NLP新阶段!谷歌BERT模型横扫11项NLP任务记录
选自arXiv
授权转载于机器之心
作者:Jacob Devlin、Ming-Wei Chang、Kenton Lee、Kristina Toutanova
机器之心编译
参与:路、王淑婷、张倩
本文介绍了一种新的语言表征模型 BERT——来自 Transformer 的双向编码器表征。与最近的语言表征模型不同,BERT 旨在基于所有层的左、右语境来预训练深度双向表征。BERT 是首个在大批句子层面和 token 层面任务中取得当前最优性能的基于微调的表征模型,其性能超越许多使用任务特定架构的系统,刷新了 11 项 NLP 任务的当前最优性能记录。
近日,谷歌 AI 的一篇NLP论文引起了社区极大的关注与讨论,被认为是 NLP 领域的极大突破。如谷歌大脑研究科学家 Thang Luong Twitter 表示这是 NLP 领域的新时代。
Twitter 上也有众多研究者参与讨论、转发了这篇论文:

这篇刷新了 11 项 NLP 任务的论文不久之前已经上线,让我们一睹为快:
研究证明语言模型预训练可以有效改进许多自然语言处理任务,包括自然语言推断、复述(paraphrasing)等句子层面的任务,以及命名实体识别、SQuAD 问答等 token 层面的任务。前者通过对句子进行整体分析来预测句子之间的关系,后者则要生成 token 级别的细粒度输出。
目前将预训练语言表征应用于下游任务存在两种策略:基于特征的策略和微调策略(fine-tuning)。基于特征的策略(如 ELMo)使用将预训练表征作为额外特征的任务专用架构。微调策略(如生成预训练 Transformer (OpenAI GPT))引入了任务特定最小参数,通过简单地微调预训练参数在下游任务中进行训练。在之前的研究中,两种策略在预训练期间使用相同的目标函数,利用单向语言模型来学习通用语言表征。
本论文作者(即 Google AI Language 团队的研究人员)认为现有的技术严重制约了预训练表征的能力,微调策略尤其如此。其主要局限在于标准语言模型是单向的,这限制了可以在预训练期间使用的架构类型。例如,OpenAI GPT 使用的是从左到右的架构,其中每个 token 只能注意 Transformer 自注意力层中的先前 token。这些局限对于句子层面的任务而言不是最佳选择,对于 token 级任务(如 SQuAD 问答)则可能是毁灭性的,因为在这种任务中,结合两个方向的语境至关重要。
本文通过 BERT(Bidirectional Encoder Representations from Transformers)改进了基于微调的策略。BERT 提出一种新的预训练目标——遮蔽语言模型(masked language model,MLM),来克服上文提到的单向局限。MLM 的灵感来自 Cloze 任务(Taylor, 1953)。MLM 随机遮蔽输入中的一些 token,,目标在于仅基于遮蔽词的语境来预测其原始词汇 id。与从左到右的语言模型预训练不同,MLM 目标允许表征融合左右两侧的语境,从而预训练一个深度双向 Transformer。除了 MLM,我们还引入了一个「下一句预测」(next sentence prediction)任务,该任务联合预训练文本对表征。
本文贡献如下:
展示了双向预训练语言表征的重要性。不同于 Radford 等人(2018)使用单向语言模型进行预训练,BERT 使用 MLM 预训练深度双向表征。本研究与 Peters 等人(2018)的研究也不同,后者使用的是独立训练的从左到右和从右到左 LM 的浅层级联。
证明了预训练表征可以消除对许多精心设计的任务特定架构的需求。BERT 是首个在大批句子层面和 token 层面任务中取得当前最优性能的基于微调的表征模型,其性能超越许多使用任务特定架构的系统。
BERT 刷新了 11 项 NLP 任务的当前最优性能记录。本论文还报告了 BERT 的模型简化测试(ablation study),证明该模型的双向特性是最重要的一项新贡献。代码和预训练模型将发布在 goo.gl/language/bert。
论文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding

论文地址:
https://arxiv.org/pdf/1810.04805.pdf
摘要:本文介绍了一种新的语言表征模型 BERT,意为来自 Transformer 的双向编码器表征(Bidirectional Encoder Representations from Transformers)。与最近的语言表征模型(Peters et al., 2018; Radford et al., 2018)不同,BERT 旨在基于所有层的左、右语境来预训练深度双向表征。因此,预训练的 BERT 表征可以仅用一个额外的输出层进行微调,进而为很多任务(如问答和语言推断任务)创建当前最优模型,无需对任务特定架构做出大量修改。
BERT 的概念很简单,但实验效果很强大。它刷新了 11 个 NLP 任务的当前最优结果,包括将 GLUE 基准提升至 80.4%(7.6% 的绝对改进)、将 MultiNLI 的准确率提高到 86.7%(5.6% 的绝对改进),以及将 SQuAD v1.1 的问答测试 F1 得分提高至 93.2 分(提高 1.5 分)——比人类表现还高出 2 分。
BERT
本节介绍 BERT 及其实现细节。
模型架构
BERT 的模型架构是一个多层双向 Transformer 编码器,基于 Vaswani 等人 (2017) 描述的原始实现,在 tensor2tensor 库中发布。由于 Transformer 的使用最近变得很普遍,而且我们的实现与原始版本实际相同,我们将不再赘述模型架构的背景。
在本文中,我们将层数(即 Transformer 块)表示为 L,将隐藏尺寸表示为 H、自注意力头数表示为 A。在所有实验中,我们将前馈/滤波器尺寸设置为 4H,即 H=768 时为 3072,H=1024 时为 4096。我们主要报告在两种模型尺寸上的结果:
BERTBASE: L=12, H=768, A=12, 总参数=110M
BERTLARGE: L=24, H=1024, A=16, 总参数=340M
为了比较,BERTBASE 的模型尺寸与 OpenAI GPT 相当。然而,BERT Transformer 使用双向自注意力机制,而 GPT Transformer 使用受限的自注意力机制,导致每个 token 只能关注其左侧的语境。我们注意到,双向 Transformer 在文献中通常称为「Transformer 编码器」,而只关注左侧语境的版本则因能用于文本生成而被称为「Transformer 解码器」。图 1 直观显示了 BERT、OpenAI GPT 和 ELMo 的比较结果。
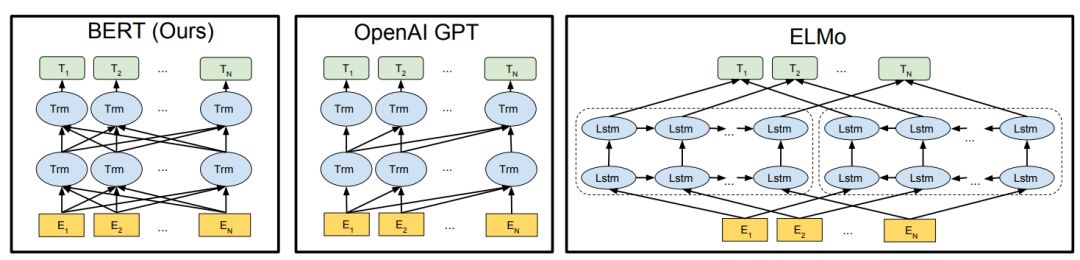
图 1:预训练模型架构之间的区别。BERT 使用双向 Transformer,OpenAI GPT 使用从左到右的 Transformer,ELMo 使用独立训练的从左到右和从右到左 LSTM 的级联来生成下游任务的特征。三种模型中,只有 BERT 表征会基于所有层中的左右两侧语境。
预训练任务
与 Peters 等人 (2018) 和 Radford 等人 (2018) 不同,我们不使用传统的从左到右或从右到左的语言模型来预训练 BERT,而是使用两个新型无监督预测任务。
任务 #1:Masked LM
为了训练深度双向表征,我们采取了一个直接的方法,随机遮蔽输入 token 的某些部分,然后预测被遮住的 token。我们将这一步骤称为「masked LM」(MLM),不过它在文献中通常被称为 Cloze 任务 (Taylor, 1953)。在这种情况下,对应遮蔽 token 的最终隐藏向量会输入到 softmax 函数中,并如标准 LM 中那样预测所有词汇的概率。在所做的所有实验中,我们随机遮住了每个序列中 15% 的 WordPiece token。与去噪自编码器 (Vincent et al., 2008) 相反,我们仅预测遮蔽单词而非重建整个输入。
任务 #2:下一句预测
很多重要的下游任务(如问答(QA)和自然语言推断(NLI))基于对两个文本句子之间关系的理解,这种关系并非通过语言建模直接获得。为了训练一个理解句子关系的模型,我们预训练了一个二值化下一句预测任务,该任务可以从任意单语语料库中轻松生成。具体来说,选择句子 A 和 B 作为预训练样本:B 有 50% 的可能是 A 的下一句,也有 50% 的可能是来自语料库的随机句子。
实验
这部分,我们将展示 BERT 在 11 个 NLP 任务上的微调结果。
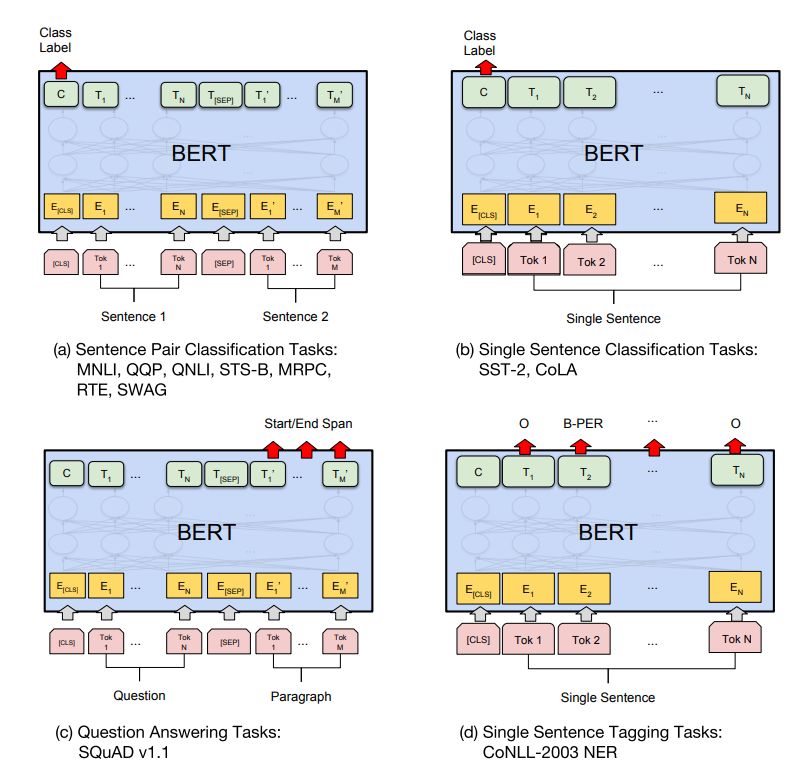
图 3:我们的任务特定模型是由向 BERT 添加了一个额外的输出层而形成的,因此一小部分参数需要从头开始学习。在众多任务中,(a) 和 (b) 任务是序列级任务,(c) 和 (d) 是 token 级任务,图中 E 表示输入嵌入,T_i 表示 token i 的语境表征,[CLS] 是分类输出的特殊符号,[SEP] 是分割非连续 token 序列的特殊符号。
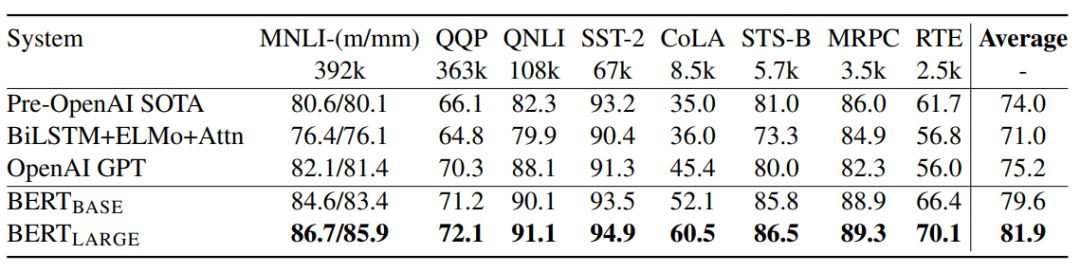
表 1:GLUE 测试结果,评分由 GLUE 评估服务器得到。每个任务下面的数字表示训练样本的数量。「Average」列与 GLUE 官方分数略微不同,因为我们排除了有问题的 WNLI 集。OpenAI GPT = (L=12, H=768, A=12);BERT_BASE = (L=12, H=768, A=12);BERT_LARGE = (L=24, H=1024, A=16)。BERT 和 OpenAI GPT 是单个模型、单个任务。所有结果来自于以下地址:https://gluebenchmark.com/leaderboard 和 https://blog.openai. com/language-unsupervised/。
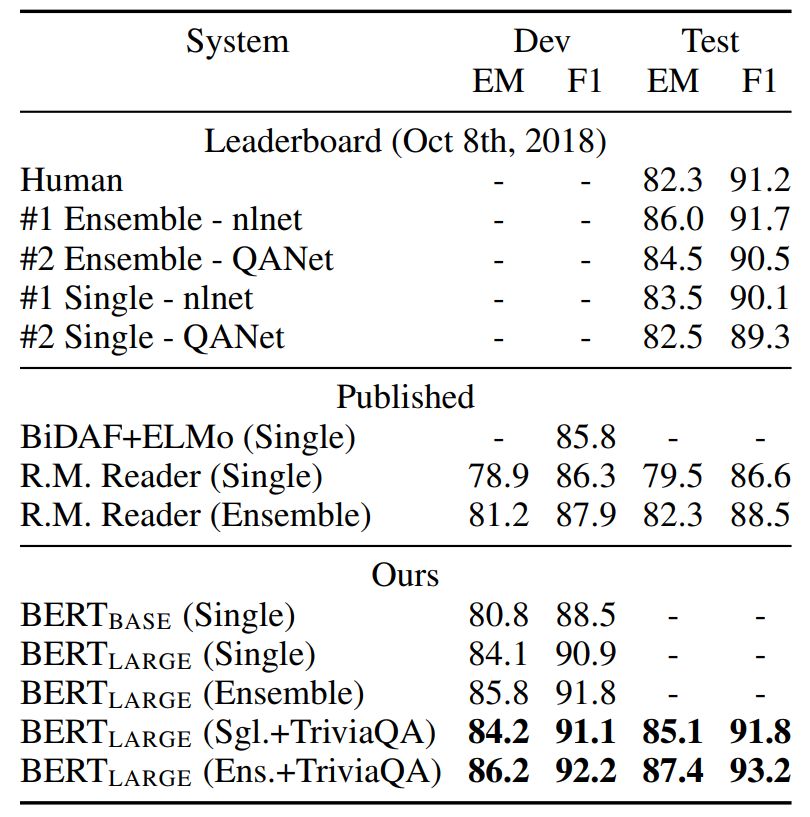
表 2:SQuAD 结果。BERT 集成是使用不同预训练检查点和微调种子(fine-tuning seed)的 7x 系统。
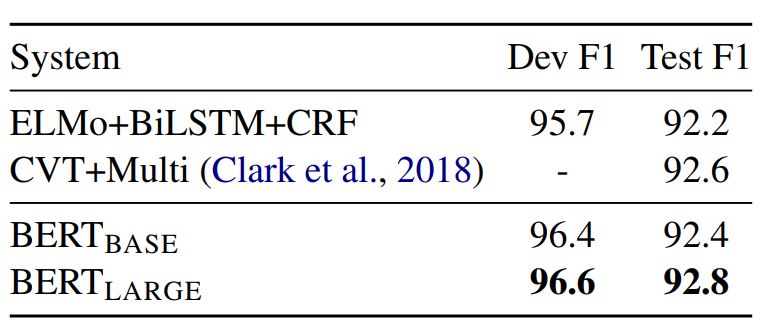
表 3:CoNLL-2003 命名实体识别结果。超参数通过开发集来选择,得出的开发和测试分数是使用这些超参数进行五次随机 restart 的平均值。
-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知
展开全文



