【论文推荐】最新十篇机器翻译相关论文—自适应机器翻译综述、结构化预测、双向神经机器翻译、图编解码模型、英日机器翻、上下文感知
【导读】专知内容组既昨天推出九篇机器翻译(Machine Translation)相关论文,今天又推出最新十篇机器翻译相关论文,欢迎查看!
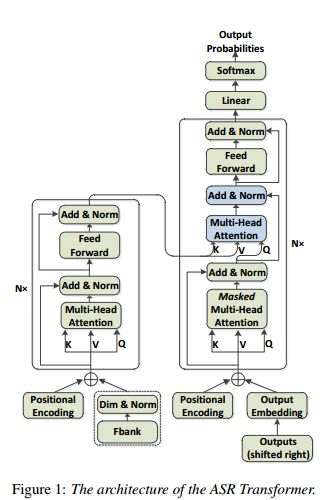
10.Syllable-Based Sequence-to-Sequence Speech Recognition with the Transformer in Mandarin Chinese(普通话中基于音节的序列-序列语音识别)
作者:
机构:University of Chinese Academy of Sciences
摘要:Sequence-to-sequence attention-based models have recently shown very promising results on automatic speech recognition (ASR) tasks, which integrate an acoustic, pronunciation and language model into a single neural network. In these models, the Transformer, a new sequence-to-sequence attention-based model relying entirely on self-attention without using RNNs or convolutions, achieves a new single-model state-of-the-art BLEU on neural machine translation (NMT) tasks. Since the outstanding performance of the Transformer, we extend it to speech and concentrate on it as the basic architecture of sequence-to-sequence attention-based model on Mandarin Chinese ASR tasks. Furthermore, we investigate a comparison between syllable based model and context-independent phoneme (CI-phoneme) based model with the Transformer in Mandarin Chinese. Additionally, a greedy cascading decoder with the Transformer is proposed for mapping CI-phoneme sequences and syllable sequences into word sequences. Experiments on HKUST datasets demonstrate that syllable based model with the Transformer performs better than CI-phoneme based counterpart, and achieves a character error rate (CER) of \emph{$28.77\%$}, which is competitive to the state-of-the-art CER of $28.0\%$ by the joint CTC-attention based encoder-decoder network.
期刊:arXiv, 2018年6月4日
网址:
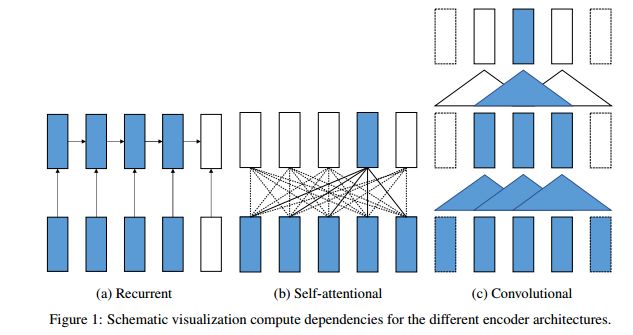
11.Sockeye: A Toolkit for Neural Machine Translation(Sockeye:用于神经机器翻译的工具箱)
作者:
摘要:We describe Sockeye (version 1.12), an open-source sequence-to-sequence toolkit for Neural Machine Translation (NMT). Sockeye is a production-ready framework for training and applying models as well as an experimental platform for researchers. Written in Python and built on MXNet, the toolkit offers scalable training and inference for the three most prominent encoder-decoder architectures: attentional recurrent neural networks, self-attentional transformers, and fully convolutional networks. Sockeye also supports a wide range of optimizers, normalization and regularization techniques, and inference improvements from current NMT literature. Users can easily run standard training recipes, explore different model settings, and incorporate new ideas. In this paper, we highlight Sockeye's features and benchmark it against other NMT toolkits on two language arcs from the 2017 Conference on Machine Translation (WMT): English-German and Latvian-English. We report competitive BLEU scores across all three architectures, including an overall best score for Sockeye's transformer implementation. To facilitate further comparison, we release all system outputs and training scripts used in our experiments. The Sockeye toolkit is free software released under the Apache 2.0 license.
期刊:arXiv, 2018年6月1日
网址:
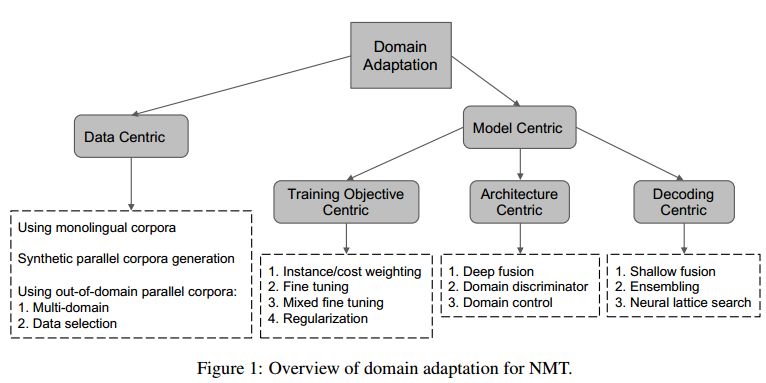
12.A Survey of Domain Adaptation for Neural Machine Translation (神经机器翻译域自适应的综述)
作者:Chenhui Chu,Rui Wang
COLING 2018
机构:Osaka University
摘要:Neural machine translation (NMT) is a deep learning based approach for machine translation, which yields the state-of-the-art translation performance in scenarios where large-scale parallel corpora are available. Although the high-quality and domain-specific translation is crucial in the real world, domain-specific corpora are usually scarce or nonexistent, and thus vanilla NMT performs poorly in such scenarios. Domain adaptation that leverages both out-of-domain parallel corpora as well as monolingual corpora for in-domain translation, is very important for domain-specific translation. In this paper, we give a comprehensive survey of the state-of-the-art domain adaptation techniques for NMT.
期刊:arXiv, 2018年6月1日
网址:
http://www.zhuanzhi.ai/document/2fcc4b9db4faa4c2d65235969c5e2a00
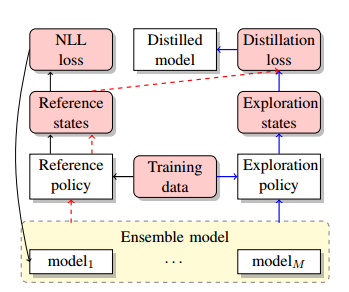
13.Distilling Knowledge for Search-based Structured Prediction (提炼基于搜索的结构化预测的知识)
作者:Yijia Liu,Wanxiang Che,Huaipeng Zhao,Bing Qin,Ting Liu
To appear at ACL 2018
摘要:Many natural language processing tasks can be modeled into structured prediction and solved as a search problem. In this paper, we distill an ensemble of multiple models trained with different initialization into a single model. In addition to learning to match the ensemble's probability output on the reference states, we also use the ensemble to explore the search space and learn from the encountered states in the exploration. Experimental results on two typical search-based structured prediction tasks -- transition-based dependency parsing and neural machine translation show that distillation can effectively improve the single model's performance and the final model achieves improvements of 1.32 in LAS and 2.65 in BLEU score on these two tasks respectively over strong baselines and it outperforms the greedy structured prediction models in previous literatures.
期刊:arXiv, 2018年5月29日
网址:
http://www.zhuanzhi.ai/document/4432c8f9db5de053b6936c5ca7738c6e
14.Bi-Directional Neural Machine Translation with Synthetic Parallel Data (双向神经机器翻译与合成并行数据)
作者:Xing Niu,Michael Denkowski,Marine Carpuat
Accepted at the 2nd Workshop on Neural Machine Translation and Generation (WNMT 2018)
机构:University of Maryland
摘要:Despite impressive progress in high-resource settings, Neural Machine Translation (NMT) still struggles in low-resource and out-of-domain scenarios, often failing to match the quality of phrase-based translation. We propose a novel technique that combines back-translation and multilingual NMT to improve performance in these difficult cases. Our technique trains a single model for both directions of a language pair, allowing us to back-translate source or target monolingual data without requiring an auxiliary model. We then continue training on the augmented parallel data, enabling a cycle of improvement for a single model that can incorporate any source, target, or parallel data to improve both translation directions. As a byproduct, these models can reduce training and deployment costs significantly compared to uni-directional models. Extensive experiments show that our technique outperforms standard back-translation in low-resource scenarios, improves quality on cross-domain tasks, and effectively reduces costs across the board.
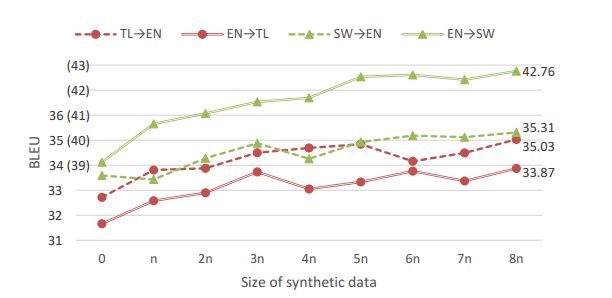
期刊:arXiv, 2018年5月29日
网址:
http://www.zhuanzhi.ai/document/06afeb45d9fc334f67848252ff512a0d
15.Graph-based Filtering of Out-of-Vocabulary Words for Encoder-Decoder Models((基于图的编码-解码模型用于词汇表外单词过滤)
作者:Satoru Katsumata,Yukio Matsumura,Hayahide Yamagishi,Mamoru Komachi
2018 ACL Student Research Workshop
机构:Tokyo Metropolitan University
摘要:Encoder-decoder models typically only employ words that are frequently used in the training corpus to reduce the computational costs and exclude noise. However, this vocabulary set may still include words that interfere with learning in encoder-decoder models. This paper proposes a method for selecting more suitable words for learning encoders by utilizing not only frequency, but also co-occurrence information, which we capture using the HITS algorithm. We apply our proposed method to two tasks: machine translation and grammatical error correction. For Japanese-to-English translation, this method achieves a BLEU score that is 0.56 points more than that of a baseline. It also outperforms the baseline method for English grammatical error correction, with an F0.5-measure that is 1.48 points higher.
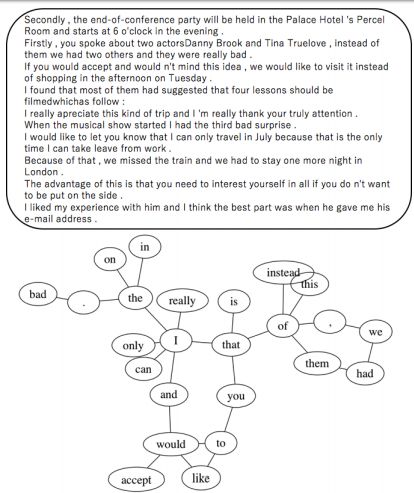
期刊:arXiv, 2018年5月29日
网址:
http://www.zhuanzhi.ai/document/6cfea9920eb3b1dcb5bebb3bcf6b5534
16.Inducing Grammars with and for Neural Machine Translation (用于神经机器翻译的归纳语法)
作者:Ke Tran,Yonatan Bisk
accepted at NMT workshop (WNMT 2018)
机构:University of Amsterdam,University of Washington
摘要:Machine translation systems require semantic knowledge and grammatical understanding. Neural machine translation (NMT) systems often assume this information is captured by an attention mechanism and a decoder that ensures fluency. Recent work has shown that incorporating explicit syntax alleviates the burden of modeling both types of knowledge. However, requiring parses is expensive and does not explore the question of what syntax a model needs during translation. To address both of these issues we introduce a model that simultaneously translates while inducing dependency trees. In this way, we leverage the benefits of structure while investigating what syntax NMT must induce to maximize performance. We show that our dependency trees are 1. language pair dependent and 2. improve translation quality.
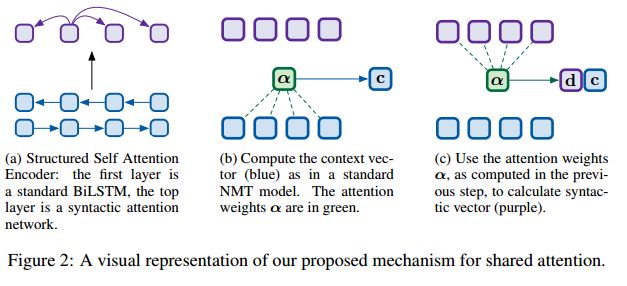
期刊:arXiv, 2018年5月28日
网址:
http://www.zhuanzhi.ai/document/c9a3205a7c29820bbc408e01dd0c967a
17.A Stochastic Decoder for Neural Machine Translation (神经机器翻译的随机解码器)
作者:Philip Schulz,Wilker Aziz,Trevor Cohn
Accepted at ACL 2018
机构:University of Amsterdam,University of Melbourne
摘要:The process of translation is ambiguous, in that there are typically many valid trans- lations for a given sentence. This gives rise to significant variation in parallel cor- pora, however, most current models of machine translation do not account for this variation, instead treating the prob- lem as a deterministic process. To this end, we present a deep generative model of machine translation which incorporates a chain of latent variables, in order to ac- count for local lexical and syntactic varia- tion in parallel corpora. We provide an in- depth analysis of the pitfalls encountered in variational inference for training deep generative models. Experiments on sev- eral different language pairs demonstrate that the model consistently improves over strong baselines.
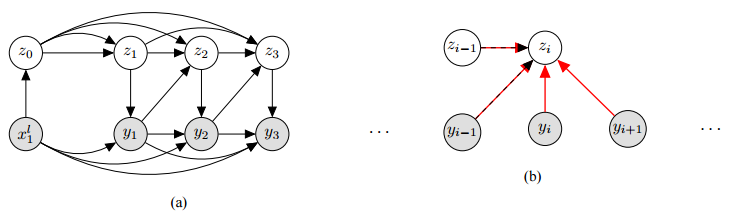
期刊:arXiv, 2018年5月28日
网址:
http://www.zhuanzhi.ai/document/a965bbe38aa4ebeda78d17196e0afd71
18.Recursive Neural Network Based Preordering for English-to-Japanese Machine Translation(基于递归神经网络的英日机器翻译预处理)
作者:Yuki Kawara,Chenhui Chu,Yuki Arase
ACL-SRW 2018
机构:Osaka University
摘要:The word order between source and target languages significantly influences the translation quality in machine translation. Preordering can effectively address this problem. Previous preordering methods require a manual feature design, making language dependent design costly. In this paper, we propose a preordering method with a recursive neural network that learns features from raw inputs. Experiments show that the proposed method achieves comparable gain in translation quality to the state-of-the-art method but without a manual feature design.
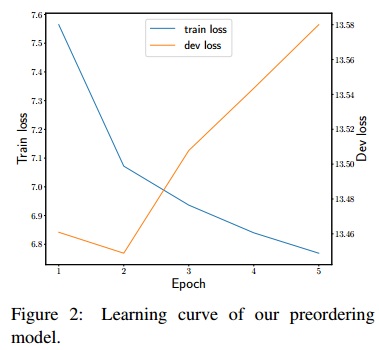
期刊:arXiv, 2018年5月25日
网址:
http://www.zhuanzhi.ai/document/47872f75ac6c27428ed637fbd32ddb06
19.Context-Aware Neural Machine Translation Learns Anaphora Resolution (上下文感知神经机器翻译学习回指解析)
作者:Elena Voita,Pavel Serdyukov,Rico Sennrich,Ivan Titov
ACL 2018
机构:University of Amsterdam,University of Edinburgh
摘要:Standard machine translation systems process sentences in isolation and hence ignore extra-sentential information, even though extended context can both prevent mistakes in ambiguous cases and improve translation coherence. We introduce a context-aware neural machine translation model designed in such way that the flow of information from the extended context to the translation model can be controlled and analyzed. We experiment with an English-Russian subtitles dataset, and observe that much of what is captured by our model deals with improving pronoun translation. We measure correspondences between induced attention distributions and coreference relations and observe that the model implicitly captures anaphora. It is consistent with gains for sentences where pronouns need to be gendered in translation. Beside improvements in anaphoric cases, the model also improves in overall BLEU, both over its context-agnostic version (+0.7) and over simple concatenation of the context and source sentences (+0.6).
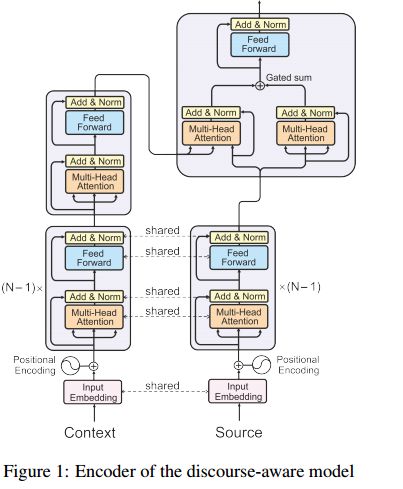
期刊:arXiv, 2018年5月25日
网址:
http://www.zhuanzhi.ai/document/b66946497037fac56b357d0fe8d62843
-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



