【论文推荐】最新5篇信息抽取(IE)相关论文—开放信息抽取、不完整信息、主动学习、越南语、依存分析
【导读】专知内容组整理了最近五篇信息抽取(Information Extraction)相关文章,为大家进行介绍,欢迎查看!
1. Assertion-based QA with Question-Aware Open Information Extraction(基于Assertion的问答和问题感知的开放信息抽取)
作者:Zhao Yan,Duyu Tang,Nan Duan,Shujie Liu,Wendi Wang,Daxin Jiang,Ming Zhou,Zhoujun Li
摘要:We present assertion based question answering (ABQA), an open domain question answering task that takes a question and a passage as inputs, and outputs a semi-structured assertion consisting of a subject, a predicate and a list of arguments. An assertion conveys more evidences than a short answer span in reading comprehension, and it is more concise than a tedious passage in passage-based QA. These advantages make ABQA more suitable for human-computer interaction scenarios such as voice-controlled speakers. Further progress towards improving ABQA requires richer supervised dataset and powerful models of text understanding. To remedy this, we introduce a new dataset called WebAssertions, which includes hand-annotated QA labels for 358,427 assertions in 55,960 web passages. To address ABQA, we develop both generative and extractive approaches. The backbone of our generative approach is sequence to sequence learning. In order to capture the structure of the output assertion, we introduce a hierarchical decoder that first generates the structure of the assertion and then generates the words of each field. The extractive approach is based on learning to rank. Features at different levels of granularity are designed to measure the semantic relevance between a question and an assertion. Experimental results show that our approaches have the ability to infer question-aware assertions from a passage. We further evaluate our approaches by incorporating the ABQA results as additional features in passage-based QA. Results on two datasets show that ABQA features significantly improve the accuracy on passage-based~QA.
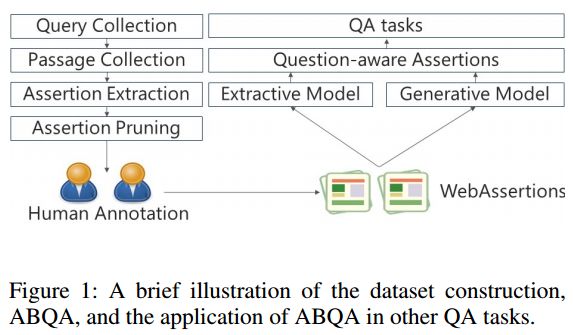
期刊:arXiv, 2018年1月23日
网址:
http://www.zhuanzhi.ai/document/b0e8ca6526b976e46aa27863281f0d7b
2. Document Spanners for Extracting Incomplete Information: Expressiveness and Complexity
作者:Francisco Maturana,Cristian Riveros,Domagoj Vrgoč
摘要:Rule-based information extraction has lately received a fair amount of attention from the database community, with several languages appearing in the last few years. Although information extraction systems are intended to deal with semistructured data, all language proposals introduced so far are designed to output relations, thus making them incapable of handling incomplete information. To remedy the situation, we propose to extend information extraction languages with the ability to use mappings, thus allowing us to work with documents which have missing or optional parts. Using this approach, we simplify the semantics of regex formulas and extraction rules, two previously defined methods for extracting information, extend them with the ability to handle incomplete data, and study how they compare in terms of expressive power. We also study computational properties of these languages, focusing on the query enumeration problem, as well as satisfiability and containment.
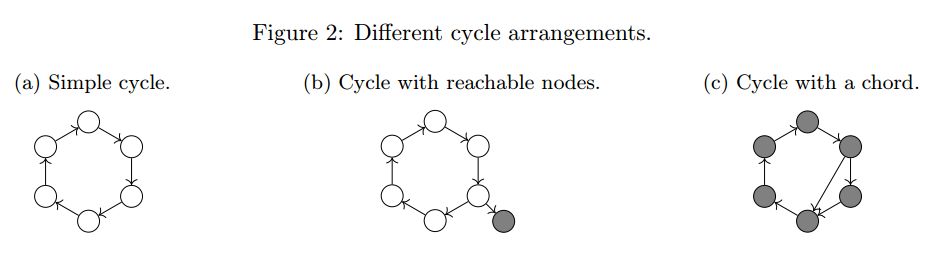
期刊:arXiv, 2017年12月30日
网址:
http://www.zhuanzhi.ai/document/0f4260693b1a9a005f787d3ab3337828
3. Support Vector Machine Active Learning Algorithms with Query-by-Committee versus Closest-to-Hyperplane Selection(支持向量机主动学习算法和查询与最近超平面选择)
作者:Michael Bloodgood
摘要:This paper investigates and evaluates support vector machine active learning algorithms for use with imbalanced datasets, which commonly arise in many applications such as information extraction applications. Algorithms based on closest-to-hyperplane selection and query-by-committee selection are combined with methods for addressing imbalance such as positive amplification based on prevalence statistics from initial random samples. Three algorithms (ClosestPA, QBagPA, and QBoostPA) are presented and carefully evaluated on datasets for text classification and relation extraction. The ClosestPA algorithm is shown to consistently outperform the other two in a variety of ways and insights are provided as to why this is the case.
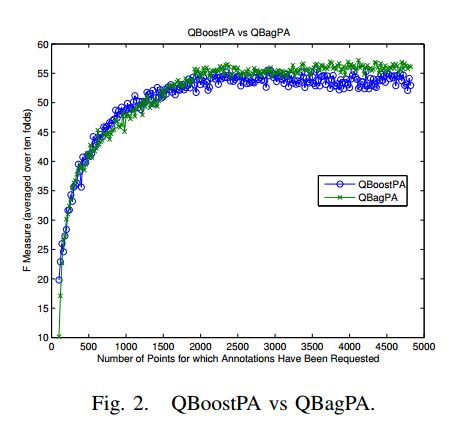
期刊:arXiv, 2018年1月24日
网址:
http://www.zhuanzhi.ai/document/0987b7a1daae4d71970067443aea15ea
4. Vietnamese Open Information Extraction(越南语开放信息提取)
作者:Diem Truong,Duc-Thuan Vo,U. T Nguyen
摘要:Open information extraction (OIE) is the process to extract relations and their arguments automatically from textual documents without the need to restrict the search to predefined relations. In recent years, several OIE systems for the English language have been created but there is not any system for the Vietnamese language. In this paper, we propose a method of OIE for Vietnamese using a clause-based approach. Accordingly, we exploit Vietnamese dependency parsing using grammar clauses that strives to consider all possible relations in a sentence. The corresponding clause types are identified by their propositions as extractable relations based on their grammatical functions of constituents. As a result, our system is the first OIE system named vnOIE for the Vietnamese language that can generate open relations and their arguments from Vietnamese text with highly scalable extraction while being domain independent. Experimental results show that our OIE system achieves promising results with a precision of 83.71%.
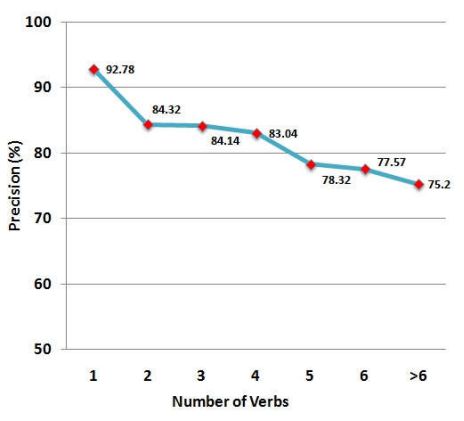
期刊:arXiv, 2018年1月24日
网址:
http://www.zhuanzhi.ai/document/25d83fe78d2f2ff9b188a8ececf55b81
5. Building an Ellipsis-aware Chinese Dependency Treebank for Web Text(为中文Web文本构建一个基于省略号的依存分析树库)
作者:Xuancheng Ren,Xu Sun,Ji Wen,Bingzhen Wei,Weidong Zhan,Zhiyuan Zhang
摘要:Web 2.0 has brought with it numerous user-produced data revealing one's thoughts, experiences, and knowledge, which are a great source for many tasks, such as information extraction, and knowledge base construction. However, the colloquial nature of the texts poses new challenges for current natural language processing techniques, which are more adapt to the formal form of the language. Ellipsis is a common linguistic phenomenon that some words are left out as they are understood from the context, especially in oral utterance, hindering the improvement of dependency parsing, which is of great importance for tasks relied on the meaning of the sentence. In order to promote research in this area, we are releasing a Chinese dependency treebank of 319 weibos, containing 572 sentences with omissions restored and contexts reserved.

期刊:arXiv, 2018年1月23日
网址:
http://www.zhuanzhi.ai/document/342c2bc6d7000fc3f4602f6ac1f7ba9f
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



