【重温经典】吴恩达机器学习课程学习笔记五:多元梯度下降
【导读】前一段时间,专知内容组推出了春节充电系列:李宏毅2017机器学习课程学习笔记,反响热烈,由此可见,大家对人工智能、机器学习的系列课程非常感兴趣,近期,专知内容组推出吴恩达老师的机器学习课程笔记系列,重温机器学习经典课程,希望大家会喜欢。
【重温经典】吴恩达机器学习课程学习笔记二:无监督学习(unsupervised learning)
【重温经典】吴恩达机器学习课程学习笔记三:监督学习模型以及代价函数的介绍
吴恩达机器学习课程系列视频链接:
http://study.163.com/course/courseMain.htm?courseId=1004570029
吴恩达课程学习笔记五:多元梯度下降
1、多种特征
在前面的总结中介绍了根据房子size去预测price的例子,其中特征只有size。下面将这个例子复杂化,即现在有四个特征可能会影响最终的price。
如下图所示,一些参数的解释是:
n为特征的种类数目
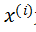
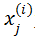
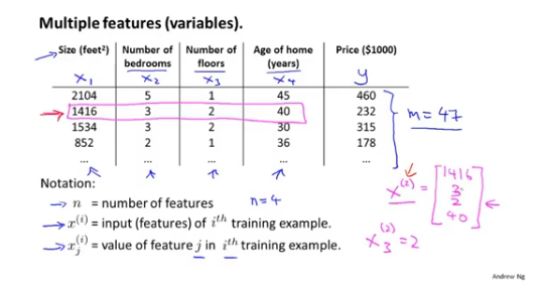
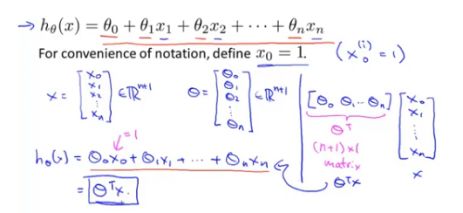
此时预测函数表示如下(当然按照上述的例子,这里n取4):
注意:在这里,为了表示方便,设置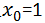
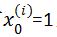
2、多元梯度下降算法
根据上文所总结可知,预测函数,参数以及代价函数如下:
这里用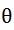
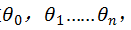
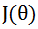

下图右下部分给出了前三个参数的更新过程(其它参数也是类似):

3、多元梯度下降法演练之特征缩放
特征缩放的原因:如下图所示,假设有两种特征,一种是房子的size,范围在0-2000,另一种是卧室的数目,范围在1-5。
如果忽略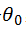
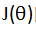
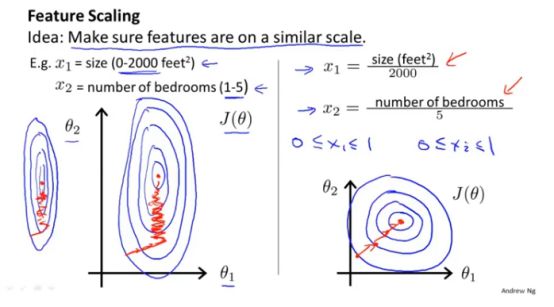
特征缩放的默认规则:尽量使得每个特征的取值范围变为-1—1之间,但并不是一定要特别精确,在-3—到3,以及-1/3—1/3都算比较合理。
即只要特征缩放后的取值范围近似就可以,不需要太精确,特征缩放的目的是为了让梯度下降地更加快一点。

4、多元梯度下降法演练之学习率
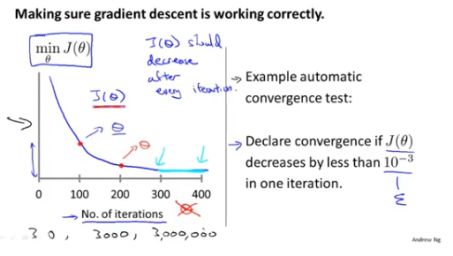
如何知道梯度下降算法收敛:
如下图所示,绘制出了J(θ)的值随着迭代次数变化的图像(横轴代表迭代次数),图中所示,在迭代了300—400次后J(θ)的值几乎不变,可以认为已经收敛。
也可以下图右半部分描述的自动检测收敛的方法:即下一次迭代后的J(θ)值与前一次差值在小于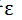
如何选择学习率使得梯度下降算法正常运行:
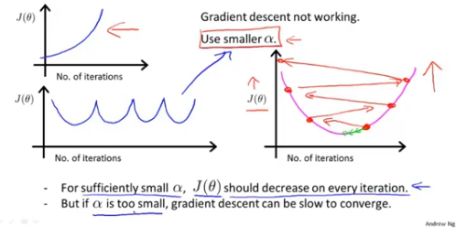
如图所示,对于左上部分,可能由于学习率设置的过大,使得J(θ)一直无法收敛。左下图显示的是J(θ)上下振动,这两种情况都可以通过减小学习率α来使得下降算法最终收敛。
两点说明:
对于线性回归来说,已经被证明,小的学习率一定会使得在每次的迭代过程中都使得J(θ)减小。
如果学习率过小,则收敛的速度会很慢。

如上图,为了选择合适的学习率,可以每隔十倍取一个α值,观察J(θ)的收敛情况,从而选取较为合适的α值。
下一次的总结笔记中将与你一同学习特征与多项式回归的相关内容。
参考链接:
http://study.163.com/course/courseMain.htm?courseId=1004570029
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“NGML2018” 就可以获取 吴恩达机器学习课程下载链接~
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~
点击“阅读原文”,使用专知
展开全文



