【干货】首次使用分层强化学习框架进行视频描述生成,王威廉组最新工作
点击上方“专知”关注获取专业AI知识!

【导读】加州大学-圣塔芭芭拉计算王威廉组最新工作Video Captioning via Hierarchical Reinforcement Learning ,首次提出分层强化学习方法来加强不同等级的视频描述,通过分层深度强化学习,在文本生成上可以做到语言表达更加连贯,语义更加丰富,语法更加结构化。达在MSR-VTT数据集上达到了的最佳结果,并且提出了新的Charades Caption数据集。文章中指出,未来将计划注意力机制(Attention),以提升提出的层次强化学习(HRL)框架。作者相信,提出的方法的结果可以通过使用不同类型的特征,如C3D特征,光流等进一步改善。同时,作者将在其他相似的序列生成任务(如视频/文档摘要)中探索提出的HRL框架。
▌作者
Xin Wang:加州大学-圣塔芭芭拉博士生,导师Yuan-Fang Wang和William Yang Wang
Wenhu Chen, 加州大学-圣塔芭芭拉博士生
https://www.linkedin.com/in/wenhu-chen-ab59317b/
Yuan-Fang Wang 加州大学-圣塔芭芭拉教授
http://www.cs.ucsb.edu/~yfwang/
William Yang Wang(王威廉) 加州大学-圣塔芭芭拉计算机科学系助理教授
http://www.cs.ucsb.edu/~william/
微博:http://weibo.com/u/1657470871/
论文:Video Captioning via Hierarchical Reinforcement Learning

▌摘要
视频描述是根据视频中的动作自动生成的文本描述的任务。尽管之前的工作(例如,序列到序列模型)已经在短视频的粗略摘要描述中获得有希望的结果,但是要对包含许多细节动作的视频生成详细描述,仍然是非常具有挑战性的任务。本文旨在通过提出一种新的基于分层强化学习框架的视频描述方法来解决这个问题,其中高级管理模块学习设计子目标,而低级工作模块识别原始动作以实现子目标。通过这个组合框架从不同级别的增强视频描述效果,我们的方法明显优于其他所有基准方法,并新引入了一个用于细粒度视频描述研究的大规模数据集。此外,我们在MSR-VTT数据集上达到最佳结果。
▌详细内容
对于大多数人来说,观看简短的视频并用文本描述视频中发生的事情是一个容易的任务。对于机器来说,从视频的像素中提取含义并生成自然的文本描述是一个非常具有挑战性的任务。然而,由于智能视频监控对视觉疲劳人群的辅助等方面的广泛应用,视频描述最近引起了计算机视觉领域越来越多的关注。与旨在描述静态场景的图像描述技术不同,为了联合生成多个描述文本片段(参见图1),视频字幕需要理解一系列相关场景,因此视频描述更具挑战性。

图1:视频字幕示例。第一行是在MSR-VTT数据集[40]的示例,其中视频是用三个标题来概括的。最后一行是Charades数据集[30]上的示例,它由几个相关的人类活动组成,用复杂结构的多重长句来描述。
目前的视频描述任务主要可以分为两个系列:单句生成[40,19]和段落生成[26]。单句生成倾向于将整个视频抽象为简单和高级的描述性句子,而段落生成倾向于理解视频中更详细的活动,并生成多个描述句子。然而,段落生成问题经常会根据视频时间间隔被分成多个单句生成场景。有些研究采用动作检测技术来预测时间间隔[12],但没有明显改善视频描述的结果。
在很多实际情况下,人类的活动过于复杂,不能用简短的句子来描述,而且如果没有对语言语境很好地的理解,时间间隔就难以被提前预测。例如,在图1的底部例子中,总共有五个动作:坐在床上、把一台笔记本电脑放进一个包里(这两个动作是同时发生的)、然后站起来、把包放在一个肩膀上、走出房间(顺序发生的动作)。这种细粒度的文本生成需要一个精细且具有表达性的机制来捕捉视频时间上的动态内容,并将其与自然语言中的语义表示联系起来。
为了解决这个问题,本文提出了一个“分而治之”的解决方案,它首先将一个长文本分成许多小文本段(例如不同的段如图1所示用不同的颜色表示),然后采用序列模型处理每个部分。本文建议引导模型逐个生成句子,而不是强制模型生成整个序列。利用高层次的序列模型设计每个片段的上下文,低层次序列模型用来逐个生成单个片段。
在本文中,作者提出了一个新的分层强化学习(HRL)框架来实现这个两级机制。文本和视频上下文可以被看作是强化学习环境。提出的框架是一个完全可微分的深度神经网络(见图2),包括(1)高层次的序列模型管理模块(Manager),以较低的时间分辨率设置目标;(2)低层次序列模型工作模块(Worker)根据Manager中的目标在每个时间步选择基本操作;(3)用内部评价模块(Internal Critic)决定一个目标是否完成。更具体地说,通过从环境和完成的目标中挖掘上下文,Manager为新的片段发出新的目标,并且Worker接受该目标并通过依次产生单词来生成序列。此外,Internal Critic是用来评估目前生成的文本段是否完成。
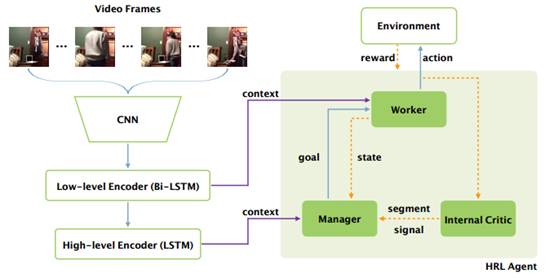
图2:HRL视频描述框架概述。
此外,本文为Manager和Worker都设置了基于视频特征的注意模块(3.2节),以在内部引入层次性注意力,以便Manager将注意力集中在更广泛的时间动态,而Worker的注意力被缩小到当前目标条件下的局部动态。同时,由于词典通常包含数千个单词,导致了一个难以搜索的大的动作空间。使用分层强化学习,Manager的目标可以在很大程度上限制Worker的搜索空间,提高单词预测的准确性。
文章指出这是用分层强化学习方法来加强不同等级的视频描述的首次工作。本文的主要贡献有四个:
提出了一个分层强化学习框架,以有效地学习视频描述的语义动态性。
制定了一个新颖的、可选择的训练方法,可用随机和确定策略梯度进行训练。
通过对原始Charades数据集进行预处理,引入了一个新的大规模细粒度视频描述数据集Charades Captions,并验证了该方法的有效性。
在MSR-VTT数据集上进一步评估我们的方法,即使在单一类型的特征上进行训练也能达到最先进的结果。
▌模型简介
本文提出的HRL框架采用的通用的编码器-解码器框架(如图2所示)。HRL的核心是其策略网络,策略网络主要由注意力模块(Attention Module)、管理和工作模块(Managerand Worker)和内部评价模块(Internal Critic)组成。
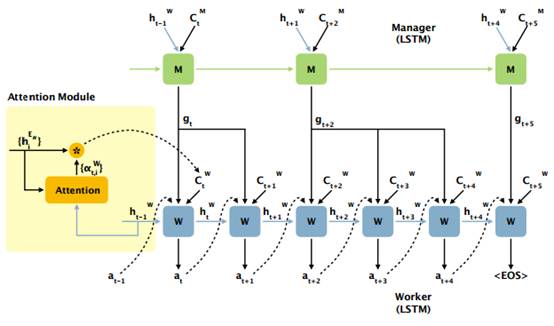
图3:在解码阶段(时间从t到t+5)将HRL框架展开示例。黄色区域显示了注意里模块如何结合到编码器-解码器框架中。
Attention Module
以Worker的attention module为例,其计算方式如下:
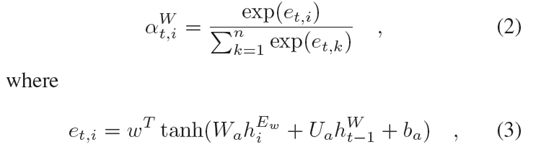
其中w,Wa,Ua,ba是可学习的参数,ht-1是Worker LSTM上一时刻的隐层状态。Manager的注意模块与Worker的结构一样。
Manager and Worker
Manager通过如下方式产生隐目标向量gt用以指导Worker生成具体的caption:
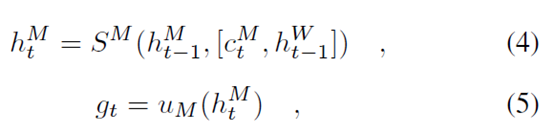
这里SM是Manager LSTM中的非线性函数,uM是一个将隐状态投影到目标空间的函数。
Worker接收到Manager产生的目标gt,然后通过softmax计算一个概率分布来产生caption的每一个单词:
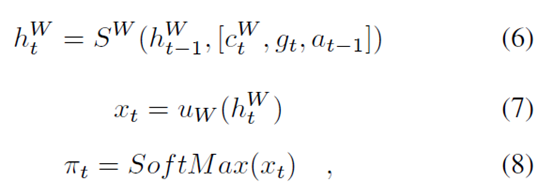
Internal Critic
Internal Critic用于评价Worker是否完成了目标gt,其通过给定groundtruth来最大化似然函数进行训练:
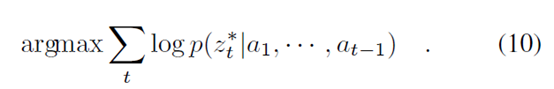
当Interal Critic训练完成后,其在Manager的使用过程中被固定。
▌实验结果

图4:在Charades数据集上用我们的方法与基准方法进行定性比较。

图5:在MSR-VTT数据集上用我们的方法与基准方法进行定性比较。
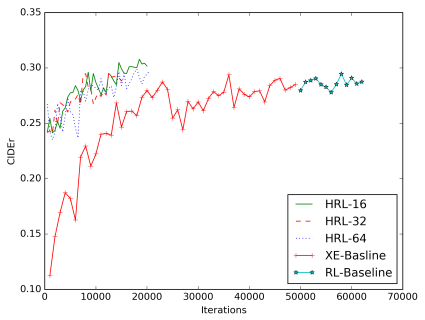
图6:不同视频描述模型的CIDEr分值的学习曲线。包括XE基准模型,RL基准模型和HRL模型分别在目标尺寸为16,32, 64条件下。
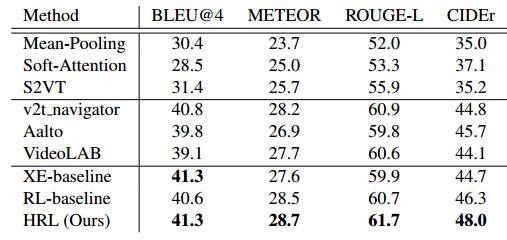
表1:在MSR-VTT数据集上与最先进的方法进行比较。
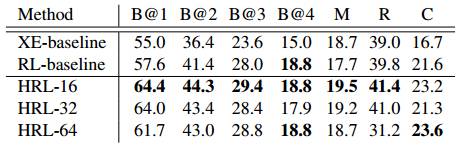
表2:Charades数据集上的结果。我们分别记录了我们的HRL模型以及两个基准方法的不同得分:包括BLEU(B),METEOR(M),ROUGH-L(R)和CIDEr(C)等得分。
▌结论
本文引入了视频描述的分层强化学习框架,其目的在于改进在具有丰富活动的细粒度视频场景下生成文本描述的方法。两层结构相互作用,在这个复杂的任务中展现出结构和语义的协调性。本文首先在流行的MSR-VTT数据集上评估其方法,并证明提出的方法的有效性。接下来,本文介绍了一个用于细粒度视频描述的新的大规模数据集,并进一步展示了提出的HRL模型的优良性能。
文章中指出,在未来,作者将计划探索注意力空间(attention space),并结合空间注意力形成一个时空注意力模型,以提升提出的HRL框架。此外,到目前为止,本文只是从一个预训练的CNN模型获得帧级特征,并用帧级特征进行实验。作者相信,提出的方法的结果可以通过使用不同类型的特征,如C3D特征[35],光流等进一步改善。同时,作者将在其他相似的序列生成任务(如视频/文档摘要)中探索本文提出的HRL框架。
参考文献
https://arxiv.org/abs/1711.11135
▌特别提示-Video Captioning via Hierarchical Reinforcement Learning 论文下载:
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“HRL” 就可以获取论文pdf下载链接~
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域25个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!

点击“阅读原文”,使用专知!
展开全文



