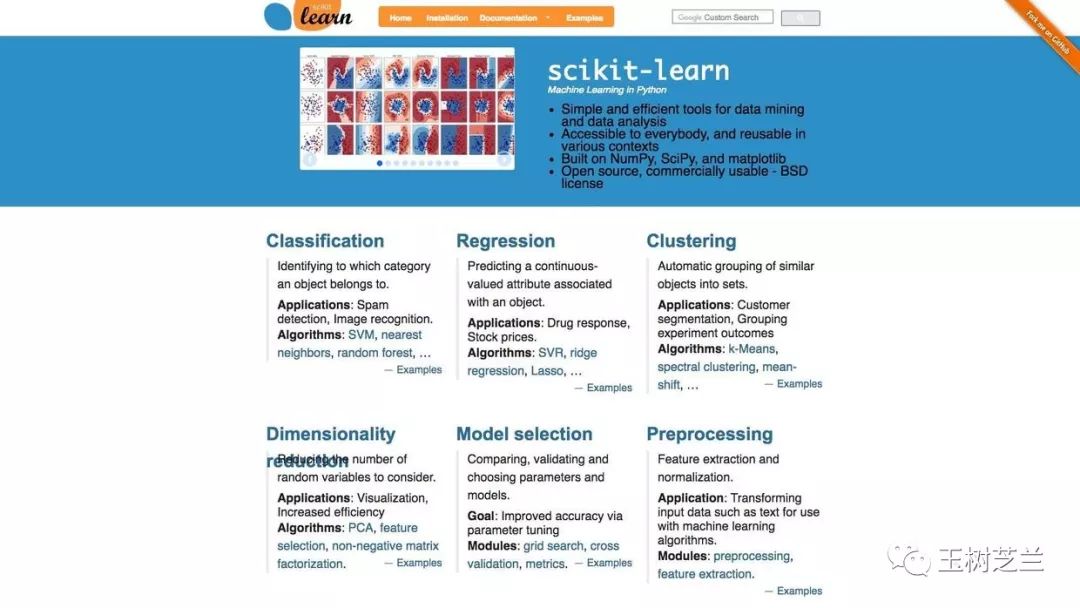
确定了模型的复杂度以后,你依然需要根据特征多少,选择合适的分类模型。
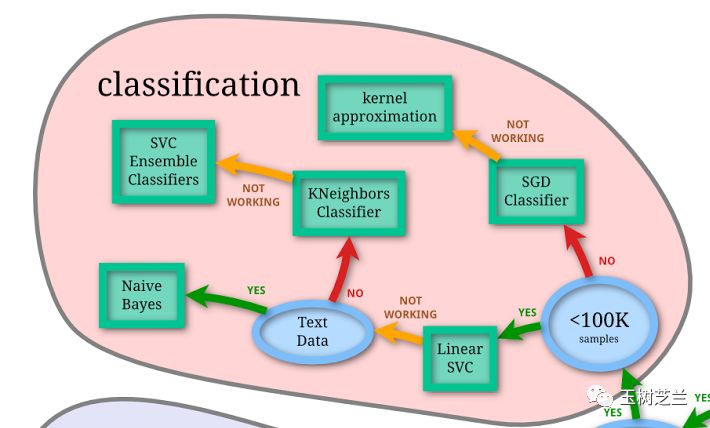
上图来自于 Scikit-learn ,我截取了其中“分类”模型部分,你可以做参考。
注意模型的效果,实际上是有等级划分的。
例如根据 Kaggle 数据科学竞赛多年的实践结果来看,Gradient Boosting Machine 优于随机森林,随机森林优于决策树。
这么比有些不厚道,因为三者的出现,也是有时间顺序的。
让爷爷跟孙子一起赛跑,公平性有待商榷。
因此,你不宜在论文中,将不同的分类模型,分别调包跑一遍,然后来个横向对比大测评。
许多情况下,这是没有意义的。
虽然显得工作量很大。
但假如你发现在你自己的数据集上面,决策树的效果就是明显优于 Gradient Boosting Machine ,那你倒是很有必要通过论文做出汇报。
尽管大部分审稿人都会认为,一定是你算错了。
另一个需要注意的事项,是特征工程(feature engineering)。
什么叫特征工程呢?
就是手动挑选特征,或者对特征(组合)进行转化。
例如《如何用Python和深度神经网络锁定即将流失的客户?》一文中,我们就对特征进行了甄别。其中三列数据,我们直接剔除掉了:
RowNumber:行号,这个肯定没用,删除
CustomerID:用户编号,这个是顺序发放的,删除
Surname:用户姓名,对流失没有影响,删除
正式学习之前,你需要把手头掌握的全部数据分成3类:
训练集
验证集
测试集
我在给期刊审稿的时候,发现许多使用机器学习模型的作者,无论中外,都似乎不能精确理解这些集合的用途。
训练集让你的模型学习,如何利用当前的超参数(例如神经网络的层数、每一层的神经元个数等)组合,尽可能把表征拟合标记结果。
就像那个笑话说的一样:
Machine Learning in a Nutshell:
Interviewer: what's you biggest strength?
Me: I'm a quick learner.
Interviewer: What's 11*11?
Me: 65.
Interviewer: Not even close. It's 121.
Me: It's 121.
而验证集的存在,就是为了让你对比不同的超参数选择,哪一组更适合当前任务。它必须用训练集没有用过的数据。
验证集帮你选择了合适的超参数后,它的历史任务也就结束了。
这时候,你可以把训练集、验证集合并在一起,用最终确定的超参数组合进行训练,获得最优模型。
这个模型表现怎么样?
你当然需要其他的数据来评判。这就是为什么你还要划分出另外的测试集。
图像
François Chollet 在自己的书中举过一个例子,我觉得很有启发,一并分享给你。
假如你看到了这样的原始数据:
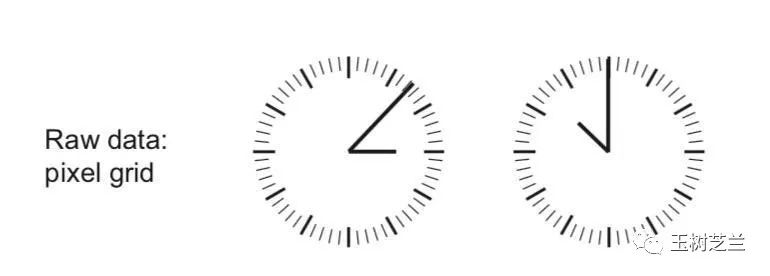
你该怎么做分类?
有的同学一看是图像,立刻决定,上卷积神经网络!
别忙,想想看,真的需要“直接上大锤”吗?
别的不说,那一圈的刻度,就对我们的模型毫无意义。
你可以利用特征工程,将其表达为这样的坐标点:

你看,这样处理之后,你立刻就拥有了结构化数据。
注意这个转换过程,并不需要人工完成,完全可以自动化。
但是举一反三的你,估计已经想到了“更好的”解决方案:

对,这样一来,表达钟表时间的数据,就从原先的4个数字,变成了只需要2个。
一个本来需要用复杂模型解决的问题,就是因为简单的特征工程转化,复杂度和难度显著下降。
其实,曾经人们进行图片分类,全都得用特征工程的方法。
那个时候,图片分类问题极其繁琐、成本很高,而且效果还不理想。
手动提取的特征,也往往不具备良好的可扩展性和可迁移性。
于是,深度卷积神经网络就登场了。
如果你的图片数据量足够多的话,你就可以采用“端到端”的学习方式。
所谓“端到端”,是指不进行任何的特征工程,构造一个规模合适的神经网络模型,扔图片进去就可以了。
但是,现实往往是残酷的。
你最需要了解的,是图片不够多的时候,怎么办。
这时候,很容易出现过拟合。
因为深度神经网络,属于典型的复杂模型。
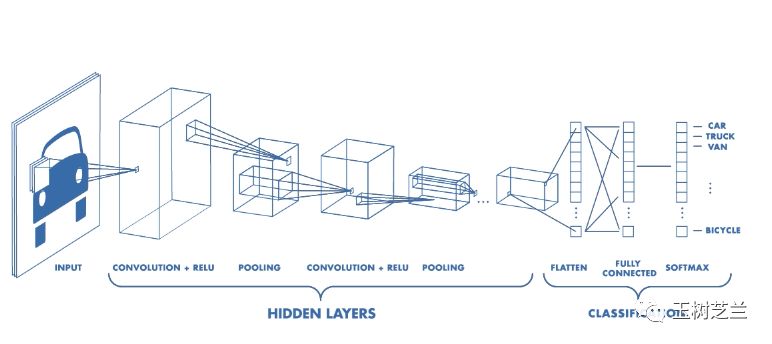
这个时候,可以尝试以下几个不同的方法:
首先,如果有可能,搜集更多的带标注图片。这是最简单的办法,如果成本可以接受,你应该优先采用。
其次,使用数据增强(Data Augmentation)。名字听起来很强大,其实无非是把原始的数据进行镜像、剪裁、旋转、扭曲等处理。这样“新的”图片与老图片的标注肯定还是一样的。但是图片内容发生的变化,可以有效防止模型记住过多噪声。

第三,使用迁移学习。
所谓迁移学习,就是利用别人训练好的模型,保留其中从输入开始的大多数层次(冻结保留其层次数量、神经元数量等网络结构,以及权重数值),只把最后的几层敲掉,换上自己的几层神经网络,对小规模数据做训练。
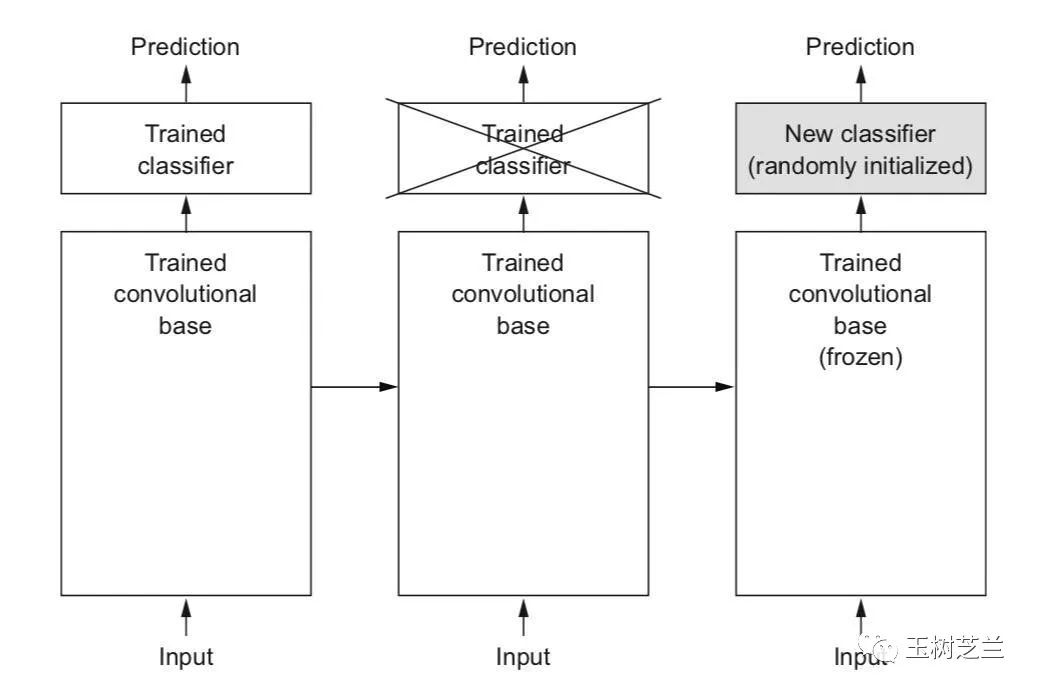
上图同样来自于 François Chollet 的著作。
这种做法,用时少,成本低,效果还特别好。如果重新训练,图片数少,就很容易过拟合。但是用了迁移学习,过拟合的可能性就大大降低。
其原理其实很容易理解。
卷积神经网络的层次,越是靠近输入位置,表达的特征就越是细节;越到后面,就越宏观。
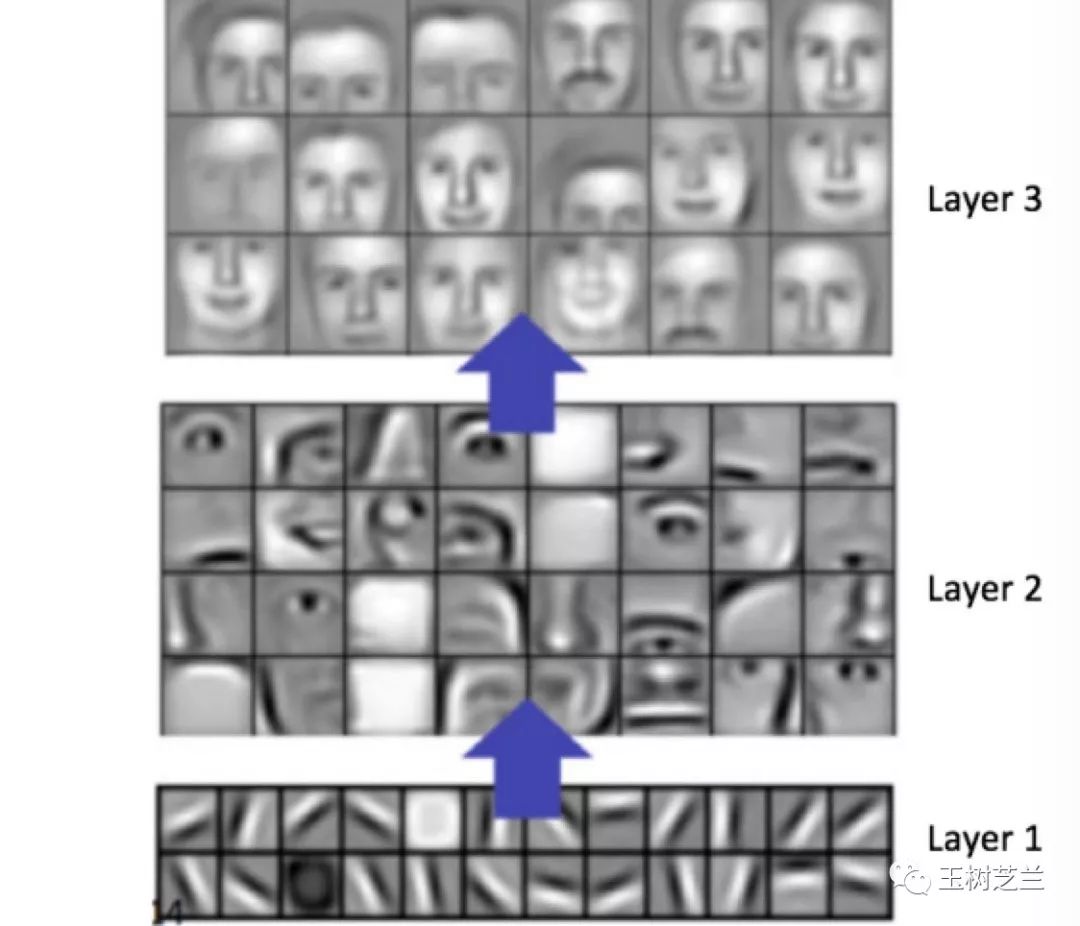
识别猫和狗,要从形状边缘开始;识别哆啦a梦和瓦力,也一样要从形状边缘开始。因此模型的底层,可以被拿来使用。
你训练的,只是最后几层表征方式。结构简单,当然也就不需要这么多数据了。
第四,引入 Dropout, Regularization 和 Early Stopping 等常规方法。注意这些方法不仅适用于图像数据。
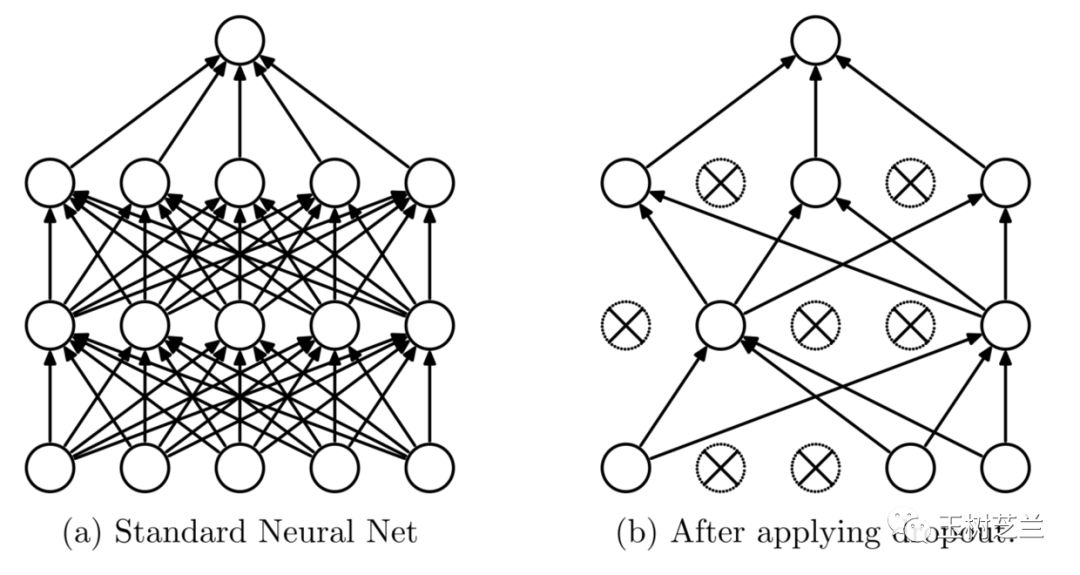
以 Dropout 为例。假如一个模型因为复杂,所以记住了很多噪声,那么训练的时候,每次都随机将一定比例的神经元“扔掉”(设置权重为0),那么模型的复杂度降低。而且因为随机,又比降低层数与神经元个数的固化模型适用性更高。
文本
前面说过了,机器不认得文本,只认得数字。
所以,要对文本做二元分类,你需要把文本转换成为数字。
这个过程,叫做向量化。
向量化的方式,有好几种。大致上可以分成两类:
第一类,是无意义转换。也就是转换的数字,只是个编号而已,本身并不携带其他语义信息。
这一类问题,我们在《如何用Python和机器学习训练中文文本情感分类模型?》中,已经非常详细地介绍过了。
你需要做的,包括分词(如果是中文)、向量化、去除停用词,然后丢进一个分类模型(例如朴素贝叶斯,或者神经网络),直接获取结果,加以评估。
但是,这个过程,显然有大量的语义和顺序信息被丢弃了。
第二类,是有意义转换。这时候,每个语言单元(例如单词)转换出来的数字,往往是个高维向量。
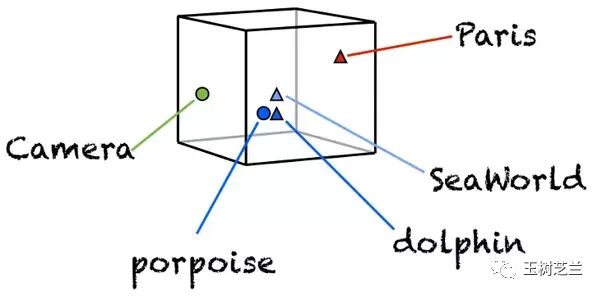
这个向量,你可以自己通过训练来产生。
但是这种训练,需要对海量语料进行建模。
建模的过程,成本很高,占用庞大存储空间,运算量极大。
因此更常见的做法,是使用别人通过大规模语料训练后的结果。也就是我们曾经介绍过的词嵌入预训练模型。
具体内容,请参见《如何用Python处理自然语言?(Spacy与Word Embedding)》和《如何用 Python 和 gensim 调用中文词嵌入预训练模型?》。
注意如果你有多个预训练模型可以选择,那么尽量选择与你要解决任务的文本更为接近的那种。
毕竟预训练模型来自于统计结果。两种差别很大的语料,词语在上下文中的含义也会有显著差异,导致语义的刻画不够准确。
如果你需要在分类的过程中,同时考虑语义和语言单元顺序等信息,那么你可以这样做:
第一步,利用词嵌入预训练模型,把你的输入语句转化为张量,这解决了词语的语义问题;
第二步,采用一维卷积神经网络(Conv1D)模型,或者循环神经网络模型(例如 LSTM),构造分类器。
注意这一步中,虽然两种不同的神经网络结构,都可以应用。但是一般而言,处理二元分类问题,前者(卷积神经网络)表现更好。
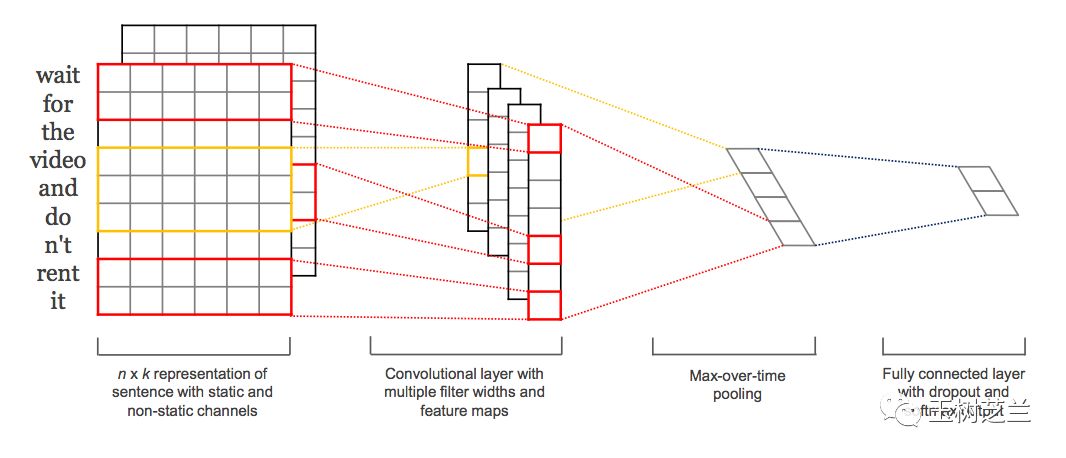
因为卷积神经网络实际上已经充分考虑了词语的顺序问题;而循环神经网络用在此处,有些“大炮轰蚊子”。很容易发生过拟合,导致模型效果下降。
实施
如果你了解二元分类问题的整体流程,并且做好了模型的选择,那么实际的机器学习过程,是很简单的。
对于大部分的普通机器学习问题,你都可以用 Scikit-learn 来调用模型。
注意其实每一个模型,都有参数设置的需要。但是对于很多问题来说,默认初始参数,就能带来很不错的运行结果。
Scikit-learn 虽好,可惜一直不能很好支持深度学习任务。
因而不论是图像还是文本分类问题,你都需要挑选一个好用的深度学习框架。
注意,目前主流的深度学习框架,很难说有好坏之分。
毕竟,在深度学习领域如此动荡激烈的竞争环境中,“坏”框架(例如功能不完善、性能低下)会很快被淘汰出局。
然而,从易用性上来说,框架之间确实有很大区别。
易用到了一种极致,便是苹果的 Turi Create 。
从《如何用Python和深度神经网络识别图像?》和《如何用Python和深度神经网络寻找近似图片?》这两篇文章中,你应该有体会,Turi Create 在图像识别和相似度查询问题上,已经易用到你自己都不知道究竟发生了什么,任务就解决了。
但是,如果你需要对于神经网络的结构进行深度设置,那么 Turi Create 就显得不大够用了。
毕竟,其开发的目标,是给苹果移动设备开发者赋能,让他们更好地使用深度学习技术。

对于更通用的科研和实践深度学习任务,我推荐你用 Keras 。
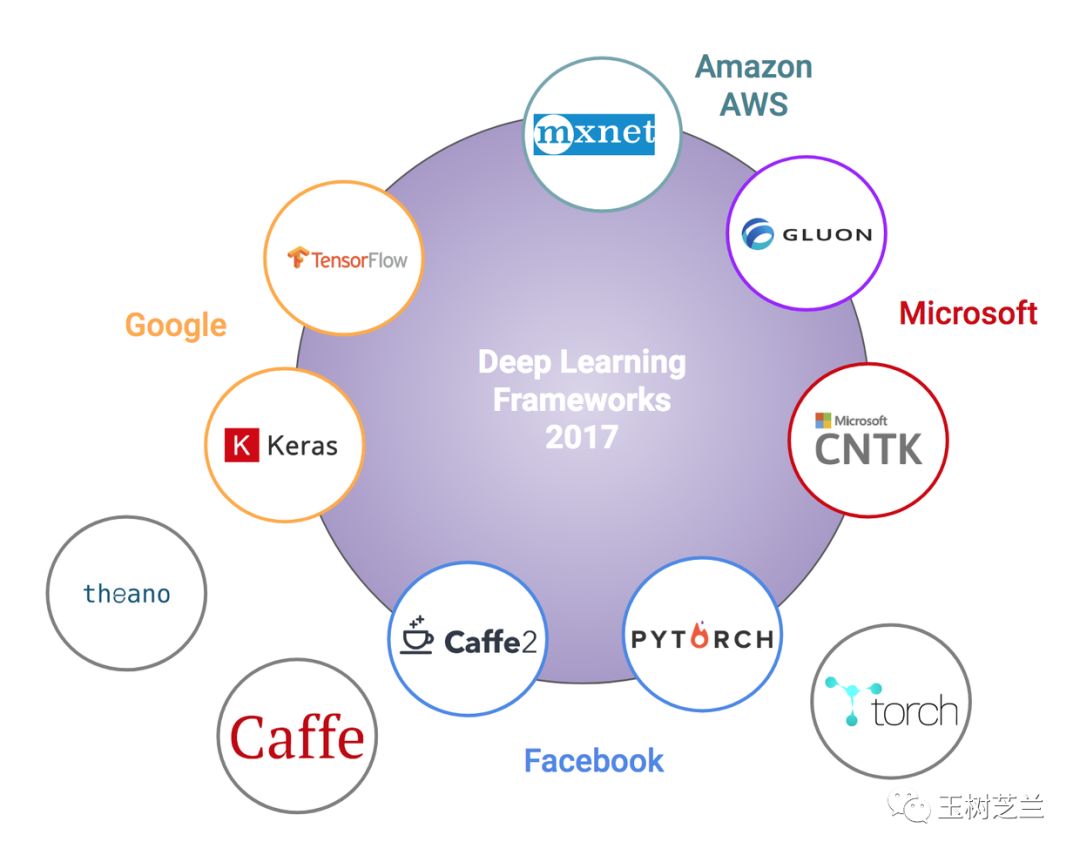
它已经可以把 Theano, Tensorflow 和 CNTK 作为后端。
对比上面那张深度学习框架全家福,你应该看到,Keras 覆盖了 Google 和 微软自家框架,几乎占领了深度学习框架界的半壁江山。
照这势头发展下去,一统江湖也说不定哦。
为什么 Keras 那么厉害?
因为简单易学。
简单易学到,显著拉低了深度学习的门槛。
就连 Tensorflow 的主力开发人员 Josh Gordon,也已经认为你根本没必要去学习曾经的 Tensorflow 繁复语法了。
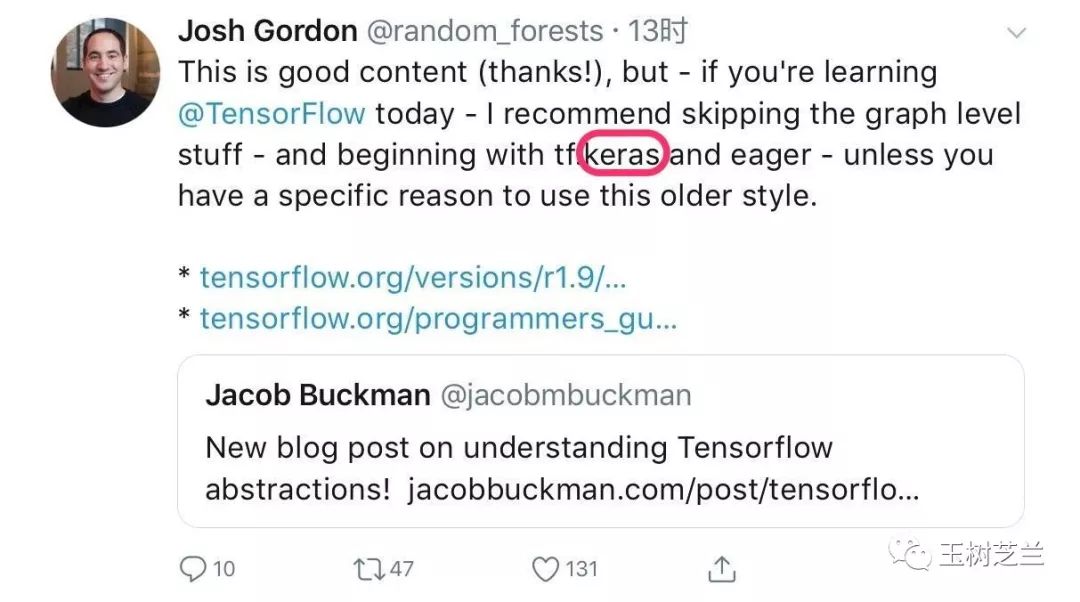
直接学 Keras ,用它完成任务,结束。
另外,使用深度学习,你可能需要 GPU 硬件设备的支持。这东西比较贵。建议你采用租用的方式。
《如何用云端 GPU 为你的 Python 深度学习加速?》提到的 FloydHub,租赁一个小时,大概需要1美元左右。注册账号就赠送你2个小时;

至于《如何免费云端运行Python深度学习框架?》中提到的 Google Colab ,就更慷慨了——到目前为止,一直是免费试用。
喜欢请点赞。还可以微信关注和置顶我的公众号“玉树芝兰”(nkwangshuyi)。
如果你对数据科学感兴趣,不妨阅读我的系列教程索引贴《如何高效入门数据科学?》,里面还有更多的有趣问题及解法。
答疑社区在这里:

展开全文



