【论文读书笔记】个性化序列推荐:卷积序列嵌入方法
【导读】序列预测和推荐问题在捕捉用户短期兴趣的个性化服务上显得尤为重要。传统的模型只能对相邻的行为进行建模,不能捕捉联合级和跳过型的序列模式,极大地限制了序列预测和推荐的灵活性。这篇文章通过利用多个卷积滤波器来提取用户的行为模式,构建灵活的点级、联合级和跳过式的序列模式,提高用户个性化序列推荐的准确率,已经被WSDM2018录用。
【论文】:Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding

论文链接:
http://www.sfu.ca/~jiaxit/resources/wsdm18caser.pdf
论文代码:https://github.com/graytowne/caser
▌摘要
Top-N序列推荐将每个用户建模为过去交互过的物品的序列,目的是预测用户可能在“不久的将来”进行交互的Top-N个物品。交互顺序意味着序列模式在序列中的最近项对下一项的影响起着重要作用。
本文提出了一种卷积序列嵌入推荐模型(Convolutional Sequence Embedding Recommendation Model:Caser)作为解决这一需求的方法,其思想是在时间和潜在空间中将一组最近的物品序列嵌入到一张“图像”中,并利用卷积滤波器来学习作为图像的局部特征的序列模式,这种方法为提取长期兴趣和序列模式提供了一种统一而又简洁的网络结构。在公共数据集上的实验表明,在各种常用的评估指标上,Caser的性能始终优于最先进的顺序推荐方法。
▌简介
推荐系统已成为许多应用的核心技术。大多数系统,例如top-N推荐,根据用户的一般喜好推荐物品,而不注意项物品的最近情况。例如,一些用户总是更喜欢苹果的产品而不是三星的产品。一般偏好代表用户的长期和静态的行为,而另一种类型的用户行为是顺序模式,其中下一个物品或者行为更有可能取决于用户最近参与的行为或交互的物品。序列模式代表了用户的短期和动态行为,来自于在很近的时间物品之间的某种关系。
例如,用户可能在购买iPhone后不久就购买手机配件,尽管用户一般不会购买手机配件。在这种情况下,只考虑一般偏好的系统将错过在销售iPhone后推荐手机配件的机会,因为购买手机配件不是一种长期的用户行为。给定用户的行为序列,本文的目标是通过结合哟用户的一般喜好和序列模式,来推荐他\她未来最优可能需要的一系列物品。和传统的Top-N推荐不同的是,top-N序列推荐将用户行为建模为物品的序列,而不是物品的集合。
以往相关工作的局限性
基于马尔可夫链的模型是Top-N序列推荐早期的一种方法,L阶马尔可夫链基于前L个行为来做推荐。一阶马尔可夫链是利用极大似然估计学习的一种物品到物品的转移矩阵. Rendle等人提出的分解个性化马尔可夫链(FPMC)及其变体通过将转移矩阵分解为两个潜在的和低秩的子矩阵来改进这种方法。基于物品相似模型的分解序列预测(Fossil)将该方法推广到高阶马尔可夫链,利用加权和聚合方法对已有物品的潜在表示进行加权和聚合。然而,现有的方法主要有两方面局限性:
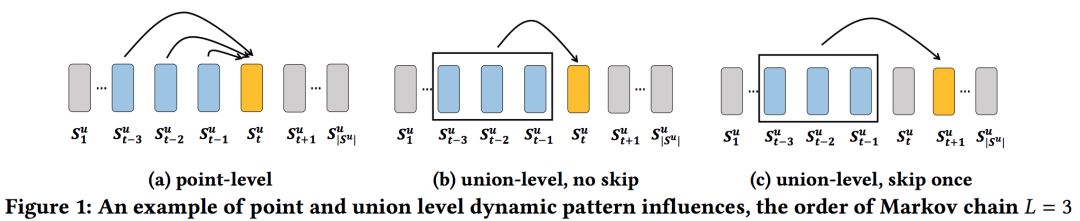
(1)未能对联合级序列模式进行建模。如图1(a)所示,马尔可夫链建模的仅仅是点级顺序模式,其中先前的每一个动作(蓝色)都是单独地而不是集体地影响目标动作(黄色)。FPMC和Fossil也属于这类。这种点级信息的聚合对于建模图1(b)所示的联合级影响是不够的,图1(b)所示的是先前的几个行为按着这个顺序,联合起来影响目标行为。例如,同时购买牛奶和黄油比单独购买牛奶或黄油的概率更高;购买RAM和硬盘比只购买其中一个组件更能说明下一步购买操作系统的情况。
(2)不允许跳过某些行为。现有模型不考虑跳过顺序模式的行为,如图1(c)所示,过去行为的影响可能跳过几步,但仍有很大的优势。例如,游客在机场、酒店、餐厅、酒吧和景点中依次签到,虽然机场和酒店的签到并不是在景点之前,但它们与后者依然有很强的关联。在餐厅或酒吧签到对景点签到几乎没有影响,因为去景点之前到餐厅或者酒吧不是需要的。L阶马尔可夫链没有明确地建模这种跳过行为,因为它假定前面的L个行为对下一步有影响。
本文贡献
为解决上述现有工作的局限性,作者提出一种卷积序列嵌入推荐模(Caser),作为Top-N序列推荐的解决方案。卷积神经网络(CNN)的卷积滤波器能够捕捉图像局部特。Caser的创新之处在于将前L个物品表示为L×d的矩阵E,其中d是维度,行是按顺序出现的物品。作者将L个物品在隐空间的嵌入矩阵作为一个“图像”来寻找它的序列模式。与图像识别不同的是,这个“图像”不是在输入中给出的,必须是和所有的滤波器同时学习。
与现有的方法相比,Caser有几个明显的优点。(1)Caser采用水平和垂直卷积模式来捕获点级、联合级和跳过行为的序列模式。(2)Caser对用户的一般偏好和序列模式进行了建模,并在一个统一的框架内对现有的几种最先进的方法进行了概括。(3)在实际数据集上,Caser方法优于先进的时序推荐方法。
▌模型介绍
如图2所示,Caser由三个部分组成:embedding层、卷积层和全连接层。为了训练CNN,本文从用户序列中为每个用户u提取L个连续物品作为输入,并提取它们接下来的T个物品作为目标,如图所示,这是通过在用户序列上滑动一个大小为L+T的窗口来完成的,每个窗口都为u生成一个训练样本,由一个三元组表示(用户u,前L个物品,后T个物品)。
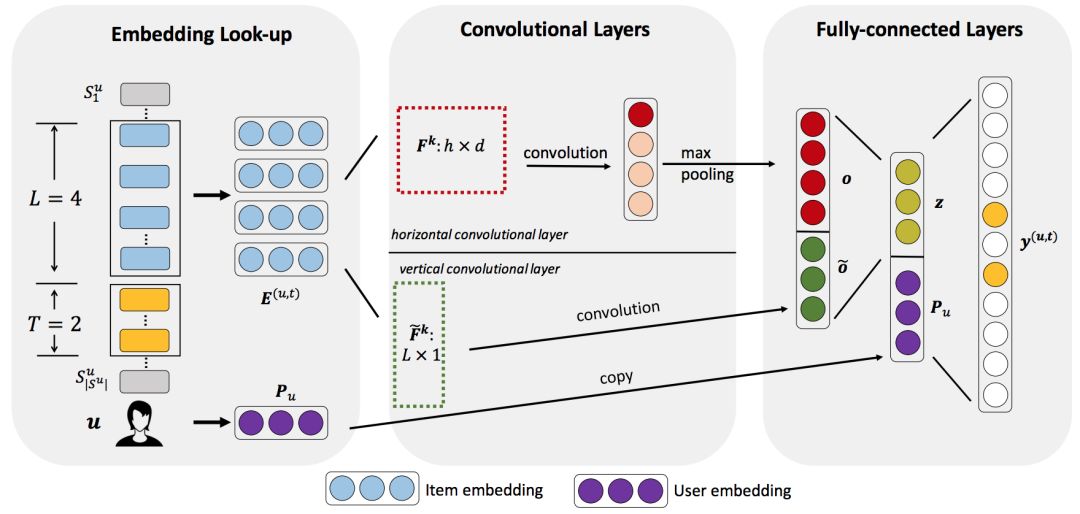
Figure 2. Caser算法的网络结构
Embedding层
将前L个物品在隐空间的表示连接起来,作为用户u在当前时刻t的序列矩阵表示:
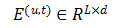
其中d是隐藏层的维数。
除了物品的表示之外,本文还为用户u提供了一个用户表示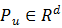
卷积层
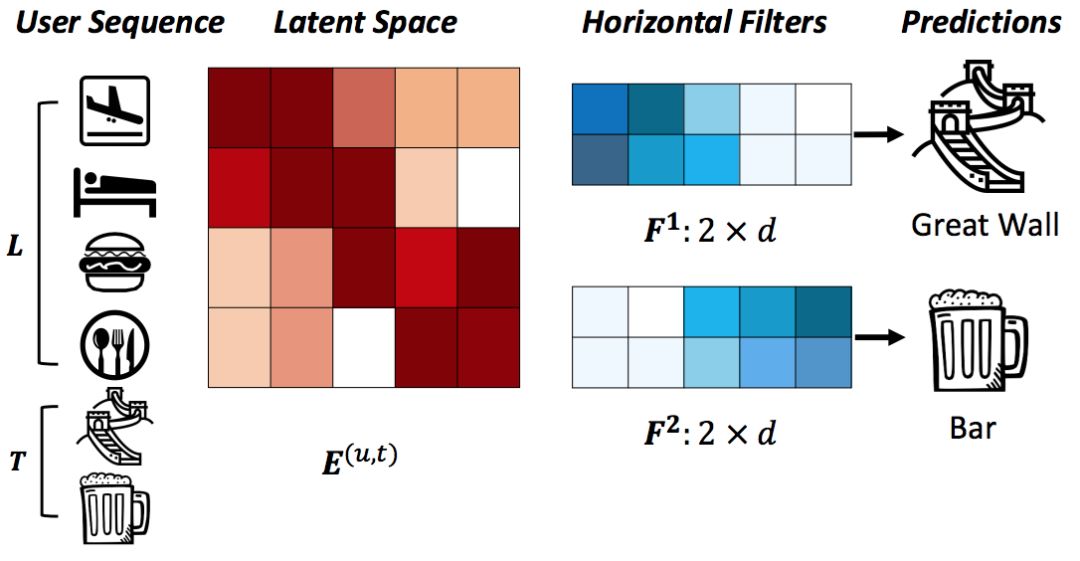
Figure 3. 卷积层示意图
将前L个物品在隐空间的表示(L×d的矩阵E)看作一张“图像”,该方法是利用卷积滤波器对其进行序列模式的搜索和学习。如图2所示,两个水平滤波器(用h×d的矩阵表示,图中所示h=2)通过在矩阵E上滑动来提取两种不同的联合级序列模式。其中第一个滤波器通过与“机场”和“酒店”的embedding表示的交互,跳过“快餐”和“餐馆”,提取出“(机场,酒店)→长城”的模式。第二个滤波器提取了“(快餐,餐馆)→酒吧”的序列模式。矩阵方块中颜色越深代表值越大。因此,水平滤波器可以被训练来提取具有多个联合大小的联合级模式。
图2中间卷积部分的下半部分显示了垂直卷积层,在该层中,垂直滤波器(用d×1的矩阵表示)在矩阵E上从左到右滑动,通过对前几项物品的潜在表示的加权和来捕获点级序列模式。
全连接层
在全连接层中,如图2右边部分所示,作者将这两个卷积层的输出串联起来,并将它们输入到一个全连接的神经网络中,以获得更高层次和更抽象的特征。为了提取用户的一般喜好,作者还将用户embedding表示连接到卷积层的输出表示中,并将它们投影到有N个节点的输出层。向量Z表示用户的短期兴趣,而向量 则代表了用户的长期兴趣。最后,作者将用户嵌入到最后一个隐藏层中,原因如下:(1)使其具有推广其他模型的能力。(2)可以用其他广义模型的参数对模型参数进行预训练,这种预训练对模型性能至关重要。
▌总结
Caser是一种创新的解决方案,它通过将最近的行为建模为时间和潜在维度之间的“图像”,并使用卷积滤波器来学习序列模式,从而解决了Top-N序列推荐的问题。该方法为获取许多序列推荐的要特征,比如点级和联合级序列模式、跳过行为和长期用户偏好提供了统一而又简洁的网络结构。本文在公开的现实生活数据集的实验和案例研究表明,caser的性能优于Top-N 序列推荐的最新方法。
参考链接:
http://www.sfu.ca/~jiaxit/resources/wsdm18caser.pdf
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



