【NeurlPS2019教程】微软首席研究员Katja Hofmann - 强化学习:过去、现在和未来展望,附97页ppt
导读

Twitter: @katjahofmann

01
Formalizing RL
形式化RL

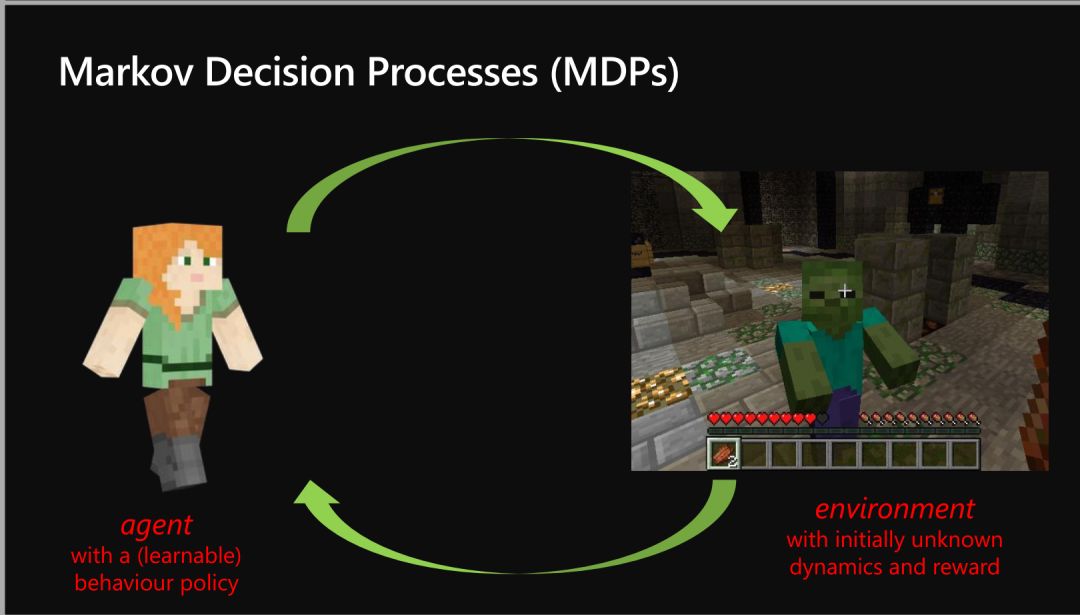
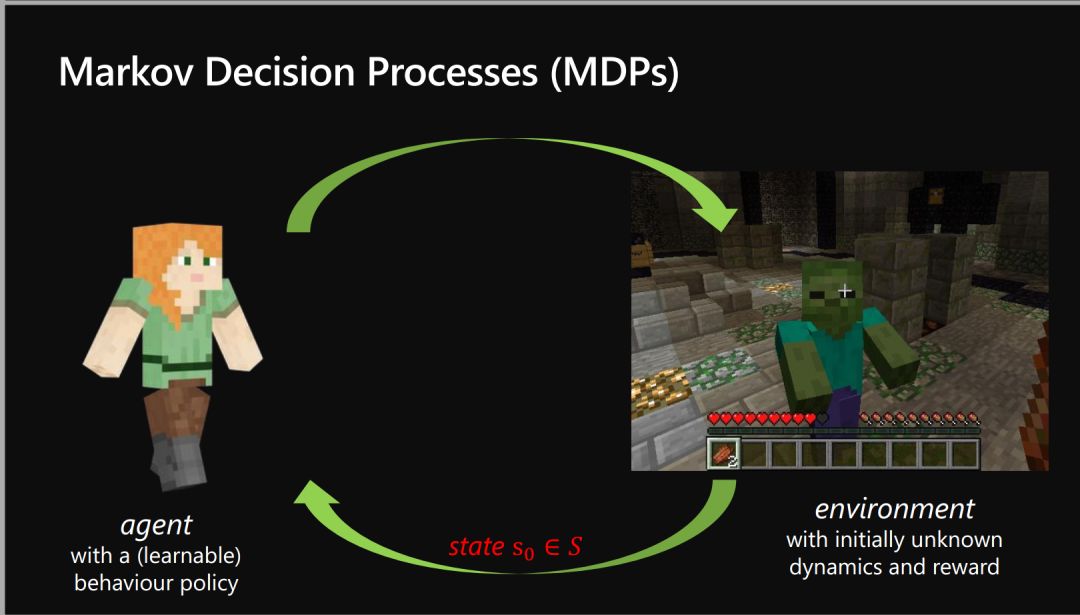
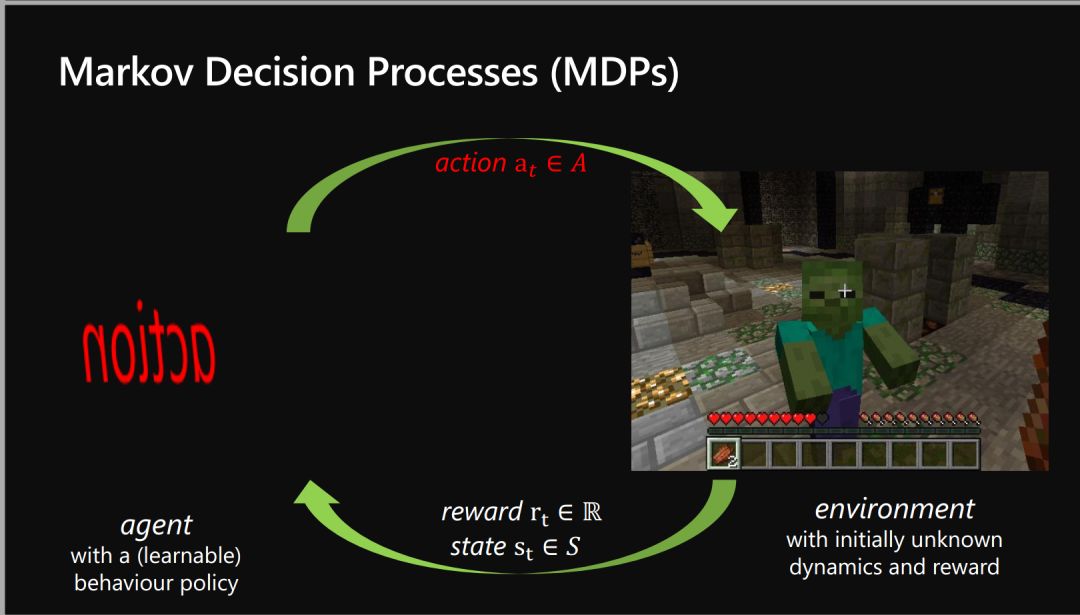
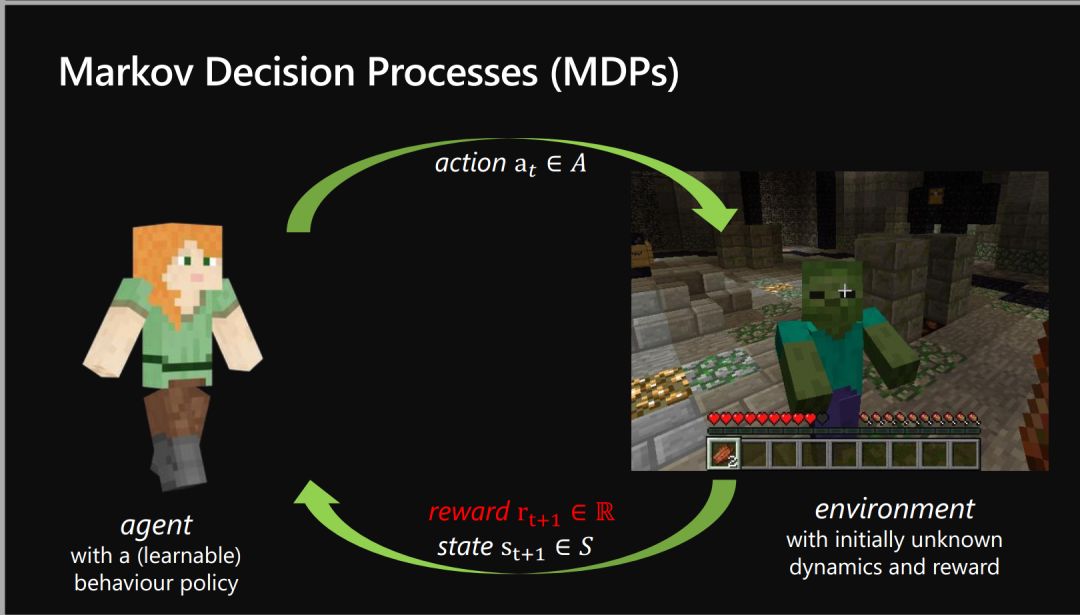

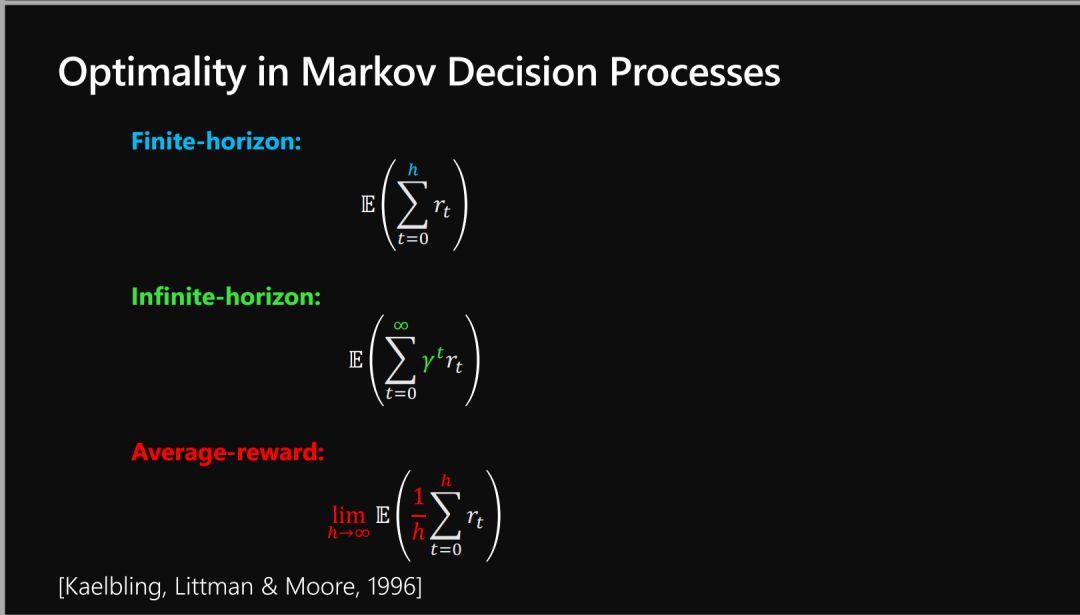

-
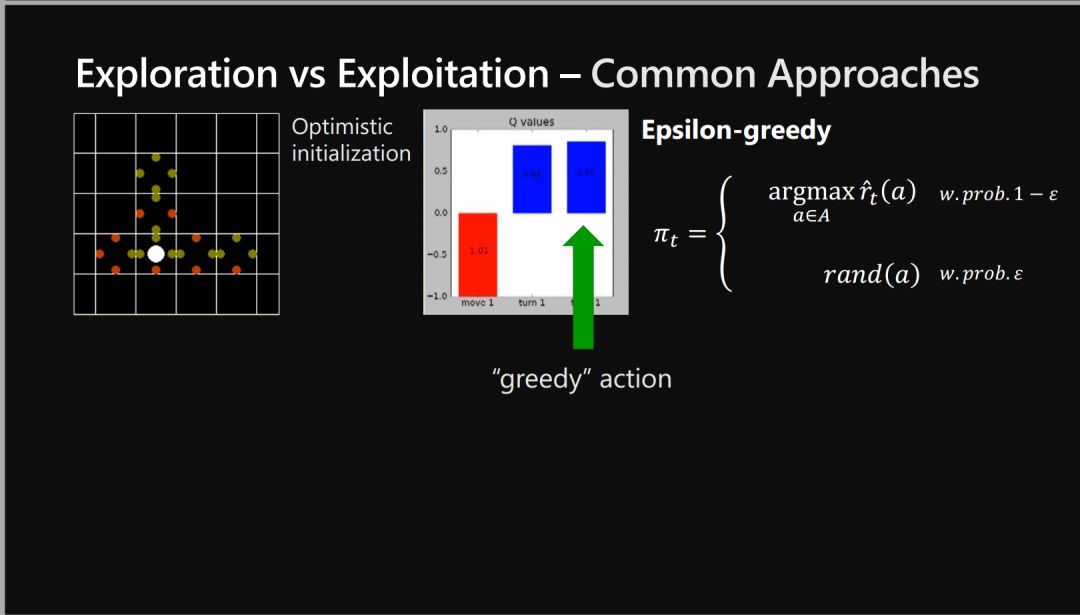
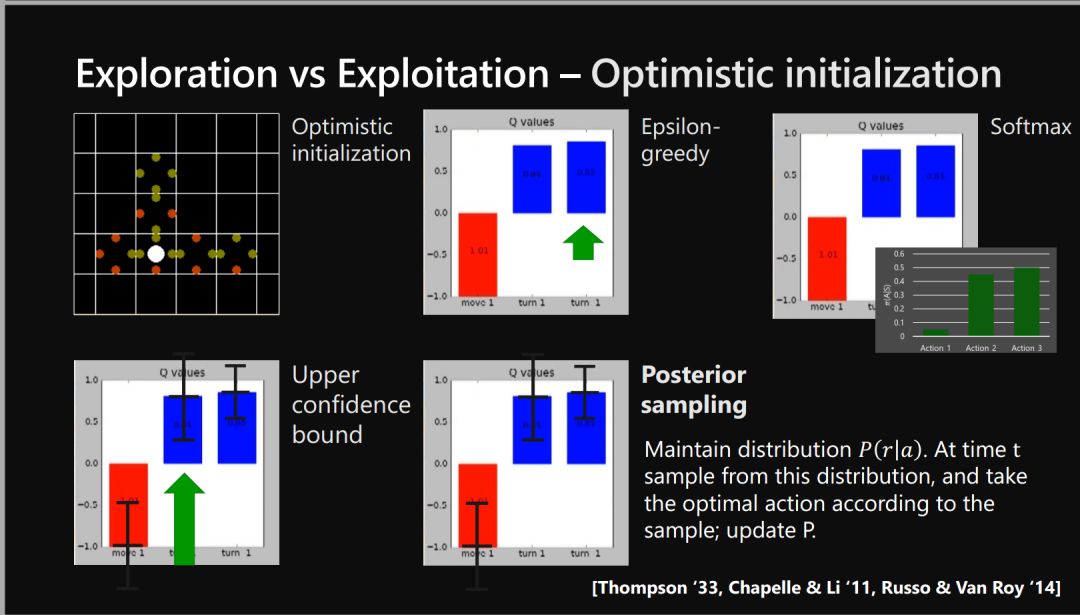
探索-利用困境 Explore-exploit -
信用分配问题 Credit assignment -
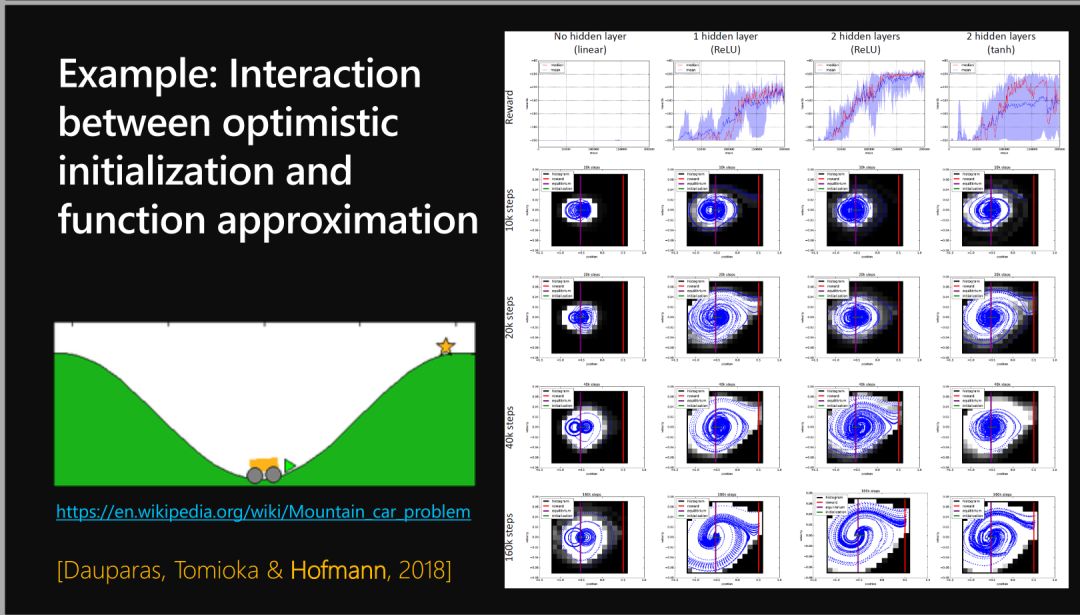
函数近似 Function approximation
02
Value Functions
值函数



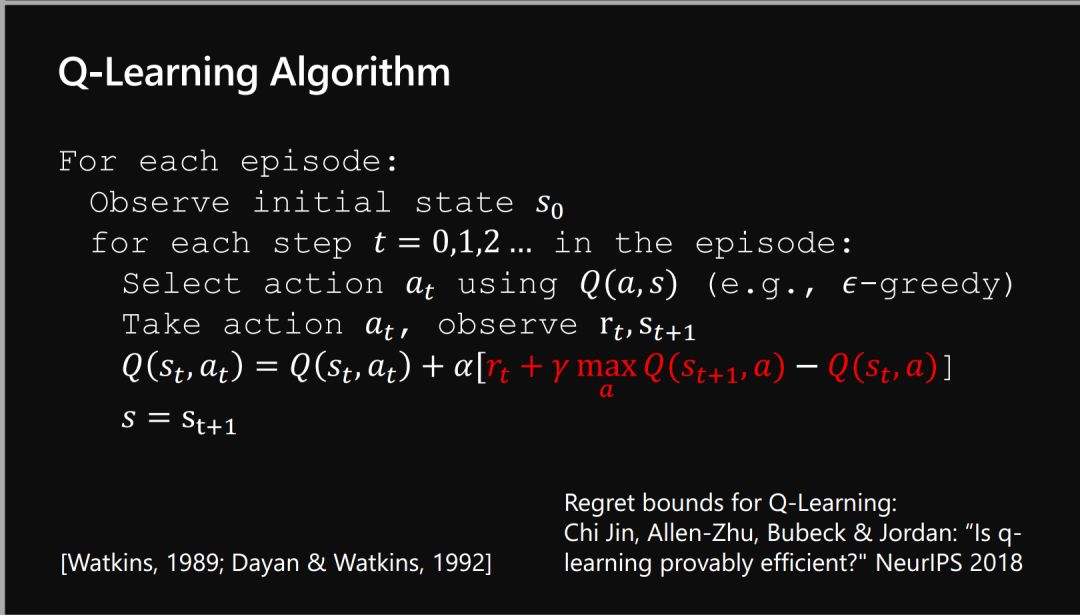
3
Function Approximation
函数近似


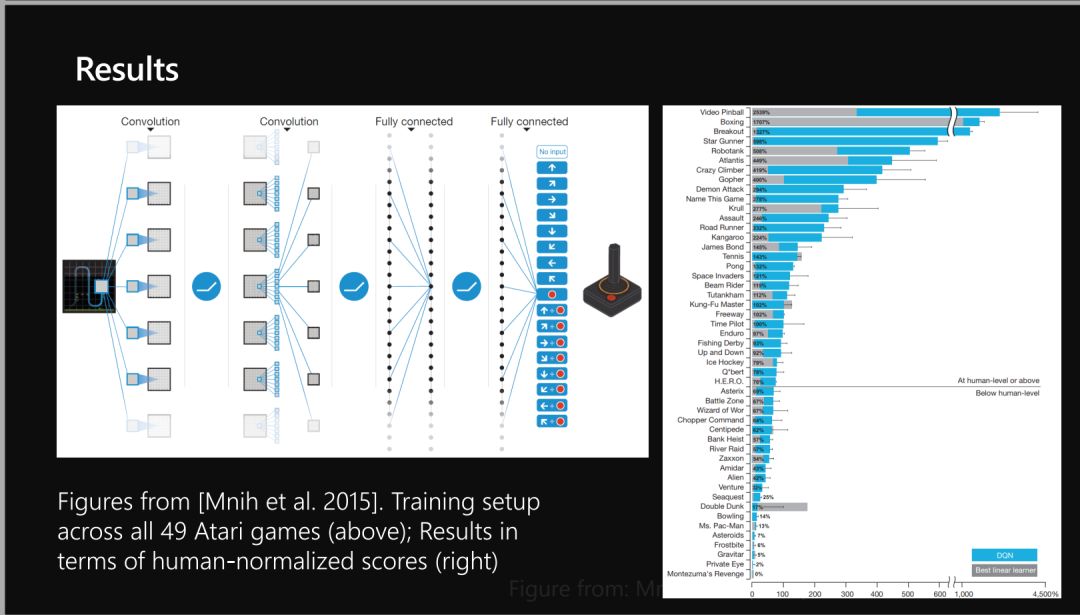

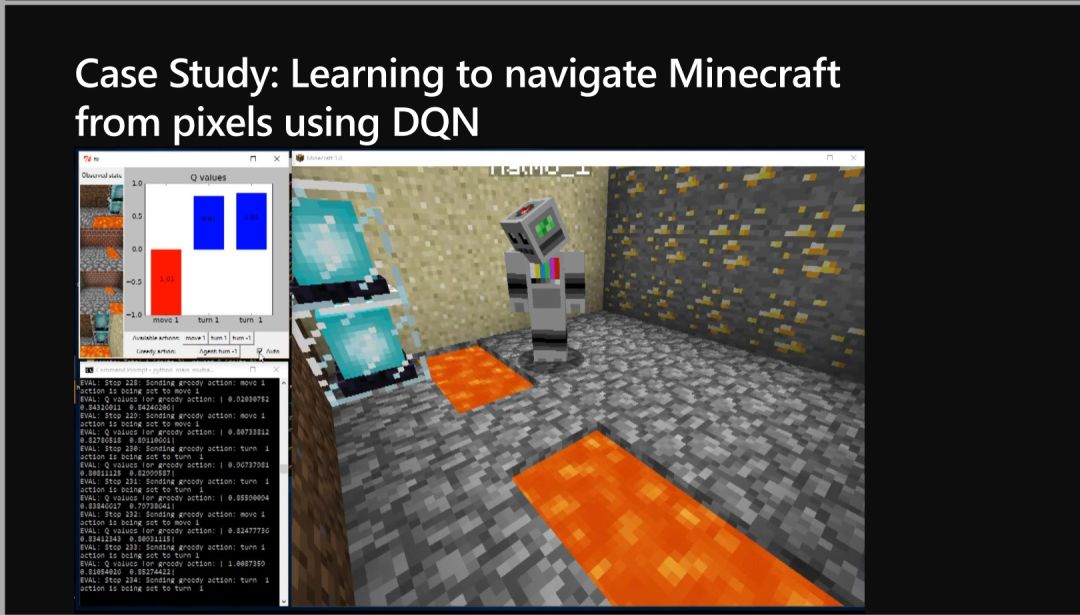

04
Exploration
探索



05
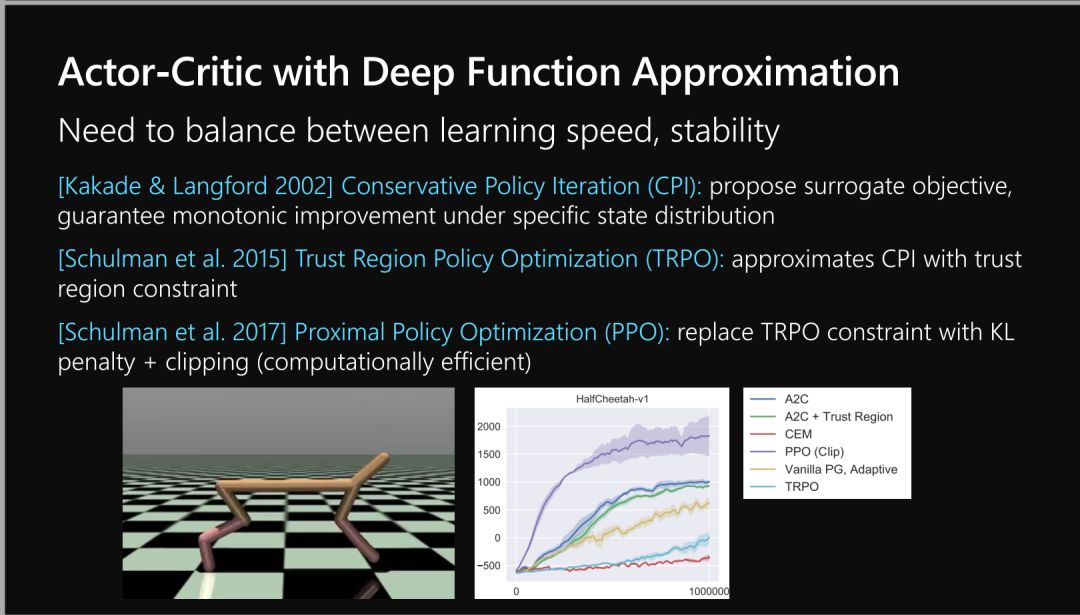
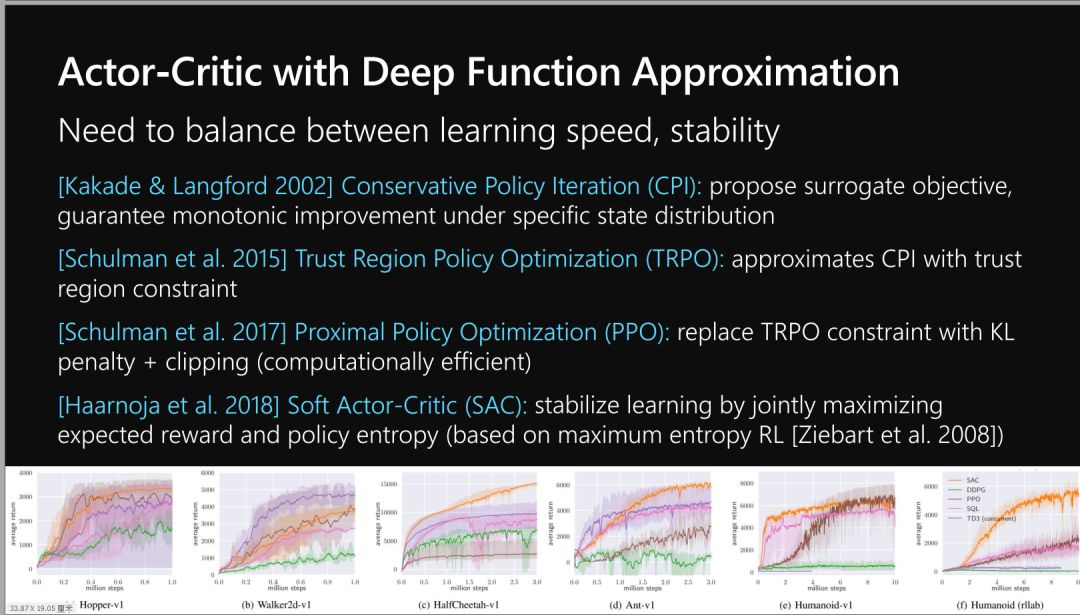
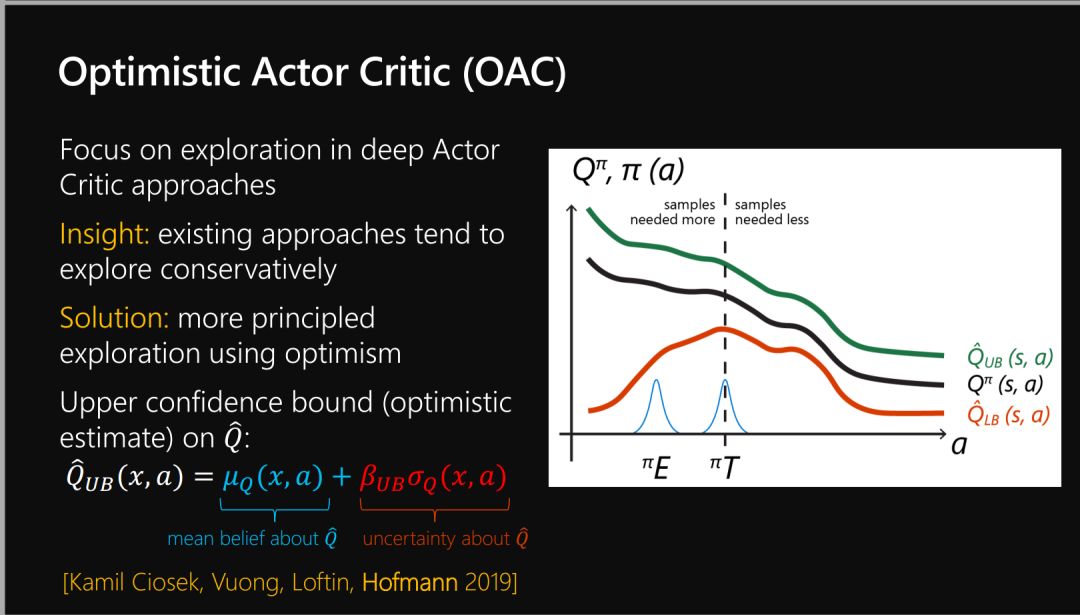
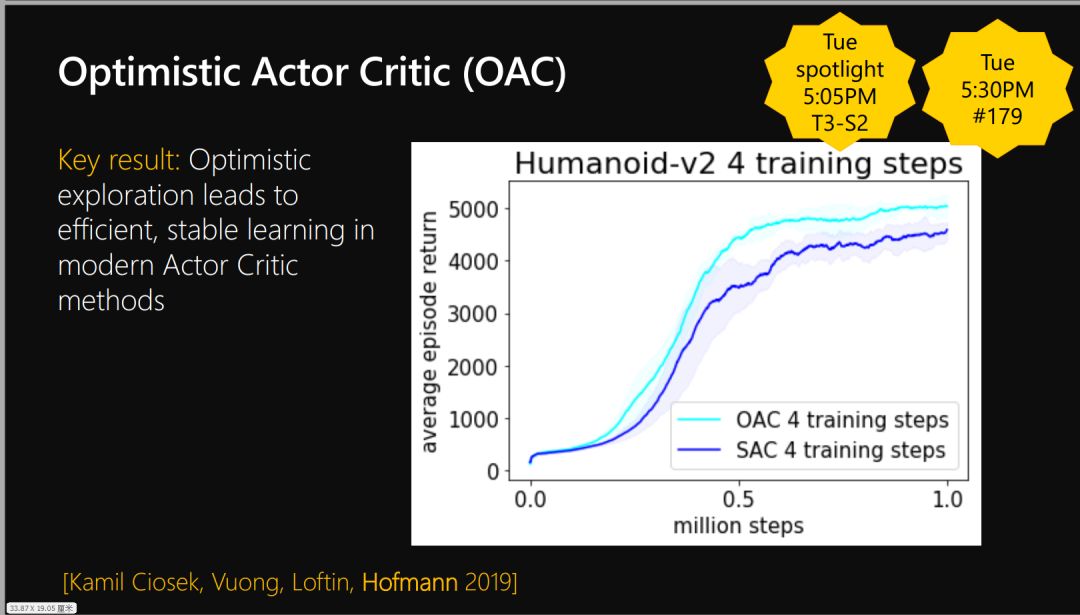
Policy Gradient and Actor Critic Approaches
策略梯度与Actor-Critic算法







-
后台回复“NIPS2019RL” 获取强化学习:过去、现在和未来展望97页ppt链接下载索引~



展开全文



