春节充电系列:李宏毅2017机器学习课程学习笔记12之半监督学习(Semi-supervised Learning)
【导读】我们在上一节的内容中已经为大家介绍了台大李宏毅老师的机器学习课程的深度学习要求深的原因,这一节将主要针对讨论半监督学习。本文内容涉及机器学习中半监督学习的若干主要问题:semi-supervised learning for generative model, low-density separation assumption, smoothness assumption以及better representation。话不多说,让我们一起学习这些内容吧 。
春节充电系列:李宏毅2017机器学习课程学习笔记02之Regression
春节充电系列:李宏毅2017机器学习课程学习笔记03之梯度下降
春节充电系列:李宏毅2017机器学习课程学习笔记04分类(Classification)
春节充电系列:李宏毅2017机器学习课程学习笔记05之Logistic 回归
春节充电系列:李宏毅2017机器学习课程学习笔记06之深度学习入门
春节充电系列:李宏毅2017机器学习课程学习笔记07之反向传播(Back Propagation)
春节充电系列:李宏毅2017机器学习课程学习笔记08之“Hello World” of Deep Learning
春节充电系列:李宏毅2017机器学习课程学习笔记09之Tip for training DNN
春节充电系列:李宏毅2017机器学习课程学习笔记10之卷积神经网络
春节充电系列:李宏毅2017机器学习课程学习笔记11之Why Deep Learning?
课件网址:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17_2.html
视频网址:
https://www.bilibili.com/video/av15889450/index_1.html

李宏毅机器学习笔记12 Semi-supervised Learning
Semi-supervised learning指的用一些有labeled的data和许多unlabeled的data进行训练,因为收集data是容易的,但收集有label的data是很难的。当测试集中有unlabeled data时称为transductive learning;测试集中没有unlabeled data时称为inductive learning。

当我们仅仅有少量data可能学出如下图的边界

然而unlabeled data能够告诉我们其他的信息,并且semi-supervised learning往往伴随着一些假设

这次主要介绍了以下内容

1.semi-supervised learning for generative model
在之前的supervised generative model,在二分类问题中,我们已经讲了如何求得P(C1|X)的概率。

但在semi-supervised generative model中,加入unlabeled data后,之前的高斯模型明显不行,所以我们要利用unlabeled data来重新确定模型。

我们先初始化所有参数,估测unlabeled data 属于C1的几率,算出几率后可以update model,更新P(C1)的值,和μ1的值,然后回到step 1,继续循环下去,一直到收敛

之前的用labelled data训练只是单纯地最大labelled data的likelihood。现在也要最大化unlabeled data的likelihood,由于不知道它的label,所以要分别讨论属于C1的几率和属于C2的几率。

2.low-density separation assumption
下面介绍low-density separation,这是一个非黑即白的方式,意味着两个class有个很明显的鸿沟,在交界处密度是最低的。

用的方法就是self-training,先从label data去train一个model,根据这个model去label unlabeled data,叫做pseudo-label,将unlabeled data中拿出一些data放在label dataset中,然后回头继续train。

Self-training属于hard label, generative model属于soft label,对于NN必须使用hard label。
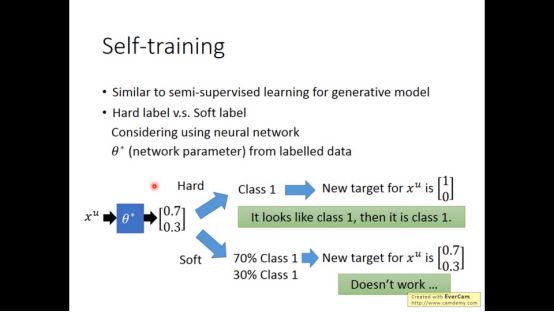
下面是进阶版,因为是非黑即白的世界,所以分布要越集中越好。我们就用信息熵来表示其分布是否集中。
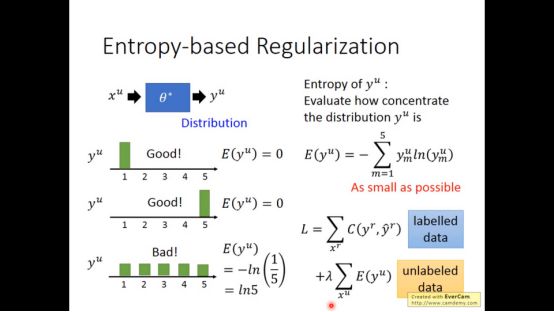
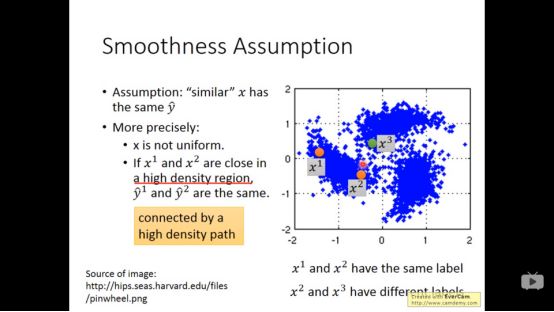
3.smoothness assumption
Smoothness的核心思想是近朱者赤近墨者黑。

如果X1,x2在high density region内比较靠近时,y1,y2就一样。
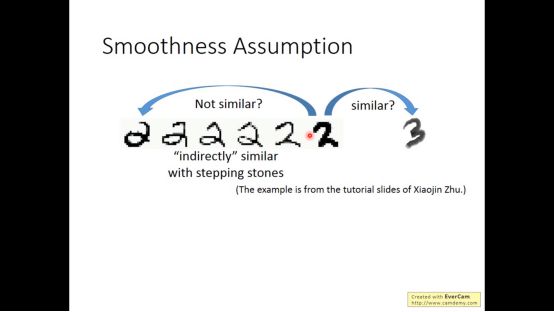
不同的2之间有过渡形态,然而2和3之间并没有。
对于smoothness assumption,最简单的做法是cluster and then label。
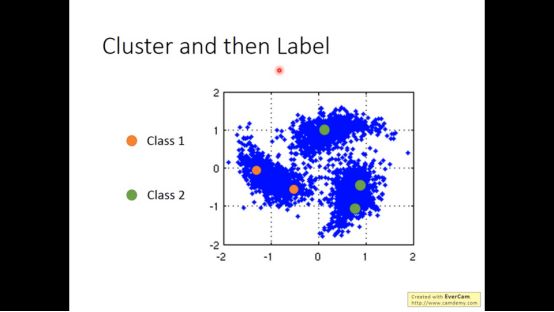
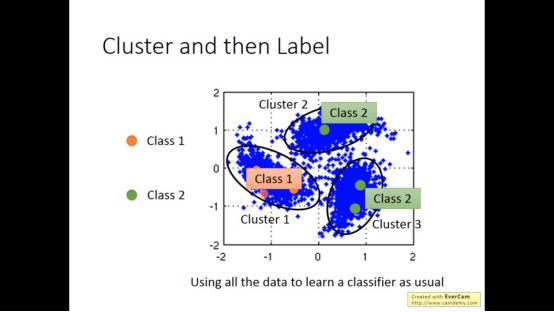
最终得到如下结果,但这个方法不一定有用,比如在图像中,白色的猫和白色的狗只用像素做cluster可能比较像,但他们不是同一个东西。
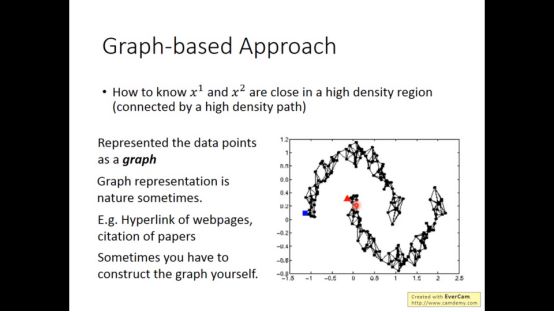
我们用graph来表示两个点是否在high density region。
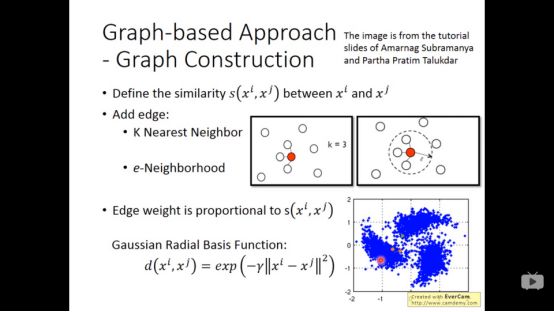
建立graph有很多方法,例如寻找最近的k的点,或者寻找相似度大于e的点。
Graph-based方法的精神是labelled data会影响它的邻居,并且传递下去 。
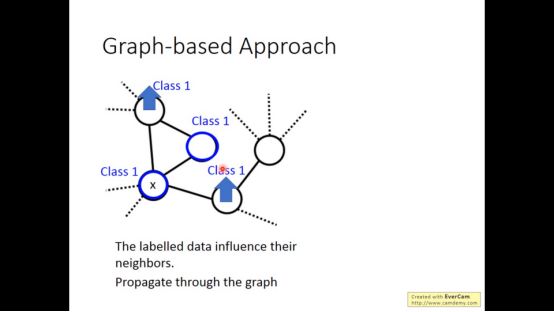
但当数据不是足够多的时候,可能在中间断掉。

以上是定性的分析,下面开始定量的分析。
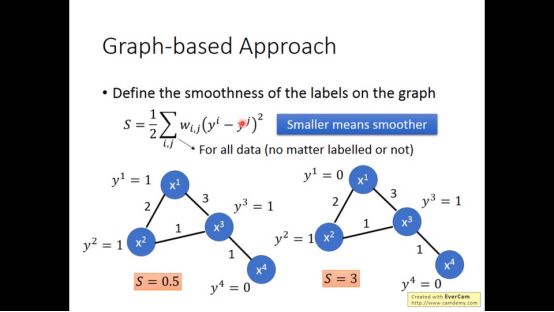
我们定义了smoothness,看graph里面的label有多平滑,明显下图左边的更平滑。S越小越平滑。
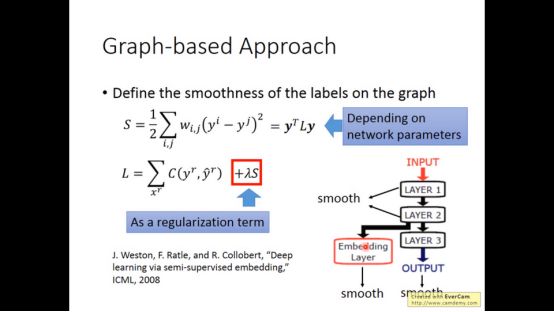
将S稍微变一下得到下图的式子,W是邻接矩阵,D是一个对角矩阵。

训练时,将S放入loss function就可以了。
4.better representation
Better representation核心思想是去无存菁,化繁为简。具体在unsupervised learning再讲。

简单来说,世界是复杂的,但复杂的世界的有背后一些简单的东西控制

请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“LHY2017” 就可以获取 2017年李宏毅中文机器学习课程下载链接~
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



