微软亚洲研究院新论文-《多模态预训练语言模型UniViLM》面向多模态理解和生成的统一视频和语言预训练模型

地址:
https://www.zhuanzhi.ai/paper/fe19c74f00987c7cec428576bdea63e2
https://arxiv.org/abs/2002.06353
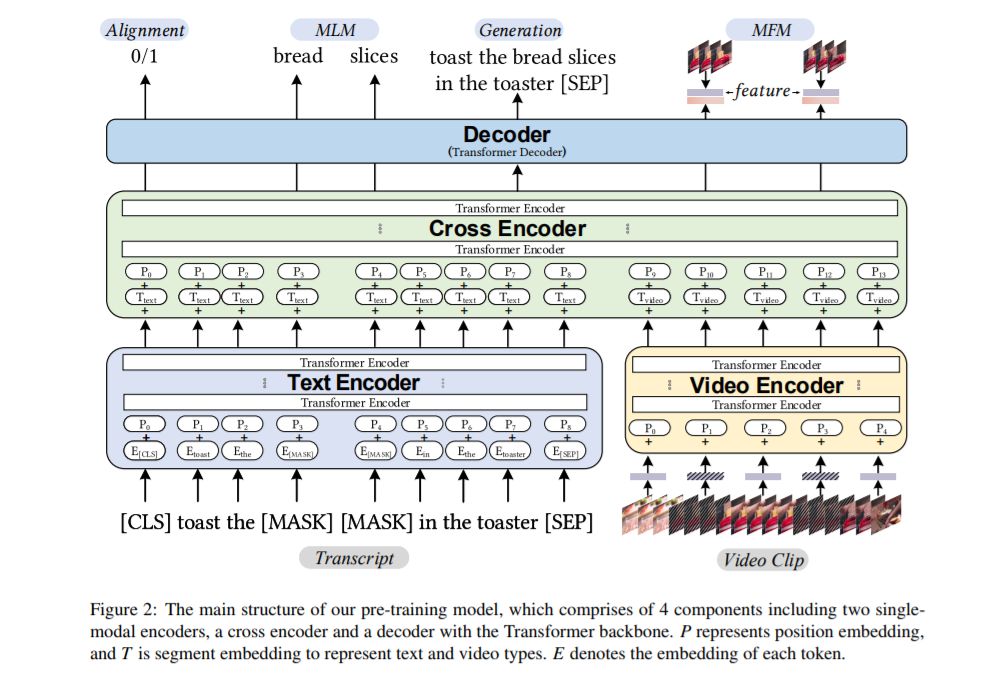
我们提出UniViLM:一个用于多模态理解和生成的统一视频和语言预训练模型。最近,基于BERT的NLP和图像语言任务预训练技术取得了成功,受此启发,VideoBERT和CBT被提出将BERT模型用于视频和语言预训练,并使用叙事性教学视频。不同于他们的工作只训练理解任务,我们提出了一个统一的视频语言理解和生成任务的预训练模型。我们的模型由4个组件组成,包括两个单模态编码器、一个交叉编码器和一个带Transformer主干的译码器。我们首先对我们的模型进行预训练,以学习视频和语言在大型教学视频数据集上的通用表示。然后,我们在两个多模态任务上对模型进行微调,包括理解任务(基于文本的视频检索)和生成任务(多模态视频字幕)。我们的大量实验表明,我们的方法可以提高理解和生成任务的性能,并取得了最先进的结果。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“UVLM” 就可以获取《多模态预训练语言模型UniViLM》专知下载链接



展开全文



