【论文推荐】最新六篇图像描述生成相关论文—视频摘要、注意力张量积、非自回归神经序列模型、副词识别、多主体、多样性度量
【导读】专知内容组整理了最近六篇图像描述生成(Image Caption)相关文章,为大家进行介绍,欢迎查看!
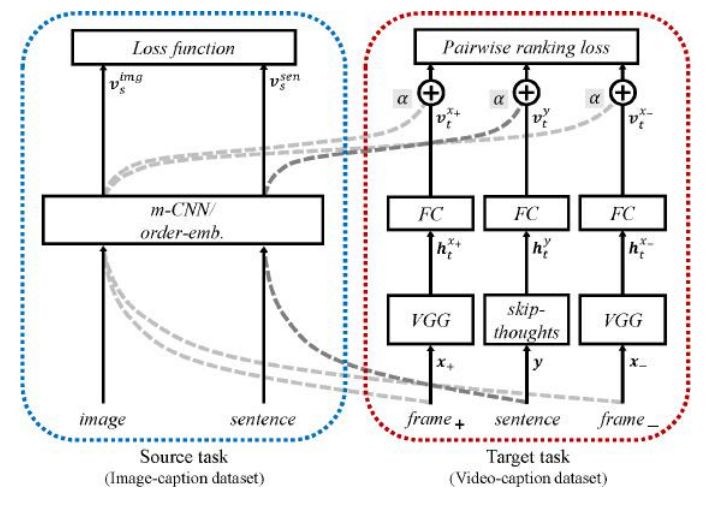
1. Textually Customized Video Summaries(文本定制的视频摘要)
作者:Jinsoo Choi,Tae-Hyun Oh,In So Kweon
摘要:The best summary of a long video differs among different people due to its highly subjective nature. Even for the same person, the best summary may change with time or mood. In this paper, we introduce the task of generating customized video summaries through simple text. First, we train a deep architecture to effectively learn semantic embeddings of video frames by leveraging the abundance of image-caption data via a progressive and residual manner. Given a user-specific text description, our algorithm is able to select semantically relevant video segments and produce a temporally aligned video summary. In order to evaluate our textually customized video summaries, we conduct experimental comparison with baseline methods that utilize ground-truth information. Despite the challenging baselines, our method still manages to show comparable or even exceeding performance. We also show that our method is able to generate semantically diverse video summaries by only utilizing the learned visual embeddings.
期刊:arXiv, 2018年3月1日
网址:
http://www.zhuanzhi.ai/document/e10fcf855c60c852471788e94930e82e
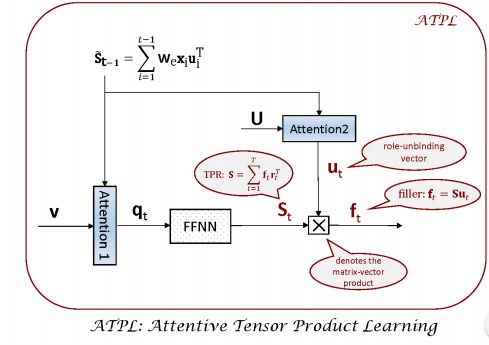
2. Attentive Tensor Product Learning for Language Generation and Grammar Parsing(用于语言生成和语法分析的注意力张量积学习)
作者:Qiuyuan Huang,Li Deng,Dapeng Wu,Chang Liu,Xiaodong He
摘要:This paper proposes a new architecture - Attentive Tensor Product Learning (ATPL) - to represent grammatical structures in deep learning models. ATPL is a new architecture to bridge this gap by exploiting Tensor Product Representations (TPR), a structured neural-symbolic model developed in cognitive science, aiming to integrate deep learning with explicit language structures and rules. The key ideas of ATPL are: 1) unsupervised learning of role-unbinding vectors of words via TPR-based deep neural network; 2) employing attention modules to compute TPR; and 3) integration of TPR with typical deep learning architectures including Long Short-Term Memory (LSTM) and Feedforward Neural Network (FFNN). The novelty of our approach lies in its ability to extract the grammatical structure of a sentence by using role-unbinding vectors, which are obtained in an unsupervised manner. This ATPL approach is applied to 1) image captioning, 2) part of speech (POS) tagging, and 3) constituency parsing of a sentence. Experimental results demonstrate the effectiveness of the proposed approach.
期刊:arXiv, 2018年2月20日
网址:
http://www.zhuanzhi.ai/document/af41409f92cee7d47727cb2ab6e68084
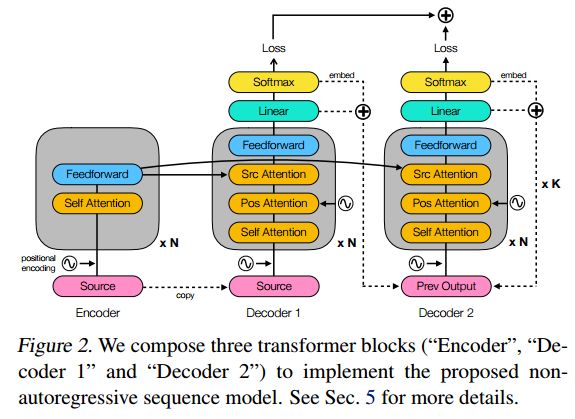
3. Deterministic Non-Autoregressive Neural Sequence Modeling by Iterative Refinement(确定性非自回归神经序列模型的迭代细化)
作者:Jason Lee,Elman Mansimov,Kyunghyun Cho
摘要:We propose a conditional non-autoregressive neural sequence model based on iterative refinement. The proposed model is designed based on the principles of latent variable models and denoising autoencoders, and is generally applicable to any sequence generation task. We extensively evaluate the proposed model on machine translation (En-De and En-Ro) and image caption generation, and observe that it significantly speeds up decoding while maintaining the generation quality comparable to the autoregressive counterpart.
期刊:arXiv, 2018年2月20日
网址:
http://www.zhuanzhi.ai/document/93dee75f9813df80fd2d57740f163e2c
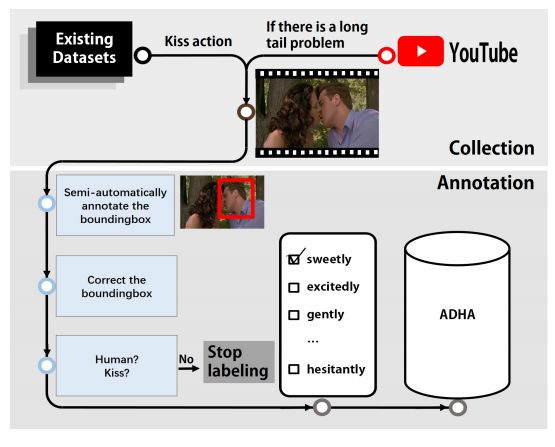
4. Human Action Adverb Recognition: ADHA Dataset and A Three-Stream Hybrid Model(人类活动副词识别:ADHA数据集和三支混合模型)
作者:Bo Pang,Kaiwen Zha,Cewu Lu
摘要:We introduce the first benchmark for a new problem --- recognizing human action adverbs (HAA): "Adverbs Describing Human Actions" (ADHA). This is the first step for computer vision to change over from pattern recognition to real AI. We demonstrate some key features of ADHA: a semantically complete set of adverbs describing human actions, a set of common, describable human actions, and an exhaustive labeling of simultaneously emerging actions in each video. We commit an in-depth analysis on the implementation of current effective models in action recognition and image captioning on adverb recognition, and the results show that such methods are unsatisfactory. Moreover, we propose a novel three-stream hybrid model to deal the HAA problem, which achieves a better result.
期刊:arXiv, 2018年2月12日
网址:
http://www.zhuanzhi.ai/document/dca649f3096e34837272ccc9c181a76e
5. Zero-Resource Neural Machine Translation with Multi-Agent Communication Game(多主体通信游戏的零资源神经机器翻译)
作者:Yun Chen,Yang Liu,Victor O. K. Li
摘要:While end-to-end neural machine translation (NMT) has achieved notable success in the past years in translating a handful of resource-rich language pairs, it still suffers from the data scarcity problem for low-resource language pairs and domains. To tackle this problem, we propose an interactive multimodal framework for zero-resource neural machine translation. Instead of being passively exposed to large amounts of parallel corpora, our learners (implemented as encoder-decoder architecture) engage in cooperative image description games, and thus develop their own image captioning or neural machine translation model from the need to communicate in order to succeed at the game. Experimental results on the IAPR-TC12 and Multi30K datasets show that the proposed learning mechanism significantly improves over the state-of-the-art methods.
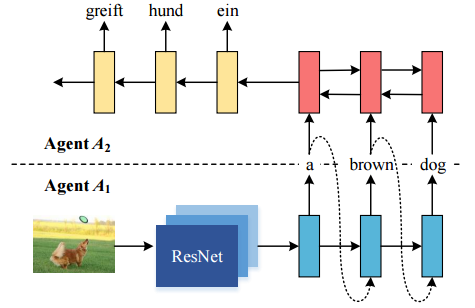
期刊:arXiv, 2018年2月9日
网址:
http://www.zhuanzhi.ai/document/f10ebdb5d4c5adccd3eed8d6a9b59574
6. Netizen-Style Commenting on Fashion Photos: Dataset and Diversity Measures(网民风格评论的时尚照片:数据集和多样性度量)
作者:Wen Hua Lin,Kuan-Ting Chen,Hung Yueh Chiang,Winston Hsu
摘要:Recently, deep neural network models have achieved promising results in image captioning task. Yet, "vanilla" sentences, only describing shallow appearances (e.g., types, colors), generated by current works are not satisfied netizen style resulting in lacking engagements, contexts, and user intentions. To tackle this problem, we propose Netizen Style Commenting (NSC), to automatically generate characteristic comments to a user-contributed fashion photo. We are devoted to modulating the comments in a vivid "netizen" style which reflects the culture in a designated social community and hopes to facilitate more engagement with users. In this work, we design a novel framework that consists of three major components: (1) We construct a large-scale clothing dataset named NetiLook, which contains 300K posts (photos) with 5M comments to discover netizen-style comments. (2) We propose three unique measures to estimate the diversity of comments. (3) We bring diversity by marrying topic models with neural networks to make up the insufficiency of conventional image captioning works. Experimenting over Flickr30k and our NetiLook datasets, we demonstrate our proposed approaches benefit fashion photo commenting and improve image captioning tasks both in accuracy and diversity.
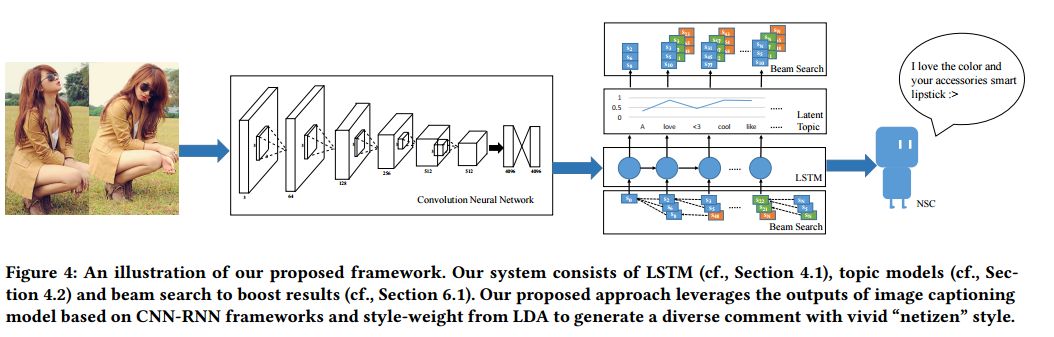
期刊:arXiv, 2018年1月31日
网址:
http://www.zhuanzhi.ai/document/697041024e601925400664781277e83f
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!
展开全文



