近期必读的7篇ICML 2019【Meta-Learning(元学习)】相关论文和代码
【导读】最近小编推出CVPR2019图卷积网络、CVPR2019生成对抗网络、【可解释性】,CVPR视觉目标跟踪,CVPR视觉问答,医学图像分割,图神经网络的推荐,CVPR域自适应, ICML图神经网络相关论文,反响热烈。最近,Meta-Learning(元学习)相关研究非常火热,这两年相关论文非常多,结合最新的热点方法,在应用到自己的领域,已经是大部分研究者快速出成果的一个必备方式。基于Meta-Learning(元学习)的工作在今年ICML 2019上出现了大量的论文,好多是些理论方法,希望CV、NLP、DM或者其他领域的同学多多学习,看能否结合,期待好的工作!今天小编专门整理最新七篇Meta-Learning(元学习)—在线元学习、元强化学习、元逆强化学习、层次结构元学习、小样本学习等。

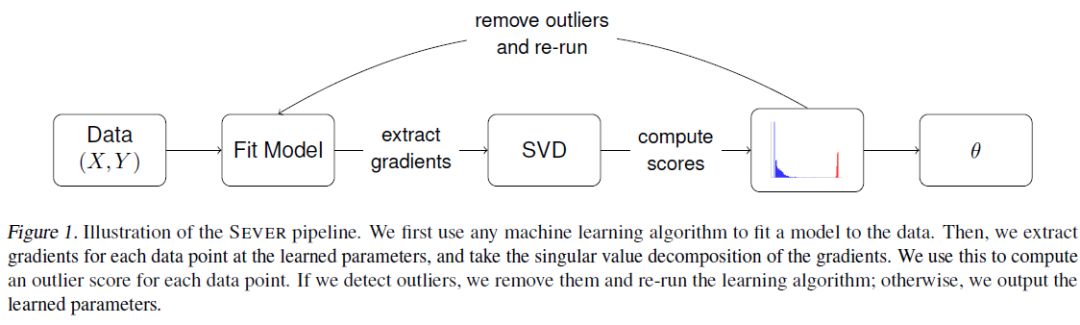
1、Sever: A Robust Meta-Algorithm for Stochastic Optimization(Sever:一种鲁棒的随机优化元算法)
ICML ’19
作者:Ilias Diakonikolas, Gautam Kamath, Daniel Kane, Jerry Li, Jacob Steinhardt, Alistair Stewart
摘要:在高维情况下,大多数机器学习方法对于哪怕是一小部分结构化异常值也是脆弱的。为了解决这一问题,我们引入了一种新的元算法,它可以接纳base learner,如最小二乘或随机梯度下降,并增强learner对异常值的抵抗力。我们的方法Sever具有强大的理论保证,但同时也具有很高的可伸缩性——除了运行base learner本身,它只需要计算某个n* d矩阵的顶部奇异向量。我们将服务器应用于药物设计数据集和垃圾邮件分类数据集,发现在这两种情况下,它都比几个baseline具有更强的鲁棒性。在垃圾邮件数据集上,有1%的损坏,我们实现了7.4%的test error, 相比之下,baseline的test error为13.4%-20.5%,未损坏数据集的test error为3%。同样,在药物设计数据集上,在10%的损坏情况下,我们获得了1.42的mean squared test error,而baseline为1.51-2.33,未损坏数据集为1.23的mean squared test error。
网址:
http://proceedings.mlr.press/v97/diakonikolas19a.html
代码链接:
https://github.com/hoonose/sever
2、Online Meta-Learning(在线元学习)
ICML ’19
作者:智能系统的一个核心能力是能够不断地利用以前的经验来加快和加强新任务的学习。两个不同的研究范式研究了这个问题。元学习将此问题视为学习优先于模型的参数,该参数可用于快速适应新任务,但通常假定任务作为批处理一起可用。相比之下,在线(regret based)学习考虑的是一个任务接一个任务地显示的环境,但传统上只训练一个模型,没有特定于任务的适应性。这项工作引入了一个在线元学习设置,它融合了两种范式的思想,以更好地捕捉持续终生学习的精神和实践。我们提出了follow the meta leader (FTML)算法,它将MAML算法扩展到这个设置。从理论上讲,这项工作提供了一个O(log T) regret guarantee,附加了一个高阶平滑度的假设(与标准的在线设置相比)。我们对三个不同的大规模问题的实验评估表明,该算法的性能显著优于传统在线学习方法。
网址:
http://proceedings.mlr.press/v97/finn19a.html
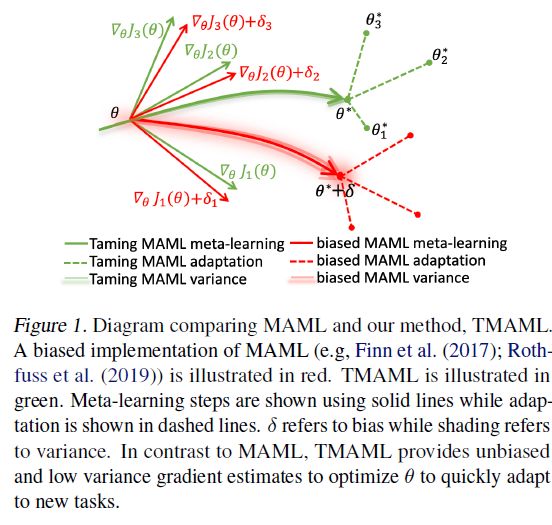
3、Taming MAML: Efficient unbiased meta-reinforcement learning(Taming MAML: 有效的无偏元强化学习)
ICML ’19
作者:Hao Liu, Richard Socher, Caiming Xiong
摘要:虽然元强化学习(meta-reinformation learning,meta-rl)方法取得了显著的成功,但如何获得正确的、低方差的policy梯度估计仍然是一个重大的挑战。特别是,估计一个大的Hessian,低样本效率和不稳定的训练继续使Meta-RL变得困难。我们提出了一个名为Taming MAML (TMAML)的替代目标函数,它通过自动微分将控制变量添加到梯度估计中。TMAML通过在不引入偏差的情况下减小方差,提高了梯度估计的质量。我们进一步提出了我们方法的一个版本,该版本将元学习框架扩展到学习控制变量本身,从而从MDPs的分布中实现高效和可伸缩的学习。我们将我们的方法与MAML和其他方差偏置权衡方法(包括DICE、LVC和action-dependent control variates)进行了经验性比较。我们的方法易于实现,并且在梯度估计的方差和精度方面优于现有的方法,最终在各种具有挑战性的Meta-RL环境中获得更高的性能。
网址:
http://proceedings.mlr.press/v97/liu19g.html
代码链接:
https://github.com/lhao499/taming-maml
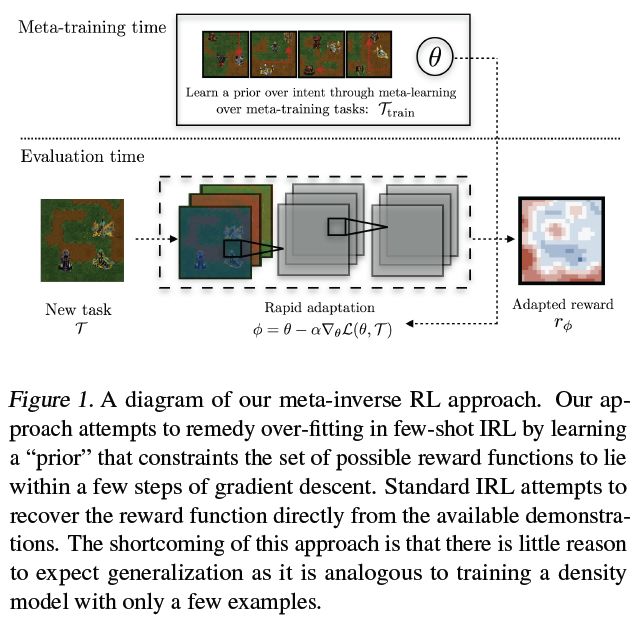
4、Learning a Prior over Intent via Meta-Inverse Reinforcement Learning(通过元逆强化学习学习先验过意图)
ICML ’19
作者:Kelvin Xu, Ellis Ratner, Anca Dragan, Sergey Levine, Chelsea Finn
摘要:将强化学习应用于实际问题的一个重大挑战是需要指定一个oracle奖励函数来正确定义任务。逆向强化学习(IRL)试图通过从专家论证中推断奖励函数来避免这一问题。虽然很吸引人,但是收集涵盖现实世界中常见变化的演示数据集(例如打开任何类型的门)可能会非常昂贵。因此,在实践中,IRL通常只能通过有限的一组演示来执行,而在这些演示中,要明确地恢复一个奖励函数是极其困难的。在这项工作中,我们利用了来自其他任务的演示可以用来约束一组可能的奖励函数这一观点,方法是学习一个“先验”,这个“先验”是专门为从有限的演示中推断表达性奖励函数的能力而优化的。我们证明了我们的方法可以有效地从新任务的图像中recover rewards,并提供关于我们的方法如何类似于学习先验的intuition。
网址:
http://proceedings.mlr.press/v97/xu19d.html
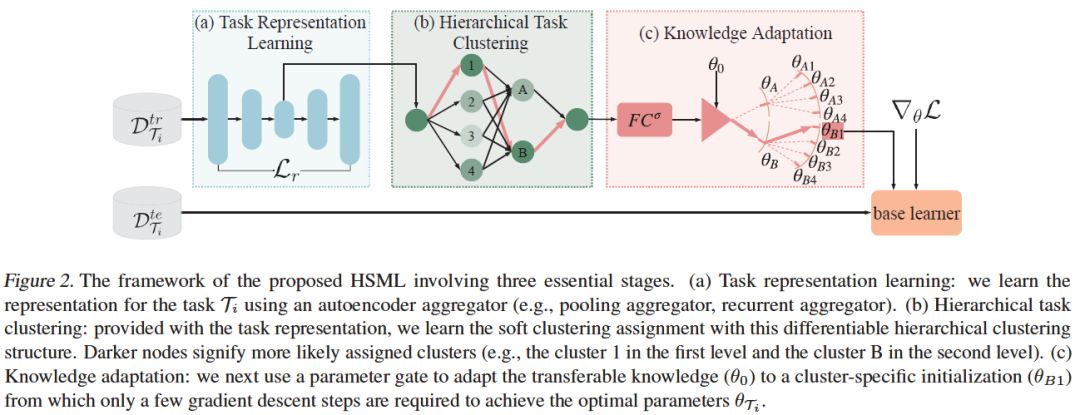
5、Hierarchically Structured Meta-learning(层次结构元学习)
ICML ’19
作者:Huaxiu Yao, Ying Wei, Junzhou Huang, Zhenhui Li
摘要:为了在较少样本的情况下快速学习,元学习利用了从以前任务中学到的先验知识。然而,元学习的一个关键挑战是任务的不确定性和异构性,这是无法通过任务之间的全局共享知识来处理的。在基于梯度元学习的基础上,我们提出了一种层次结构的元学习(HSML)算法。受人类组织知识的方式的启发,我们采用层次任务聚类结构对任务进行聚类。因此,该方法不仅通过对不同任务集群进行知识定制来解决这一问题,而且在相似任务集群之间保持了知识的泛化。为了解决任务关系的变化,我们还将层次结构扩展到连续学习环境中。实验结果表明,该方法在toy回归和少样本图像分类问题上均能取得较好的分类效果。
网址:
http://proceedings.mlr.press/v97/yao19b.html
代码链接:
https://github.com/huaxiuyao/HSML
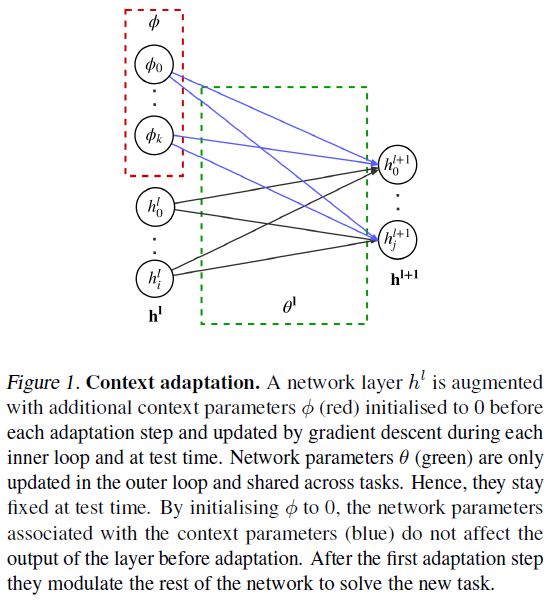
6、Fast Context Adaptation via Meta-Learning(通过元学习快速适应上下文)
ICML ’19
作者:Luisa Zintgraf, Kyriacos Shiarli, Vitaly Kurin, Katja Hofmann, Shimon Whiteson
摘要:我们提出使用CAVIA进行元学习,这是对MAML的一个简单扩展,它不太容易发生元过度拟合,更容易并行化,并且更具解释性。CAVIA将模型参数划分为两部分:上下文参数(作为模型的额外输入,适用于单独的任务)和共享参数(经过元训练并在任务之间共享)。在测试时,只更新上下文参数,从而导致低维任务表示。我们的经验表明,CAVIA在回归、分类和强化学习方面优于MAML。我们的实验还突出了当前benchmark的弱点,即在某些情况下所需的适应量很小。
网址:
http://proceedings.mlr.press/v97/zintgraf19a.html
代码链接:
https://github.com/lmzintgraf/cavia
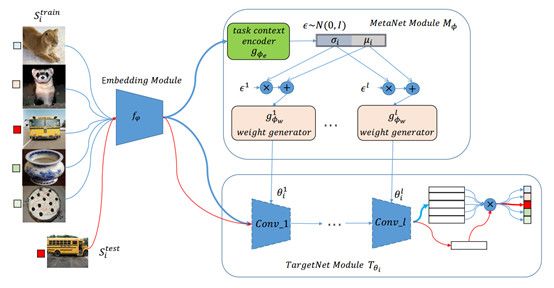
7、LGM-Net: Learning to Generate Matching Networks for Few-Shot Learning(针对小样本问题的学习生成匹配网络方法)
ICML ’19
作者:Huaiyu Li, Weiming Dong, Xing Mei, Chongyang Ma, Feiyue Huang, Bao-Gang Hu
摘要:目前,成功的深度神经网络往往依赖于大量训练数据和训练时间,当训练数据较少时,神经网络通常容易过拟合,这是由于传统的基于梯度的更新算法没有针对当前任务的先验知识,无法在神经网络的参数空间中找到具有较好泛化能力的参数点。当一个神经网络计算结构固定的时候,网络的参数权重决定了网络的功能,而具有较好泛化能力的参数点可以看作是一个基于训练数据的条件概率分布。根据这样的观察,我们针对小样本问题提出了一种基于训练数据直接生成具有较好泛化性网络参数的元学习方法,让神经网络在大量的任务中积累经验,自己学会如何解决小样本问题。
网址:
https://arxiv.org/abs/1905.06331
代码链接:
https://github.com/likesiwell/LGM-Net/
请关注专知公众号(点击上方蓝色专知关注)
后台回复“ICML2019METAL” 就可以获取《七篇论文》的下载链接~
-END-
专 · 知
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎登录www.zhuanzhi.ai,注册登录专知,获取更多AI知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程视频资料和与专家交流咨询!

请加专知小助手微信(扫一扫如下二维码添加),加入专知人工智能主题群,咨询技术商务合作~

专知《深度学习:算法到实战》课程全部完成!550+位同学在学习,现在报名,限时优惠!网易云课堂人工智能畅销榜首位!

点击“阅读原文”,了解报名专知《深度学习:算法到实战》课程
展开全文



