【论文推荐】最新6篇行人重识别相关论文—深度空间特征重构、生成对抗网络、图像生成、系列实战、图像-图像域自适应方法、行人检索
【导读】专知内容组整理了最近六篇行人重识别(Person Re-identification)相关文章,为大家进行介绍,欢迎查看!
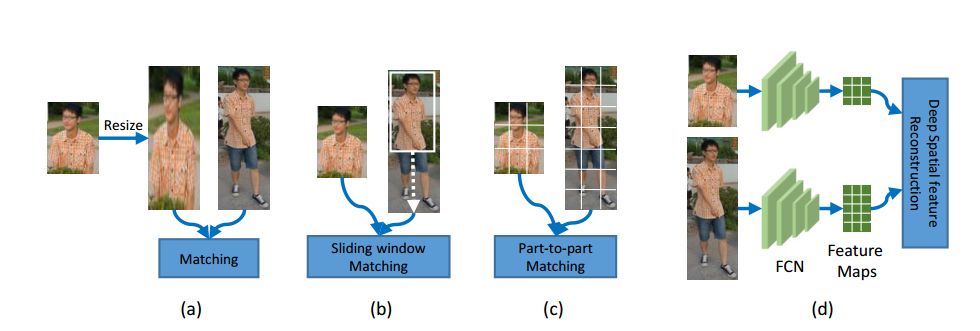
1. Deep Spatial Feature Reconstruction for Partial Person Re-identification: Alignment-Free Approach(基于深度空间特征重构的部分行人重识别:对齐无关方法)
作者:Lingxiao He,Jian Liang,Haiqing Li,Zhenan Sun
摘要:Partial person re-identification (re-id) is a challenging problem, where only some partial observations (images) of persons are available for matching. However, few studies have offered a flexible solution of how to identify an arbitrary patch of a person image. In this paper, we propose a fast and accurate matching method to address this problem. The proposed method leverages Fully Convolutional Network (FCN) to generate certain-sized spatial feature maps such that pixel-level features are consistent. To match a pair of person images of different sizes, hence, a novel method called Deep Spatial feature Reconstruction (DSR) is further developed to avoid explicit alignment. Specifically, DSR exploits the reconstructing error from popular dictionary learning models to calculate the similarity between different spatial feature maps. In that way, we expect that the proposed FCN can decrease the similarity of coupled images from different persons and increase that of coupled images from the same person. Experimental results on two partial person datasets demonstrate the efficiency and effectiveness of the proposed method in comparison with several state-of-the-art partial person re-id approaches. Additionally, it achieves competitive results on a benchmark person dataset Market1501 with the Rank-1 accuracy being 83.58%.
期刊:arXiv, 2018年1月3日
网址:
http://www.zhuanzhi.ai/document/ce5f291e3f7f25f88b3858e6418a0e5e
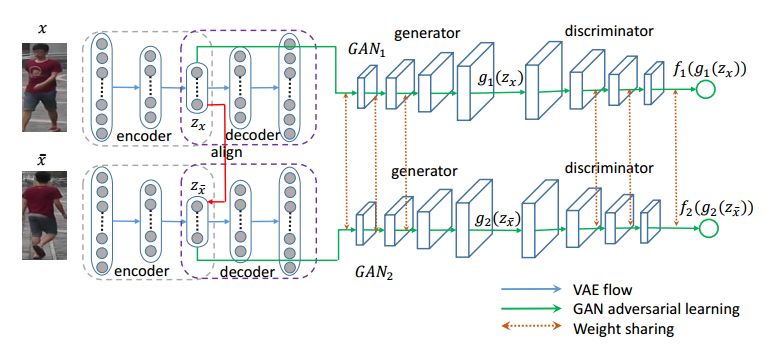
2. Crossing Generative Adversarial Networks for Cross-View Person Re-identification(基于交叉生成对抗网络的跨视角行人重识别)
作者:Chengyuan Zhang,Lin Wu,Yang Wang
摘要:Person re-identification (\textit{re-id}) refers to matching pedestrians across disjoint yet non-overlapping camera views. The most effective way to match these pedestrians undertaking significant visual variations is to seek reliably invariant features that can describe the person of interest faithfully. Most of existing methods are presented in a supervised manner to produce discriminative features by relying on labeled paired images in correspondence. However, annotating pair-wise images is prohibitively expensive in labors, and thus not practical in large-scale networked cameras. Moreover, seeking comparable representations across camera views demands a flexible model to address the complex distributions of images. In this work, we study the co-occurrence statistic patterns between pairs of images, and propose to crossing Generative Adversarial Network (Cross-GAN) for learning a joint distribution for cross-image representations in a unsupervised manner. Given a pair of person images, the proposed model consists of the variational auto-encoder to encode the pair into respective latent variables, a proposed cross-view alignment to reduce the view disparity, and an adversarial layer to seek the joint distribution of latent representations. The learned latent representations are well-aligned to reflect the co-occurrence patterns of paired images. We empirically evaluate the proposed model against challenging datasets, and our results show the importance of joint invariant features in improving matching rates of person re-id with comparison to semi/unsupervised state-of-the-arts.
期刊:arXiv, 2018年1月4日
网址:
http://www.zhuanzhi.ai/document/0e2662b2c79513467409c0b4ad1aeb6f
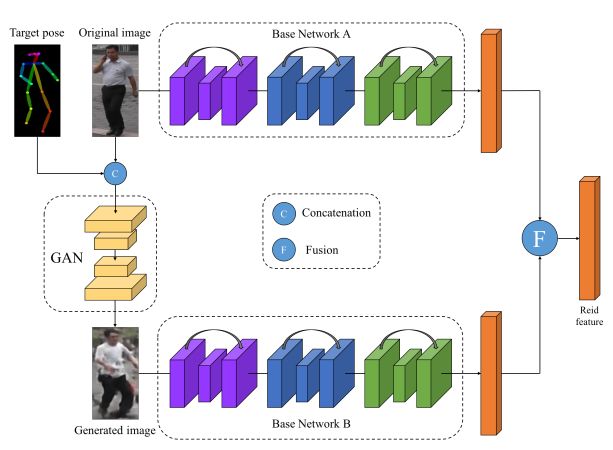
3. Pose-Normalized Image Generation for Person Re-identification(基于姿态归一化图像生成的行人重识别)
作者:Xuelin Qian,Yanwei Fu,Wenxuan Wang,Tao Xiang,Yang Wu,Yu-Gang Jiang,Xiangyang Xue
摘要:Person Re-identification (re-id) faces two major challenges: the lack of cross-view paired training data and learning discriminative identity-sensitive and view-invariant features in the presence of large pose variations. In this work, we address both problems by proposing a novel deep person image generation model for synthesizing realistic person images conditional on pose. The model is based on a generative adversarial network (GAN) and used specifically for pose normalization in re-id, thus termed pose-normalization GAN (PN-GAN). With the synthesized images, we can learn a new type of deep re-id feature free of the influence of pose variations. We show that this feature is strong on its own and highly complementary to features learned with the original images. Importantly, we now have a model that generalizes to any new re-id dataset without the need for collecting any training data for model fine-tuning, thus making a deep re-id model truly scalable. Extensive experiments on five benchmarks show that our model outperforms the state-of-the-art models, often significantly. In particular, the features learned on Market-1501 can achieve a Rank-1 accuracy of 68.67% on VIPeR without any model fine-tuning, beating almost all existing models fine-tuned on the dataset.
期刊:arXiv, 2018年1月18日
网址:
http://www.zhuanzhi.ai/document/7ef1e354b55bce36833394c4270ca649
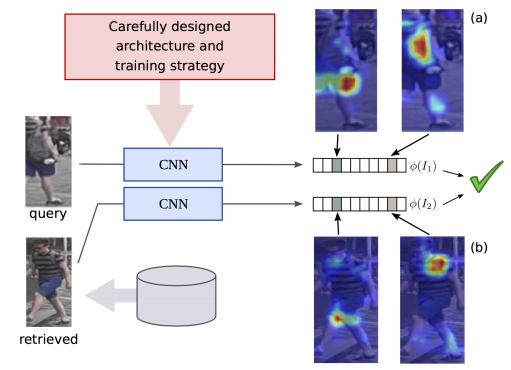
4. Re-ID done right: towards good practices for person re-identification(Re-ID正确:行人重识别的系列好的实战)
作者:Jon Almazan,Bojana Gajic,Naila Murray,Diane Larlus
摘要:Training a deep architecture using a ranking loss has become standard for the person re-identification task. Increasingly, these deep architectures include additional components that leverage part detections, attribute predictions, pose estimators and other auxiliary information, in order to more effectively localize and align discriminative image regions. In this paper we adopt a different approach and carefully design each component of a simple deep architecture and, critically, the strategy for training it effectively for person re-identification. We extensively evaluate each design choice, leading to a list of good practices for person re-identification. By following these practices, our approach outperforms the state of the art, including more complex methods with auxiliary components, by large margins on four benchmark datasets. We also provide a qualitative analysis of our trained representation which indicates that, while compact, it is able to capture information from localized and discriminative regions, in a manner akin to an implicit attention mechanism.
期刊:arXiv, 2018年1月17日
网址:
http://www.zhuanzhi.ai/document/074aefb3ce8c22258d68c3e721e21e8a
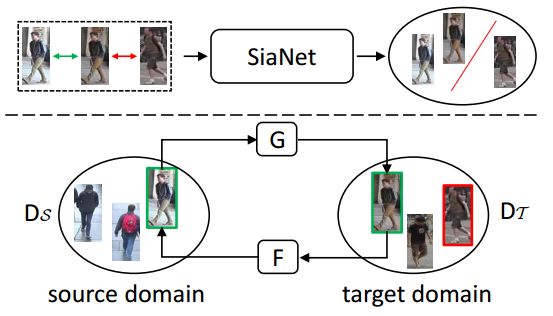
5. Image-Image Domain Adaptation with Preserved Self-Similarity and Domain-Dissimilarity for Person Re-identification(行人重识别:基于保留自相似性和域差异性的图像-图像域自适应方法)
作者:Weijian Deng,Liang Zheng,Guoliang Kang,Yi Yang,Qixiang Ye,Jianbin Jiao
摘要:Person re-identification (re-ID) models trained on one domain often fail to generalize well to another. In our attempt, we present a "learning via translation" framework. In the baseline, we translate the labeled images from source to target domain in an unsupervised manner. We then train re-ID models with the translated images by supervised methods. Yet, being an essential part of this framework, unsupervised image-image translation suffers from the information loss of source-domain labels during translation. Our motivation is two-fold. First, for each image, the discriminative cues contained in its ID label should be maintained after translation. Second, given the fact that two domains have entirely different persons, a translated image should be dissimilar to any of the target IDs. To this end, we propose to preserve two types of unsupervised similarities, 1) self-similarity of an image before and after translation, and 2) domain-dissimilarity of a translated source image and a target image. Both constraints are implemented in the similarity preserving generative adversarial network (SPGAN) which consists of a Siamese network and a CycleGAN. Through domain adaptation experiment, we show that images generated by SPGAN are more suitable for domain adaptation and yield consistent and competitive re-ID accuracy on two large-scale datasets.
期刊:arXiv, 2018年1月10日
网址:
http://www.zhuanzhi.ai/document/74e3e0fcbd023984f6b19961ce3d0bcf
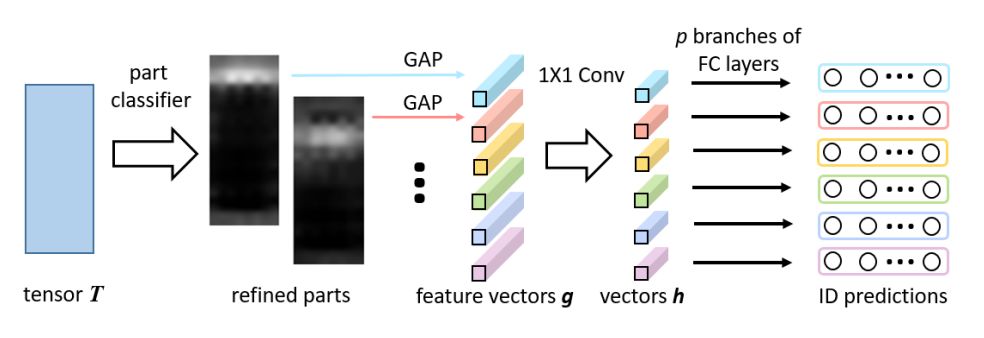
6. Beyond Part Models: Person Retrieval with Refined Part Pooling (超越Part模型:基于精练的部分池化层的行人检索方法)
作者:Yifan Sun,Liang Zheng,Yi Yang,Qi Tian,Shengjin Wang
摘要:Employing part-level features for pedestrian image description offers fine-grained information and has been verified as beneficial for person retrieval in very recent literature. A prerequisite of part discovery is that each part should be well located. Instead of using external cues, e.g., pose estimation, to directly locate parts, this paper lays emphasis on the content consistency within each part. Specifically, we target at learning discriminative part-informed features for person retrieval and make two contributions. (i) A network named Part-based Convolutional Baseline (PCB). Given an image input, it outputs a convolutional descriptor consisting of several part-level features. With a uniform partition strategy, PCB achieves competitive results with the state-of-the-art methods, proving itself as a strong convolutional baseline for person retrieval. (ii) A refined part pooling (RPP) method. Uniform partition inevitably incurs outliers in each part, which are in fact more similar to other parts. RPP re-assigns these outliers to the parts they are closest to, resulting in refined parts with enhanced within-part consistency. Experiment confirms that RPP allows PCB to gain another round of performance boost. For instance, on the Market-1501 dataset, we achieve (77.4+4.2)% mAP and (92.3+1.5)% rank-1 accuracy, surpassing the state of the art by a large margin.
期刊:arXiv, 2018年1月9日
网址:
http://www.zhuanzhi.ai/document/356b4c440d1d569a17a6467fc3ca5341
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



